 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhenotype-preserving metric design for high-content image reconstruction by generative inpainting
Aug 01, 2023In the past decades, automated high-content microscopy demonstrated its ability to deliver large quantities of image-based data powering the versatility of phenotypic drug screening and systems biology applications. However, as the sizes of image-based datasets grew, it became infeasible for humans to control, avoid and overcome the presence of imaging and sample preparation artefacts in the images. While novel techniques like machine learning and deep learning may address these shortcomings through generative image inpainting, when applied to sensitive research data this may come at the cost of undesired image manipulation. Undesired manipulation may be caused by phenomena such as neural hallucinations, to which some artificial neural networks are prone. To address this, here we evaluate the state-of-the-art inpainting methods for image restoration in a high-content fluorescence microscopy dataset of cultured cells with labelled nuclei. We show that architectures like DeepFill V2 and Edge Connect can faithfully restore microscopy images upon fine-tuning with relatively little data. Our results demonstrate that the area of the region to be restored is of higher importance than shape. Furthermore, to control for the quality of restoration, we propose a novel phenotype-preserving metric design strategy. In this strategy, the size and count of the restored biological phenotypes like cell nuclei are quantified to penalise undesirable manipulation. We argue that the design principles of our approach may also generalise to other applications.
Singularity: Planet-Scale, Preemptive and Elastic Scheduling of AI Workloads
Feb 21, 2022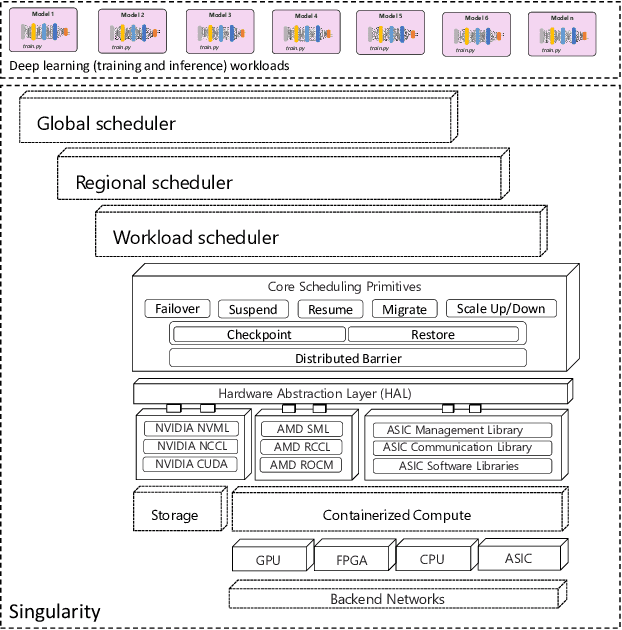
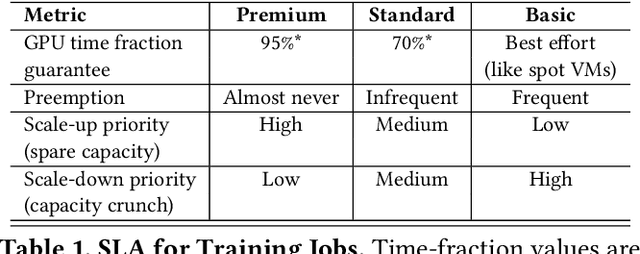
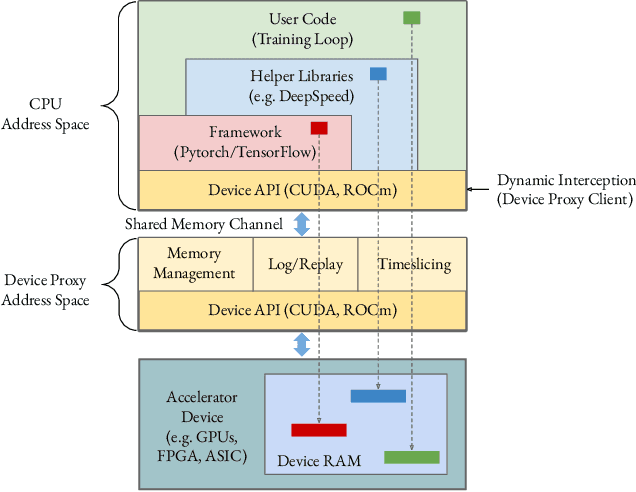
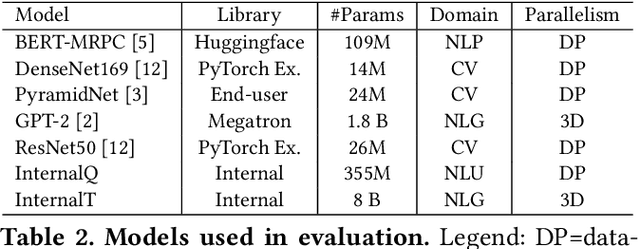
Lowering costs by driving high utilization across deep learning workloads is a crucial lever for cloud providers. We present Singularity, Microsoft's globally distributed scheduling service for highly-efficient and reliable execution of deep learning training and inference workloads. At the heart of Singularity is a novel, workload-aware scheduler that can transparently preempt and elastically scale deep learning workloads to drive high utilization without impacting their correctness or performance, across a global fleet of AI accelerators (e.g., GPUs, FPGAs). All jobs in Singularity are preemptable, migratable, and dynamically resizable (elastic) by default: a live job can be dynamically and transparently (a) preempted and migrated to a different set of nodes, cluster, data center or a region and resumed exactly from the point where the execution was preempted, and (b) resized (i.e., elastically scaled-up/down) on a varying set of accelerators of a given type. Our mechanisms are transparent in that they do not require the user to make any changes to their code or require using any custom libraries that may limit flexibility. Additionally, our approach significantly improves the reliability of deep learning workloads. We show that the resulting efficiency and reliability gains with Singularity are achieved with negligible impact on the steady-state performance. Finally, our design approach is agnostic of DNN architectures and handles a variety of parallelism strategies (e.g., data/pipeline/model parallelism).
Dialogue-based simulation for cultural awareness training
Feb 01, 2020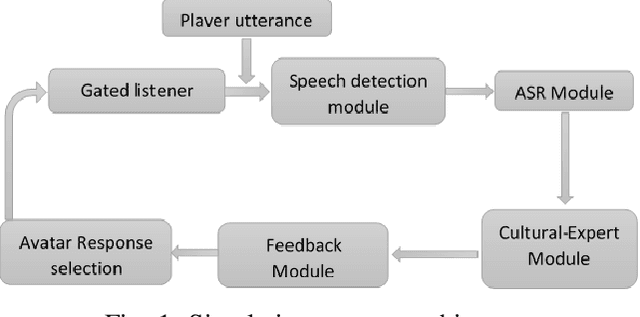

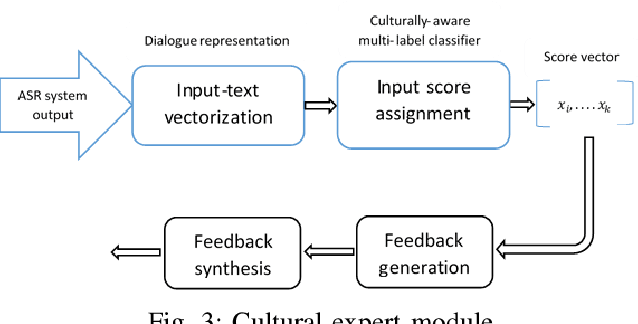

Existing simulations designed for cultural and interpersonal skill training rely on pre-defined responses with a menu option selection interface. Using a multiple-choice interface and restricting trainees' responses may limit the trainees' ability to apply the lessons in real life situations. This systems also uses a simplistic evaluation model, where trainees' selected options are marked as either correct or incorrect. This model may not capture sufficient information that could drive an adaptive feedback mechanism to improve trainees' cultural awareness. This paper describes the design of a dialogue-based simulation for cultural awareness training. The simulation, built around a disaster management scenario involving a joint coalition between the US and the Chinese armies. Trainees were able to engage in realistic dialogue with the Chinese agent. Their responses, at different points, get evaluated by different multi-label classification models. Based on training on our dataset, the models score the trainees' responses for cultural awareness in the Chinese culture. Trainees also get feedback that informs the cultural appropriateness of their responses. The result of this work showed the following; i) A feature-based evaluation model improves the design, modeling and computation of dialogue-based training simulation systems; ii) Output from current automatic speech recognition (ASR) systems gave comparable end results compared with the output from manual transcription; iii) A multi-label classification model trained as a cultural expert gave results which were comparable with scores assigned by human annotators.
Input Prioritization for Testing Neural Networks
Jan 11, 2019
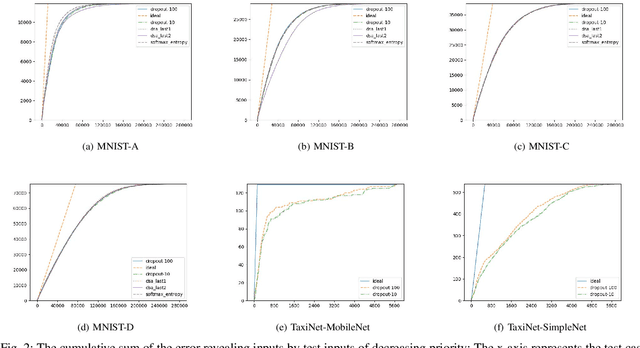


Deep neural networks (DNNs) are increasingly being adopted for sensing and control functions in a variety of safety and mission-critical systems such as self-driving cars, autonomous air vehicles, medical diagnostics, and industrial robotics. Failures of such systems can lead to loss of life or property, which necessitates stringent verification and validation for providing high assurance. Though formal verification approaches are being investigated, testing remains the primary technique for assessing the dependability of such systems. Due to the nature of the tasks handled by DNNs, the cost of obtaining test oracle data---the expected output, a.k.a. label, for a given input---is high, which significantly impacts the amount and quality of testing that can be performed. Thus, prioritizing input data for testing DNNs in meaningful ways to reduce the cost of labeling can go a long way in increasing testing efficacy. This paper proposes using gauges of the DNN's sentiment derived from the computation performed by the model, as a means to identify inputs that are likely to reveal weaknesses. We empirically assessed the efficacy of three such sentiment measures for prioritization---confidence, uncertainty, and surprise---and compare their effectiveness in terms of their fault-revealing capability and retraining effectiveness. The results indicate that sentiment measures can effectively flag inputs that expose unacceptable DNN behavior. For MNIST models, the average percentage of inputs correctly flagged ranged from 88% to 94.8%.