 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Shape-Based Functional Index for Objective Assessment of Pediatric Motor Function
Jan 02, 2025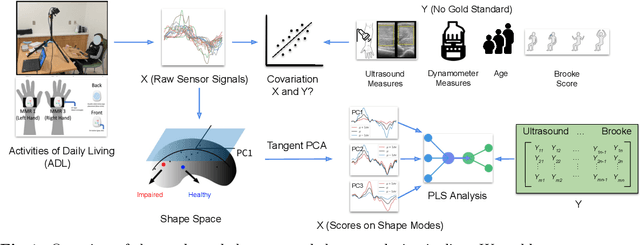

Clinical assessments for neuromuscular disorders, such as Spinal Muscular Atrophy (SMA) and Duchenne Muscular Dystrophy (DMD), continue to rely on subjective measures to monitor treatment response and disease progression. We introduce a novel method using wearable sensors to objectively assess motor function during daily activities in 19 patients with DMD, 9 with SMA, and 13 age-matched controls. Pediatric movement data is complex due to confounding factors such as limb length variations in growing children and variability in movement speed. Our approach uses Shape-based Principal Component Analysis to align movement trajectories and identify distinct kinematic patterns, including variations in motion speed and asymmetry. Both DMD and SMA cohorts have individuals with motor function on par with healthy controls. Notably, patients with SMA showed greater activation of the motion asymmetry pattern. We further combined projections on these principal components with partial least squares (PLS) to identify a covariation mode with a canonical correlation of r = 0.78 (95% CI: [0.34, 0.94]) with muscle fat infiltration, the Brooke score (a motor function score), and age-related degenerative changes, proposing a novel motor function index. This data-driven method can be deployed in home settings, enabling better longitudinal tracking of treatment efficacy for children with neuromuscular disorders.
Shape Analysis for Pediatric Upper Body Motor Function Assessment
Sep 10, 2022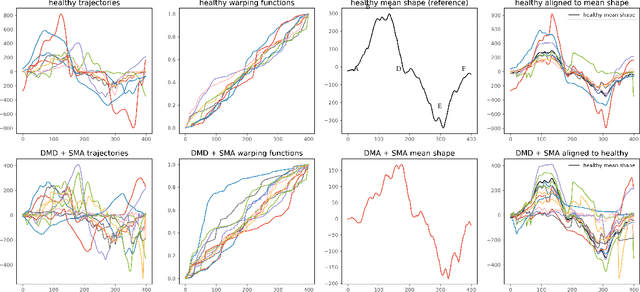



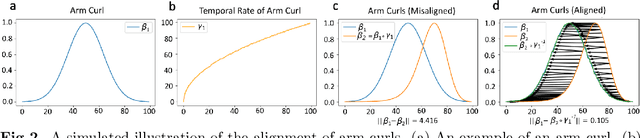
Neuromuscular disorders, such as Spinal Muscular Atrophy (SMA) and Duchenne Muscular Dystrophy (DMD), cause progressive muscular degeneration and loss of motor function for 1 in 6,000 children. Traditional upper limb motor function assessments do not quantitatively measure patient-performed motions, which makes it difficult to track progress for incremental changes. Assessing motor function in children with neuromuscular disorders is particularly challenging because they can be nervous or excited during experiments, or simply be too young to follow precise instructions. These challenges translate to confounding factors such as performing different parts of the arm curl slower or faster (phase variability) which affects the assessed motion quality. This paper uses curve registration and shape analysis to temporally align trajectories while simultaneously extracting a mean reference shape. Distances from this mean shape are used to assess the quality of motion. The proposed metric is invariant to confounding factors, such as phase variability, while suggesting several clinically relevant insights. First, there are statistically significant differences between functional scores for the control and patient populations (p$=$0.0213$\le$0.05). Next, several patients in the patient cohort are able to perform motion on par with the healthy cohort and vice versa. Our metric, which is computed based on wearables, is related to the Brooke's score ((p$=$0.00063$\le$0.05)), as well as motor function assessments based on dynamometry ((p$=$0.0006$\le$0.05)). These results show promise towards ubiquitous motion quality assessment in daily life.
Geometry matters: Exploring language examples at the decision boundary
Oct 14, 2020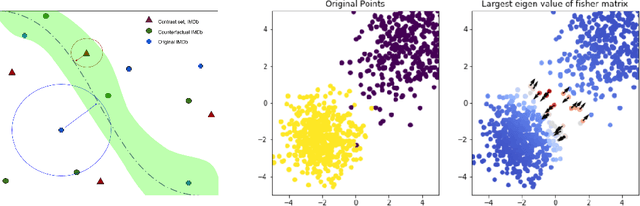


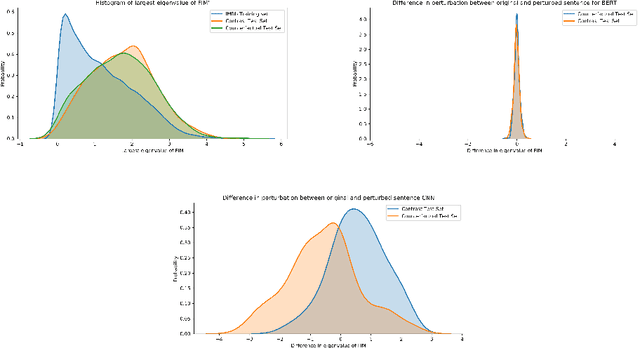
A growing body of recent evidence has highlighted the limitations of natural language processing (NLP) datasets and classifiers. These include the presence of annotation artifacts in datasets, classifiers relying on shallow features like a single word (e.g., if a movie review has the word "romantic", the review tends to be positive), or unnecessary words (e.g., learning a proper noun to classify a movie as positive or negative). The presence of such artifacts has subsequently led to the development of challenging datasets to force the model to generalize better. While a variety of heuristic strategies, such as counterfactual examples and contrast sets, have been proposed, the theoretical justification about what makes these examples difficult is often lacking or unclear. In this paper, using tools from information geometry, we propose a theoretical way to quantify the difficulty of an example in NLP. Using our approach, we explore difficult examples for two popular NLP architectures. We discover that both BERT and CNN are susceptible to single word substitutions in high difficulty examples. Consequently, examples with low difficulty scores tend to be robust to multiple word substitutions. Our analysis shows that perturbations like contrast sets and counterfactual examples are not necessarily difficult for the model, and they may not be accomplishing the intended goal. Our approach is simple, architecture agnostic, and easily extendable to other datasets. All the code used will be made publicly available, including a tool to explore the difficult examples for other datasets.