 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve
Mar 04, 2024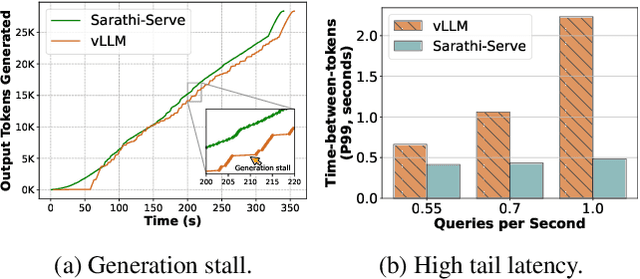

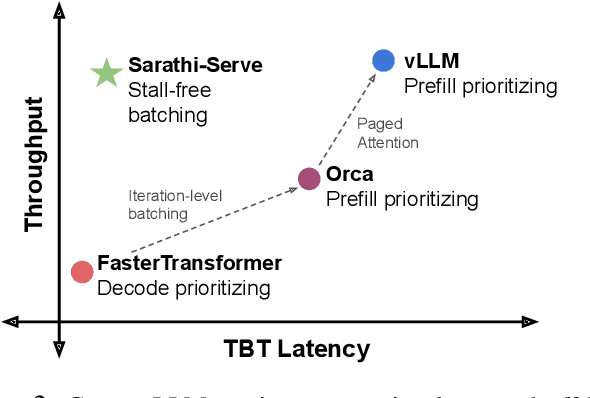

Each LLM serving request goes through two phases. The first is prefill which processes the entire input prompt to produce one output token and the second is decode which generates the rest of output tokens, one-at-a-time. Prefill iterations have high latency but saturate GPU compute due to parallel processing of the input prompt. In contrast, decode iterations have low latency but also low compute utilization because a decode iteration processes only a single token per request. This makes batching highly effective for decodes and consequently for overall throughput. However, batching multiple requests leads to an interleaving of prefill and decode iterations which makes it challenging to achieve both high throughput and low latency. We introduce an efficient LLM inference scheduler Sarathi-Serve inspired by the techniques we originally proposed for optimizing throughput in Sarathi. Sarathi-Serve leverages chunked-prefills from Sarathi to create stall-free schedules that can add new requests in a batch without pausing ongoing decodes. Stall-free scheduling unlocks the opportunity to improve throughput with large batch sizes while minimizing the effect of batching on latency. Our evaluation shows that Sarathi-Serve improves serving throughput within desired latency SLOs of Mistral-7B by up to 2.6x on a single A100 GPU and up to 6.9x for Falcon-180B on 8 A100 GPUs over Orca and vLLM.
SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills
Aug 31, 2023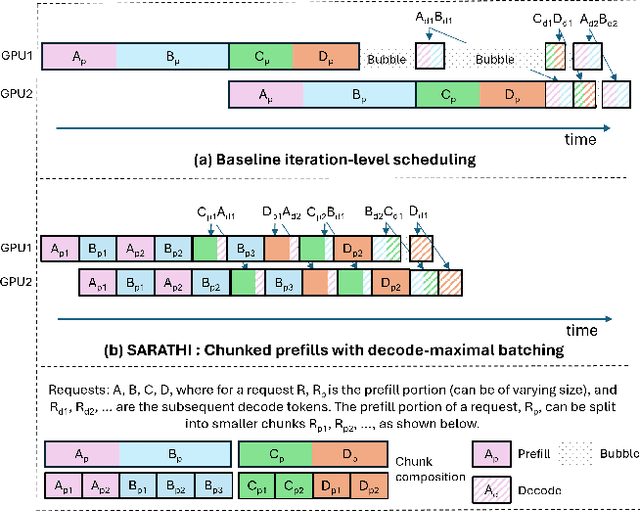
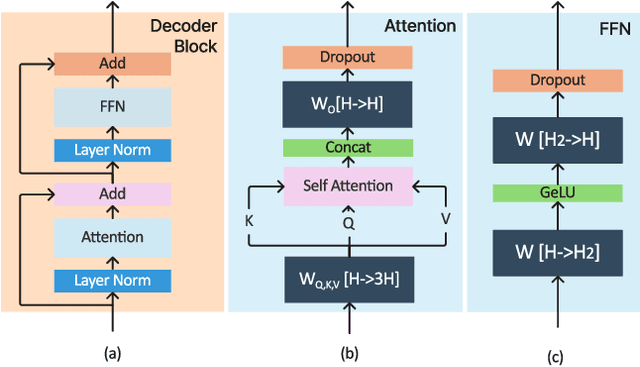
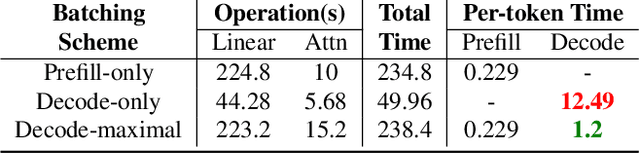
Large Language Model (LLM) inference consists of two distinct phases - prefill phase which processes the input prompt and decode phase which generates output tokens autoregressively. While the prefill phase effectively saturates GPU compute at small batch sizes, the decode phase results in low compute utilization as it generates one token at a time per request. The varying prefill and decode times also lead to imbalance across micro-batches when using pipeline parallelism, resulting in further inefficiency due to bubbles. We present SARATHI to address these challenges. SARATHI employs chunked-prefills, which splits a prefill request into equal sized chunks, and decode-maximal batching, which constructs a batch using a single prefill chunk and populates the remaining slots with decodes. During inference, the prefill chunk saturates GPU compute, while the decode requests 'piggyback' and cost up to an order of magnitude less compared to a decode-only batch. Chunked-prefills allows constructing multiple decode-maximal batches from a single prefill request, maximizing coverage of decodes that can piggyback. Furthermore, the uniform compute design of these batches ameliorates the imbalance between micro-batches, significantly reducing pipeline bubbles. Our techniques yield significant improvements in inference performance across models and hardware. For the LLaMA-13B model on A6000 GPU, SARATHI improves decode throughput by up to 10x, and accelerates end-to-end throughput by up to 1.33x. For LLaMa-33B on A100 GPU, we achieve 1.25x higher end-to-end-throughput and up to 4.25x higher decode throughput. When used with pipeline parallelism on GPT-3, SARATHI reduces bubbles by 6.29x, resulting in an end-to-end throughput improvement of 1.91x.