 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInput Prioritization for Testing Neural Networks
Paper and Code
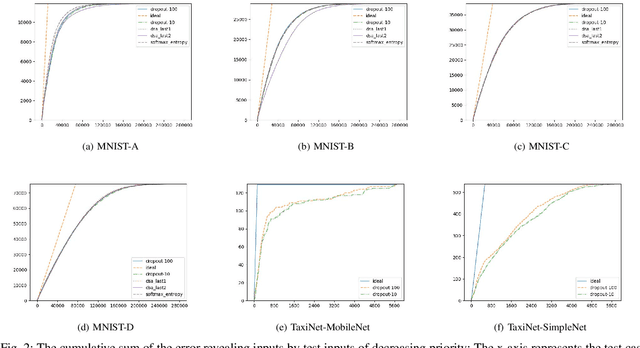


Deep neural networks (DNNs) are increasingly being adopted for sensing and control functions in a variety of safety and mission-critical systems such as self-driving cars, autonomous air vehicles, medical diagnostics, and industrial robotics. Failures of such systems can lead to loss of life or property, which necessitates stringent verification and validation for providing high assurance. Though formal verification approaches are being investigated, testing remains the primary technique for assessing the dependability of such systems. Due to the nature of the tasks handled by DNNs, the cost of obtaining test oracle data---the expected output, a.k.a. label, for a given input---is high, which significantly impacts the amount and quality of testing that can be performed. Thus, prioritizing input data for testing DNNs in meaningful ways to reduce the cost of labeling can go a long way in increasing testing efficacy. This paper proposes using gauges of the DNN's sentiment derived from the computation performed by the model, as a means to identify inputs that are likely to reveal weaknesses. We empirically assessed the efficacy of three such sentiment measures for prioritization---confidence, uncertainty, and surprise---and compare their effectiveness in terms of their fault-revealing capability and retraining effectiveness. The results indicate that sentiment measures can effectively flag inputs that expose unacceptable DNN behavior. For MNIST models, the average percentage of inputs correctly flagged ranged from 88% to 94.8%.