 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Extractive Dialogue Summarization in Hyperdimensional Space
May 16, 2024We present HyperSum, an extractive summarization framework that captures both the efficiency of traditional lexical summarization and the accuracy of contemporary neural approaches. HyperSum exploits the pseudo-orthogonality that emerges when randomly initializing vectors at extremely high dimensions ("blessing of dimensionality") to construct representative and efficient sentence embeddings. Simply clustering the obtained embeddings and extracting their medoids yields competitive summaries. HyperSum often outperforms state-of-the-art summarizers -- in terms of both summary accuracy and faithfulness -- while being 10 to 100 times faster. We open-source HyperSum as a strong baseline for unsupervised extractive summarization.
Unsupervised Dialogue Topic Segmentation in Hyperdimensional Space
Aug 21, 2023We present HyperSeg, a hyperdimensional computing (HDC) approach to unsupervised dialogue topic segmentation. HDC is a class of vector symbolic architectures that leverages the probabilistic orthogonality of randomly drawn vectors at extremely high dimensions (typically over 10,000). HDC generates rich token representations through its low-cost initialization of many unrelated vectors. This is especially beneficial in topic segmentation, which often operates as a resource-constrained pre-processing step for downstream transcript understanding tasks. HyperSeg outperforms the current state-of-the-art in 4 out of 5 segmentation benchmarks -- even when baselines are given partial access to the ground truth -- and is 10 times faster on average. We show that HyperSeg also improves downstream summarization accuracy. With HyperSeg, we demonstrate the viability of HDC in a major language task. We open-source HyperSeg to provide a strong baseline for unsupervised topic segmentation.
Leveraging Non-dialogue Summaries for Dialogue Summarization
Oct 17, 2022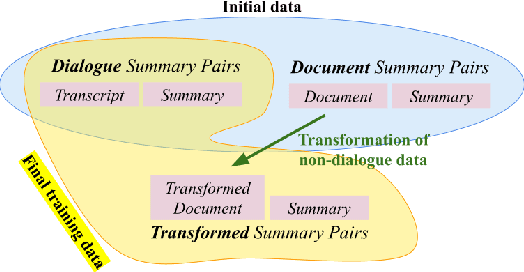
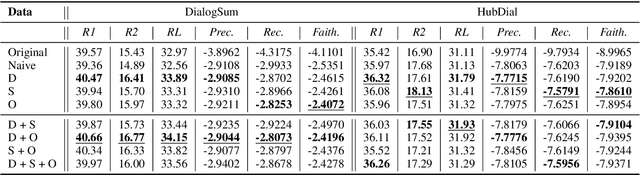
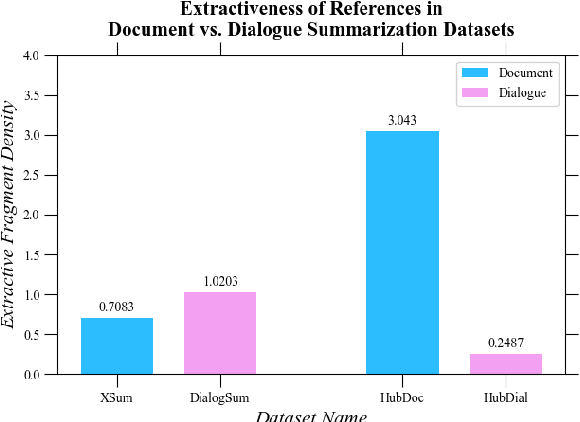
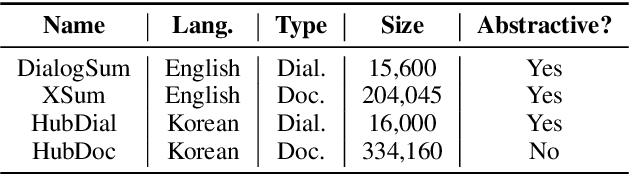
To mitigate the lack of diverse dialogue summarization datasets in academia, we present methods to utilize non-dialogue summarization data for enhancing dialogue summarization systems. We apply transformations to document summarization data pairs to create training data that better befit dialogue summarization. The suggested transformations also retain desirable properties of non-dialogue datasets, such as improved faithfulness to the source text. We conduct extensive experiments across both English and Korean to verify our approach. Although absolute gains in ROUGE naturally plateau as more dialogue summarization samples are introduced, utilizing non-dialogue data for training significantly improves summarization performance in zero- and few-shot settings and enhances faithfulness across all training regimes.
LIME: Weakly-Supervised Text Classification Without Seeds
Oct 13, 2022


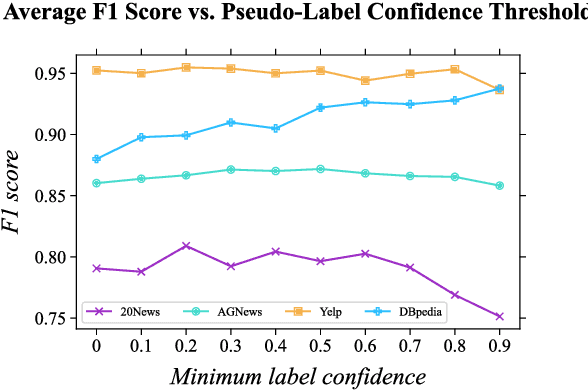
In weakly-supervised text classification, only label names act as sources of supervision. Predominant approaches to weakly-supervised text classification utilize a two-phase framework, where test samples are first assigned pseudo-labels and are then used to train a neural text classifier. In most previous work, the pseudo-labeling step is dependent on obtaining seed words that best capture the relevance of each class label. We present LIME, a framework for weakly-supervised text classification that entirely replaces the brittle seed-word generation process with entailment-based pseudo-classification. We find that combining weakly-supervised classification and textual entailment mitigates shortcomings of both, resulting in a more streamlined and effective classification pipeline. With just an off-the-shelf textual entailment model, LIME outperforms recent baselines in weakly-supervised text classification and achieves state-of-the-art in 4 benchmarks. We open source our code at https://github.com/seongminp/LIME.
Unsupervised Abstractive Dialogue Summarization with Word Graphs and POV Conversion
May 26, 2022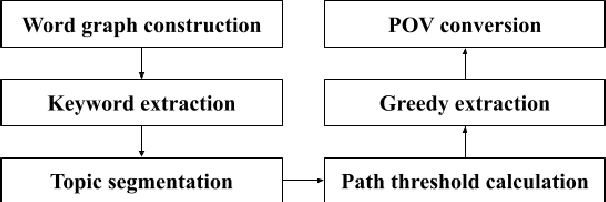



We advance the state-of-the-art in unsupervised abstractive dialogue summarization by utilizing multi-sentence compression graphs. Starting from well-founded assumptions about word graphs, we present simple but reliable path-reranking and topic segmentation schemes. Robustness of our method is demonstrated on datasets across multiple domains, including meetings, interviews, movie scripts, and day-to-day conversations. We also identify possible avenues to augment our heuristic-based system with deep learning. We open-source our code, to provide a strong, reproducible baseline for future research into unsupervised dialogue summarization.
Finetuning Pretrained Transformers into Variational Autoencoders
Aug 05, 2021


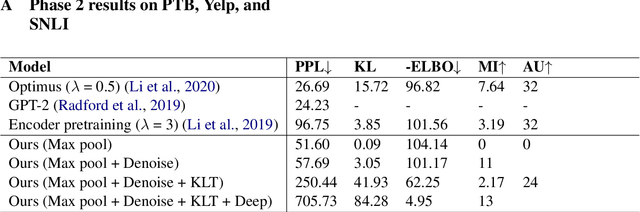
Text variational autoencoders (VAEs) are notorious for posterior collapse, a phenomenon where the model's decoder learns to ignore signals from the encoder. Because posterior collapse is known to be exacerbated by expressive decoders, Transformers have seen limited adoption as components of text VAEs. Existing studies that incorporate Transformers into text VAEs (Li et al., 2020; Fang et al., 2021) mitigate posterior collapse using massive pretraining, a technique unavailable to most of the research community without extensive computing resources. We present a simple two-phase training scheme to convert a sequence-to-sequence Transformer into a VAE with just finetuning. The resulting language model is competitive with massively pretrained Transformer-based VAEs in some internal metrics while falling short on others. To facilitate training we comprehensively explore the impact of common posterior collapse alleviation techniques in the literature. We release our code for reproducability.
Improving Distinction between ASR Errors and Speech Disfluencies with Feature Space Interpolation
Aug 04, 2021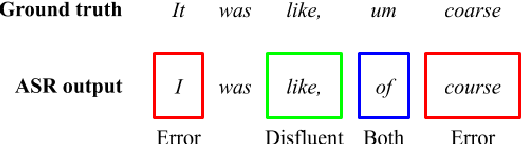
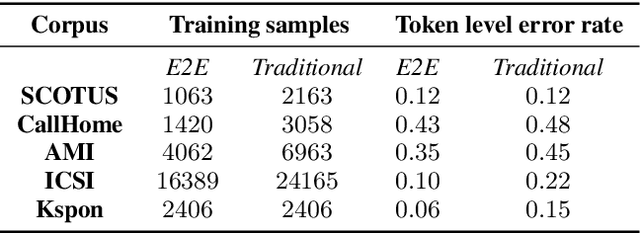
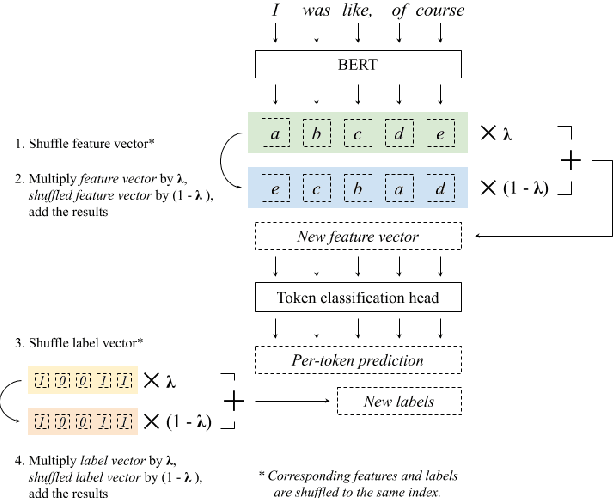
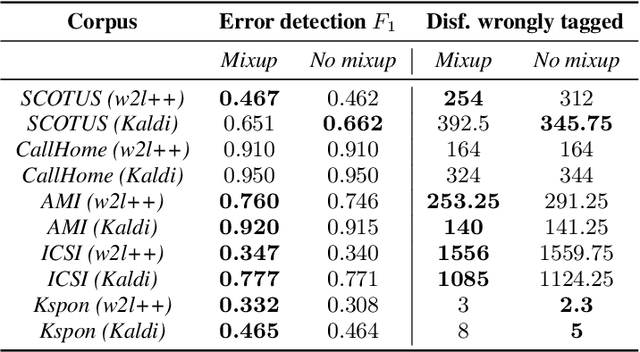
Fine-tuning pretrained language models (LMs) is a popular approach to automatic speech recognition (ASR) error detection during post-processing. While error detection systems often take advantage of statistical language archetypes captured by LMs, at times the pretrained knowledge can hinder error detection performance. For instance, presence of speech disfluencies might confuse the post-processing system into tagging disfluent but accurate transcriptions as ASR errors. Such confusion occurs because both error detection and disfluency detection tasks attempt to identify tokens at statistically unlikely positions. This paper proposes a scheme to improve existing LM-based ASR error detection systems, both in terms of detection scores and resilience to such distracting auxiliary tasks. Our approach adopts the popular mixup method in text feature space and can be utilized with any black-box ASR output. To demonstrate the effectiveness of our method, we conduct post-processing experiments with both traditional and end-to-end ASR systems (both for English and Korean languages) with 5 different speech corpora. We find that our method improves both ASR error detection F 1 scores and reduces the number of correctly transcribed disfluencies wrongly detected as ASR errors. Finally, we suggest methods to utilize resulting LMs directly in semi-supervised ASR training.