 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSangam: Efficiently Serving Diffusion LLMs with the AR Stack
Jul 05, 2026Diffusion language models (dLLMs) generate text by iteratively denoising a masked response and can commit multiple output positions per model invocation. Their bidirectional attention prevents exact autoregressive-style KV caching, since committing one position shifts the KV activations of all others. Approximate caching techniques such as Fast-dLLM and dKV-Cache refresh KV activations repeatedly and reuse them across intervening decodes, inducing a repeated prefill/decode structure. This makes AR serving mechanisms relevant to dLLMs, but not directly applicable. dLLM decodes are block-sized rather than token-sized, prefills recur, and bidirectional attention precludes the chunked prefill mechanism used for stall-free colocated serving. We present Sangam, a serving system for cached dLLM inference. Sangam introduces a deficit token-budget scheduler that admits in-flight decodes first, admits whole indivisible prefills only when the accumulated token budget allows, and carries unused budget forward. This achieves amortized stall-free scheduling. Disaggregated serving avoids prefill-decode interference but suffers from prefill/decode resource partitioning problem. Sangam adopts a hybrid serving strategy, overflowing prefills onto decode workers to relieve prefill under-provisioning, and uses the same deficit-budget scheduler to protect those workers' decodes from the overflow. We show that like AR serving, dLLM serving design space is governed by prefill-decode interference and prefill/decode partitioning. Colocated serving is most effective on decode-heavy workloads, cutting mean latency by 9-20% over hybrid execution on LLaDA-8B ShareGPT; while hybrid execution is most effective on prefill-heavy workloads, cutting mean latency by 8-20% over colocated execution on Dream-7B arXiv. Sangam is available at https://github.com/UT-InfraAI/sangam.
Metron: Holistic Performance Evaluation Framework for LLM Inference Systems
Jul 09, 2024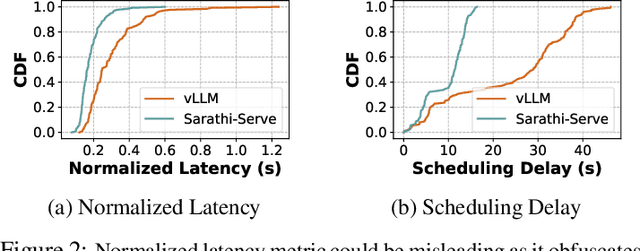
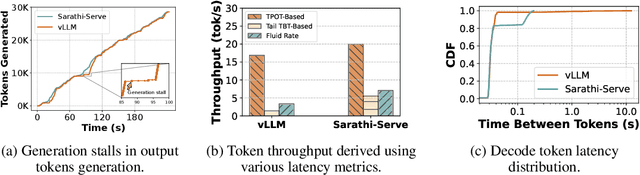
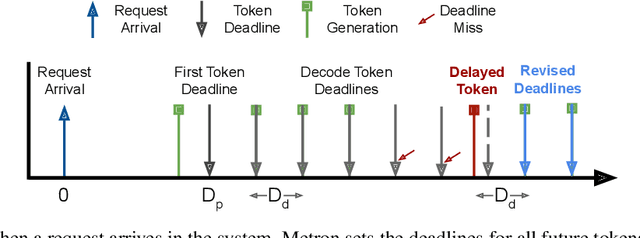
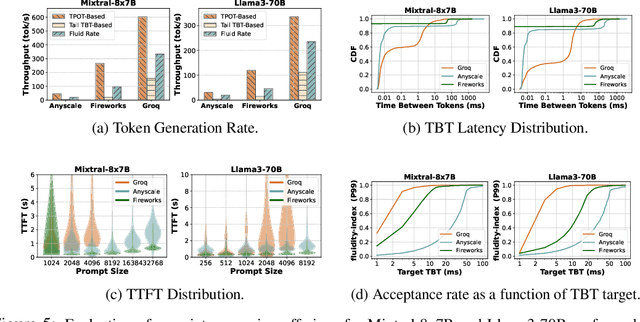
Serving large language models (LLMs) in production can incur substantial costs, which has prompted recent advances in inference system optimizations. Today, these systems are evaluated against conventional latency and throughput metrics (eg. TTFT, TBT, Normalised Latency and TPOT). However, these metrics fail to fully capture the nuances of LLM inference, leading to an incomplete assessment of user-facing performance crucial for real-time applications such as chat and translation. In this paper, we first identify the pitfalls of current performance metrics in evaluating LLM inference systems. We then propose Metron, a comprehensive performance evaluation framework that includes fluidity-index -- a novel metric designed to reflect the intricacies of the LLM inference process and its impact on real-time user experience. Finally, we evaluate various existing open-source platforms and model-as-a-service offerings using Metron, discussing their strengths and weaknesses. Metron is available at https://github.com/project-metron/metron.
Vidur: A Large-Scale Simulation Framework For LLM Inference
May 08, 2024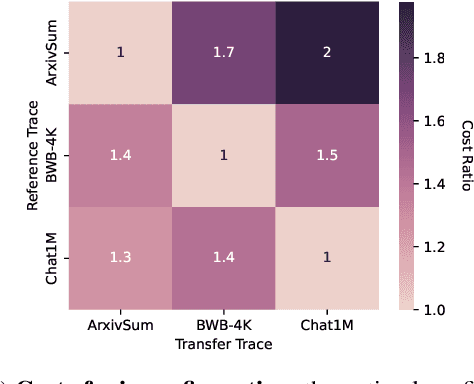

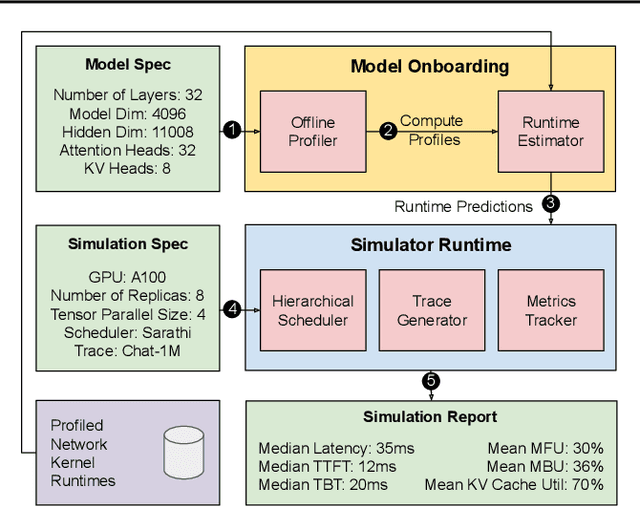
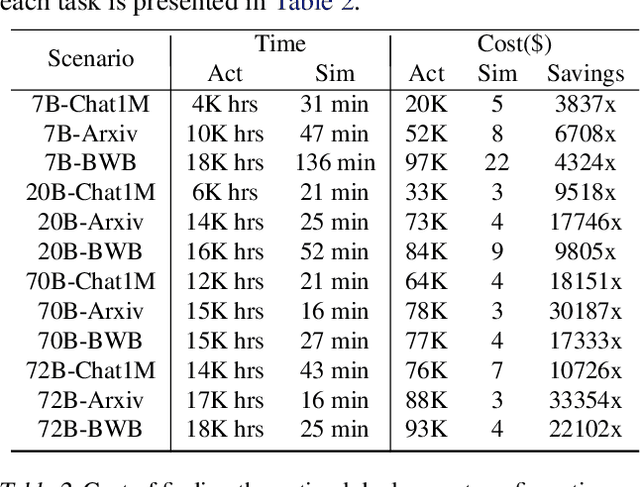
Optimizing the deployment of Large language models (LLMs) is expensive today since it requires experimentally running an application workload against an LLM implementation while exploring large configuration space formed by system knobs such as parallelization strategies, batching techniques, and scheduling policies. To address this challenge, we present Vidur - a large-scale, high-fidelity, easily-extensible simulation framework for LLM inference performance. Vidur models the performance of LLM operators using a combination of experimental profiling and predictive modeling, and evaluates the end-to-end inference performance for different workloads by estimating several metrics of interest such as latency and throughput. We validate the fidelity of Vidur on several LLMs and show that it estimates inference latency with less than 9% error across the range. Further, we present Vidur-Search, a configuration search tool that helps optimize LLM deployment. Vidur-Search uses Vidur to automatically identify the most cost-effective deployment configuration that meets application performance constraints. For example, Vidur-Search finds the best deployment configuration for LLaMA2-70B in one hour on a CPU machine, in contrast to a deployment-based exploration which would require 42K GPU hours - costing ~218K dollars. Source code for Vidur is available at https://github.com/microsoft/vidur.
Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve
Mar 04, 2024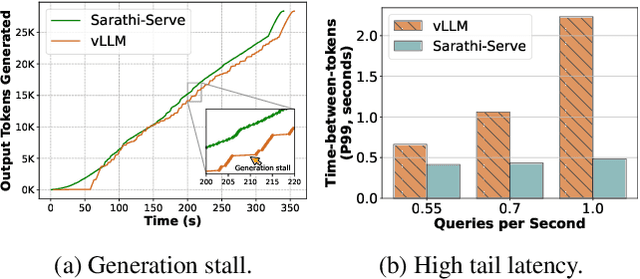

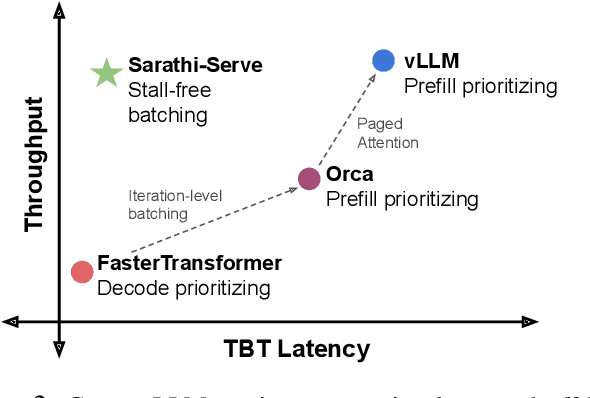

Each LLM serving request goes through two phases. The first is prefill which processes the entire input prompt to produce one output token and the second is decode which generates the rest of output tokens, one-at-a-time. Prefill iterations have high latency but saturate GPU compute due to parallel processing of the input prompt. In contrast, decode iterations have low latency but also low compute utilization because a decode iteration processes only a single token per request. This makes batching highly effective for decodes and consequently for overall throughput. However, batching multiple requests leads to an interleaving of prefill and decode iterations which makes it challenging to achieve both high throughput and low latency. We introduce an efficient LLM inference scheduler Sarathi-Serve inspired by the techniques we originally proposed for optimizing throughput in Sarathi. Sarathi-Serve leverages chunked-prefills from Sarathi to create stall-free schedules that can add new requests in a batch without pausing ongoing decodes. Stall-free scheduling unlocks the opportunity to improve throughput with large batch sizes while minimizing the effect of batching on latency. Our evaluation shows that Sarathi-Serve improves serving throughput within desired latency SLOs of Mistral-7B by up to 2.6x on a single A100 GPU and up to 6.9x for Falcon-180B on 8 A100 GPUs over Orca and vLLM.