 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-42: Enabling Determinism in LLM Inference with Verified Speculation
Jan 25, 2026In LLM inference, the same prompt may yield different outputs across different runs. At the system level, this non-determinism arises from floating-point non-associativity combined with dynamic batching and GPU kernels whose reduction orders vary with batch size. A straightforward way to eliminate non-determinism is to disable dynamic batching during inference, but doing so severely degrades throughput. Another approach is to make kernels batch-invariant; however, this tightly couples determinism to kernel design, requiring new implementations. This coupling also imposes fixed runtime overheads, regardless of how much of the workload actually requires determinism. Inspired by ideas from speculative decoding, we present LLM-42, a scheduling-based approach to enable determinism in LLM inference. Our key observation is that if a sequence is in a consistent state, the next emitted token is likely to be consistent even with dynamic batching. Moreover, most GPU kernels use shape-consistent reductions. Leveraging these insights, LLM-42 decodes tokens using a non-deterministic fast path and enforces determinism via a lightweight verify-rollback loop. The verifier replays candidate tokens under a fixed-shape reduction schedule, commits those that are guaranteed to be consistent across runs, and rolls back those violating determinism. LLM-42 mostly re-uses existing kernels unchanged and incurs overhead only in proportion to the traffic that requires determinism.
Kascade: A Practical Sparse Attention Method for Long-Context LLM Inference
Dec 18, 2025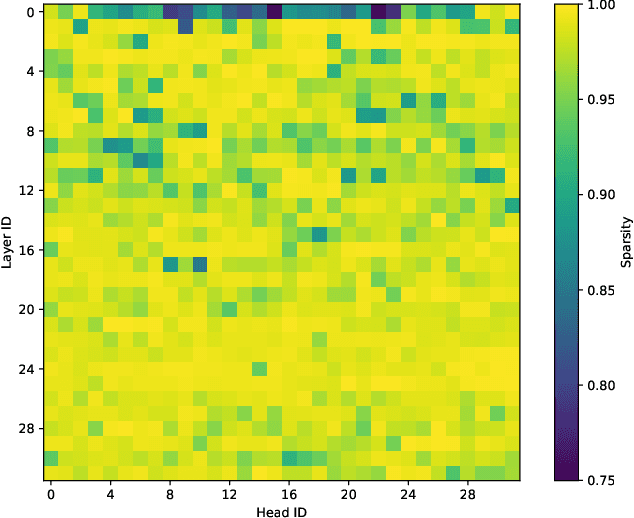



Attention is the dominant source of latency during long-context LLM inference, an increasingly popular workload with reasoning models and RAG. We propose Kascade, a training-free sparse attention method that leverages known observations such as 1) post-softmax attention is intrinsically sparse, and 2) the identity of high-weight keys is stable across nearby layers. Kascade computes exact Top-k indices in a small set of anchor layers, then reuses those indices in intermediate reuse layers. The anchor layers are selected algorithmically, via a dynamic-programming objective that maximizes cross-layer similarity over a development set, allowing easy deployment across models. The method incorporates efficient implementation constraints (e.g. tile-level operations), across both prefill and decode attention. The Top-k selection and reuse in Kascade is head-aware and we show in our experiments that this is critical for high accuracy. Kascade achieves up to 4.1x speedup in decode attention and 2.2x speedup in prefill attention over FlashAttention-3 baseline on H100 GPUs while closely matching dense attention accuracy on long-context benchmarks such as LongBench and AIME-24.
TokenWeave: Efficient Compute-Communication Overlap for Distributed LLM Inference
May 16, 2025Distributed inference of large language models (LLMs) can introduce overheads of up to 20% even over GPUs connected via high-speed interconnects such as NVLINK. Multiple techniques have been proposed to mitigate these overheads by decomposing computations into finer-grained tasks and overlapping communication with sub-tasks as they complete. However, fine-grained decomposition of a large computation into many smaller computations on GPUs results in overheads. Further, the communication itself uses many streaming multiprocessors (SMs), adding to the overhead. We present TokenWeave to address these challenges. TokenWeave proposes a Token-Splitting technique that divides the tokens in the inference batch into two approximately equal subsets in a wave-aware manner. The computation of one subset is then overlapped with the communication of the other. In addition, TokenWeave optimizes the order of the layer normalization computation with respect to communication operations and implements a novel fused AllReduce-RMSNorm kernel carefully leveraging Multimem instruction support available on NVIDIA Hopper GPUs. These optimizations allow TokenWeave to perform communication and RMSNorm using only 2-8 SMs. Moreover, our kernel enables the memory bound RMSNorm to be overlapped with the other batch's computation, providing additional gains. Our evaluations demonstrate up to 29% latency gains and up to 26% throughput gains across multiple models and workloads. In several settings, TokenWeave results in better performance compared to an equivalent model with all communication removed.
Niyama : Breaking the Silos of LLM Inference Serving
Mar 28, 2025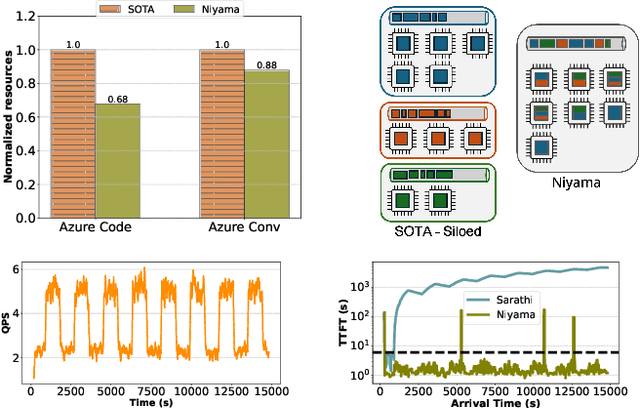



The widespread adoption of Large Language Models (LLMs) has enabled diverse applications with very different latency requirements. Existing LLM serving frameworks rely on siloed infrastructure with coarse-grained workload segregation -- interactive and batch -- leading to inefficient resource utilization and limited support for fine-grained Quality-of-Service (QoS) differentiation. This results in operational inefficiencies, over-provisioning and poor load management during traffic surges. We present Niyama, a novel QoS-driven inference serving system that enables efficient co-scheduling of diverse workloads on shared infrastructure. Niyama introduces fine-grained QoS classification allowing applications to specify precise latency requirements, and dynamically adapts scheduling decisions based on real-time system state. Leveraging the predictable execution characteristics of LLM inference, Niyama implements a dynamic chunking mechanism to improve overall throughput while maintaining strict QoS guarantees. Additionally, Niyama employs a hybrid prioritization policy that balances fairness and efficiency, and employs selective request relegation that enables graceful service degradation during overload conditions. Our evaluation demonstrates that Niyama increases serving capacity by 32% compared to current siloed deployments, while maintaining QoS guarantees. Notably, under extreme load, our system reduces SLO violations by an order of magnitude compared to current strategies.
Towards Efficient Large Multimodal Model Serving
Feb 02, 2025Recent advances in generative AI have led to large multi-modal models (LMMs) capable of simultaneously processing inputs of various modalities such as text, images, video, and audio. While these models demonstrate impressive capabilities, efficiently serving them in production environments poses significant challenges due to their complex architectures and heterogeneous resource requirements. We present the first comprehensive systems analysis of two prominent LMM architectures, decoder-only and cross-attention, on six representative open-source models. We investigate their multi-stage inference pipelines and resource utilization patterns that lead to unique systems design implications. We also present an in-depth analysis of production LMM inference traces, uncovering unique workload characteristics, including variable, heavy-tailed request distributions, diverse modal combinations, and bursty traffic patterns. Our key findings reveal that different LMM inference stages exhibit highly heterogeneous performance characteristics and resource demands, while concurrent requests across modalities lead to significant performance interference. To address these challenges, we propose a decoupled serving architecture that enables independent resource allocation and adaptive scaling for each stage. We further propose optimizations such as stage colocation to maximize throughput and resource utilization while meeting the latency objectives.
POD-Attention: Unlocking Full Prefill-Decode Overlap for Faster LLM Inference
Oct 23, 2024Each request in LLM inference goes through two phases: compute-bound prefill and memory-bandwidth-bound decode. To improve GPU utilization, recent systems use hybrid batching that combines the prefill and decode phases of different requests into the same batch. Hybrid batching works well for linear operations as it amortizes the cost of loading model weights from HBM. However, attention computation in hybrid batches remains inefficient because existing attention kernels are optimized for either prefill or decode. In this paper, we present POD-Attention -- the first GPU kernel that efficiently computes attention for hybrid batches. POD-Attention aims to maximize the utilization of both compute and memory bandwidth by carefully allocating the GPU's resources such that prefill and decode operations happen concurrently on the same multiprocessor. We integrate POD-Attention in a state-of-the-art LLM inference scheduler Sarathi-Serve. POD-Attention speeds up attention computation by up to 75% (mean 28%) and increases LLM serving throughput by up to 22% in offline inference. In online inference, POD-Attention enables lower time-to-first-token (TTFT), time-between-tokens (TBT), and request execution latency versus Sarathi-Serve.
ASTRA: Accurate and Scalable ANNS-based Training of Extreme Classifiers
Sep 30, 2024`Extreme Classification'' (or XC) is the task of annotating data points (queries) with relevant labels (documents), from an extremely large set of $L$ possible labels, arising in search and recommendations. The most successful deep learning paradigm that has emerged over the last decade or so for XC is to embed the queries (and labels) using a deep encoder (e.g. DistilBERT), and use linear classifiers on top of the query embeddings. This architecture is of appeal because it enables millisecond-time inference using approximate nearest neighbor search (ANNS). The key question is how do we design training algorithms that are accurate as well as scale to $O(100M)$ labels on a limited number of GPUs. State-of-the-art XC techniques that demonstrate high accuracies (e.g., DEXML, Ren\'ee, DEXA) on standard datasets have per-epoch training time that scales as $O(L)$ or employ expensive negative sampling strategies, which are prohibitive in XC scenarios. In this work, we develop an accurate and scalable XC algorithm ASTRA with two key observations: (a) building ANNS index on the classifier vectors and retrieving hard negatives using the classifiers aligns the negative sampling strategy to the loss function optimized; (b) keeping the ANNS indices current as the classifiers change through the epochs is prohibitively expensive while using stale negatives (refreshed periodically) results in poor accuracy; to remedy this, we propose a negative sampling strategy that uses a mixture of importance sampling and uniform sampling. By extensive evaluation on standard XC as well as proprietary datasets with 120M labels, we demonstrate that ASTRA achieves SOTA precision, while reducing training time by 4x-15x relative to the second best.
Mnemosyne: Parallelization Strategies for Efficiently Serving Multi-Million Context Length LLM Inference Requests Without Approximations
Sep 25, 2024
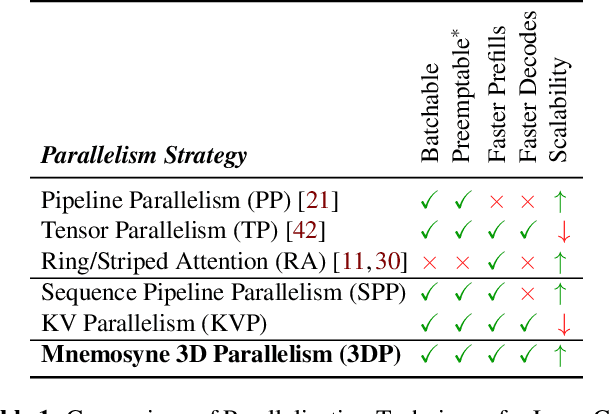
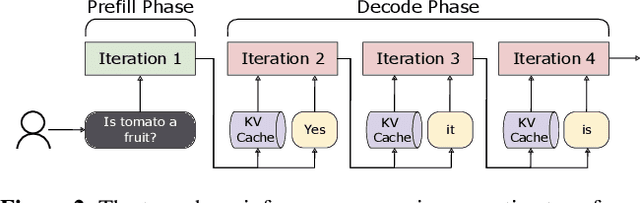
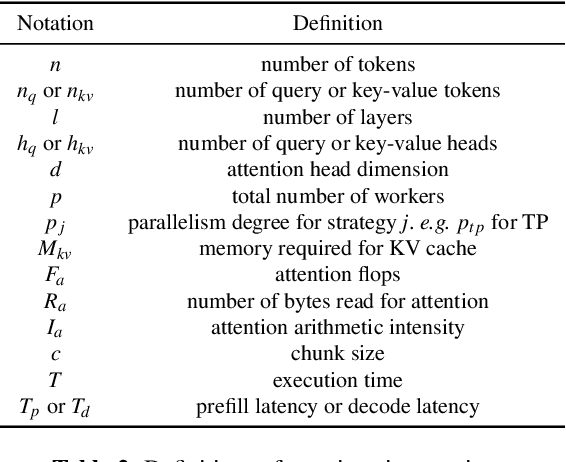
As large language models (LLMs) evolve to handle increasingly longer contexts, serving inference requests for context lengths in the range of millions of tokens presents unique challenges. While existing techniques are effective for training, they fail to address the unique challenges of inference, such as varying prefill and decode phases and their associated latency constraints - like Time to First Token (TTFT) and Time Between Tokens (TBT). Furthermore, there are no long context inference solutions that allow batching requests to increase the hardware utilization today. In this paper, we propose three key innovations for efficient interactive long context LLM inference, without resorting to any approximation: adaptive chunking to reduce prefill overheads in mixed batching, Sequence Pipeline Parallelism (SPP) to lower TTFT, and KV Cache Parallelism (KVP) to minimize TBT. These contributions are combined into a 3D parallelism strategy, enabling Mnemosyne to scale interactive inference to context lengths at least up to 10 million tokens with high throughput enabled with batching. To our knowledge, Mnemosyne is the first to be able to achieve support for 10 million long context inference efficiently, while satisfying production-grade SLOs on TBT (30ms) on contexts up to and including 10 million.
Accuracy is Not All You Need
Jul 12, 2024



When Large Language Models (LLMs) are compressed using techniques such as quantization, the predominant way to demonstrate the validity of such techniques is by measuring the model's accuracy on various benchmarks.If the accuracies of the baseline model and the compressed model are close, it is assumed that there was negligible degradation in quality.However, even when the accuracy of baseline and compressed model are similar, we observe the phenomenon of flips, wherein answers change from correct to incorrect and vice versa in proportion.We conduct a detailed study of metrics across multiple compression techniques, models and datasets, demonstrating that the behavior of compressed models as visible to end-users is often significantly different from the baseline model, even when accuracy is similar.We further evaluate compressed models qualitatively and quantitatively using MT-Bench and show that compressed models are significantly worse than baseline models in this free-form generative task.Thus, we argue that compression techniques should also be evaluated using distance metrics.We propose two such metrics, KL-Divergence and flips, and show that they are well correlated.
Metron: Holistic Performance Evaluation Framework for LLM Inference Systems
Jul 09, 2024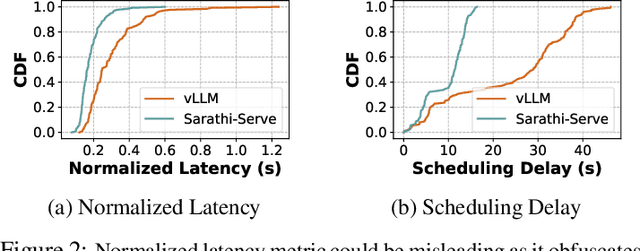
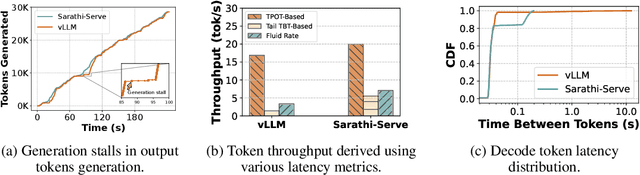
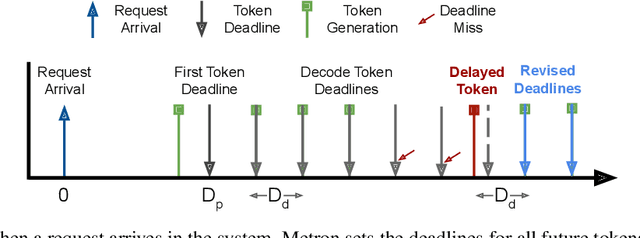
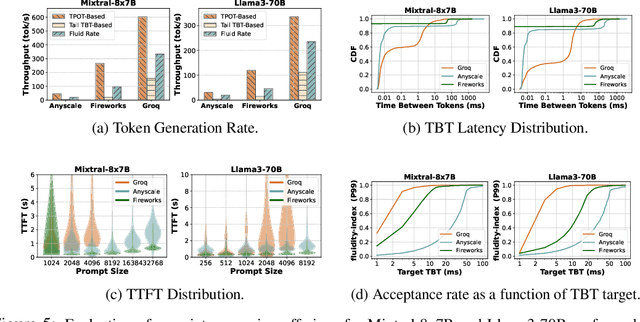
Serving large language models (LLMs) in production can incur substantial costs, which has prompted recent advances in inference system optimizations. Today, these systems are evaluated against conventional latency and throughput metrics (eg. TTFT, TBT, Normalised Latency and TPOT). However, these metrics fail to fully capture the nuances of LLM inference, leading to an incomplete assessment of user-facing performance crucial for real-time applications such as chat and translation. In this paper, we first identify the pitfalls of current performance metrics in evaluating LLM inference systems. We then propose Metron, a comprehensive performance evaluation framework that includes fluidity-index -- a novel metric designed to reflect the intricacies of the LLM inference process and its impact on real-time user experience. Finally, we evaluate various existing open-source platforms and model-as-a-service offerings using Metron, discussing their strengths and weaknesses. Metron is available at https://github.com/project-metron/metron.