 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Greenferencing: Routing AI Inferencing to Green Modular Data Centers with Heron
May 15, 2025AI power demand is growing unprecedentedly thanks to the high power density of AI compute and the emerging inferencing workload. On the supply side, abundant wind power is waiting for grid access in interconnection queues. In this light, this paper argues bringing AI workload to modular compute clusters co-located in wind farms. Our deployment right-sizing strategy makes it economically viable to deploy more than 6 million high-end GPUs today that could consume cheap, green power at its source. We built Heron, a cross-site software router, that could efficiently leverage the complementarity of power generation across wind farms by routing AI inferencing workload around power drops. Using 1-week ofcoding and conversation production traces from Azure and (real) variable wind power traces, we show how Heron improves aggregate goodput of AI compute by up to 80% compared to the state-of-the-art.
Niyama : Breaking the Silos of LLM Inference Serving
Mar 28, 2025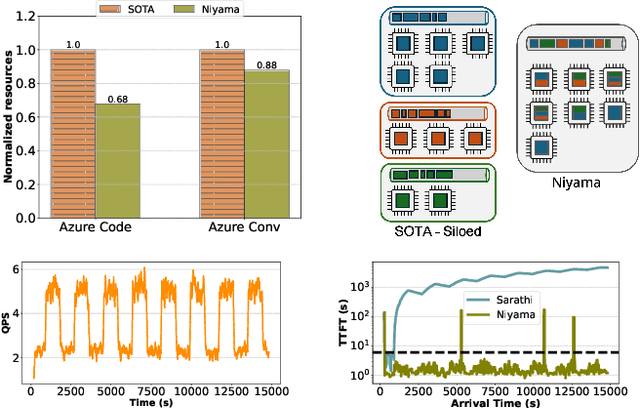



The widespread adoption of Large Language Models (LLMs) has enabled diverse applications with very different latency requirements. Existing LLM serving frameworks rely on siloed infrastructure with coarse-grained workload segregation -- interactive and batch -- leading to inefficient resource utilization and limited support for fine-grained Quality-of-Service (QoS) differentiation. This results in operational inefficiencies, over-provisioning and poor load management during traffic surges. We present Niyama, a novel QoS-driven inference serving system that enables efficient co-scheduling of diverse workloads on shared infrastructure. Niyama introduces fine-grained QoS classification allowing applications to specify precise latency requirements, and dynamically adapts scheduling decisions based on real-time system state. Leveraging the predictable execution characteristics of LLM inference, Niyama implements a dynamic chunking mechanism to improve overall throughput while maintaining strict QoS guarantees. Additionally, Niyama employs a hybrid prioritization policy that balances fairness and efficiency, and employs selective request relegation that enables graceful service degradation during overload conditions. Our evaluation demonstrates that Niyama increases serving capacity by 32% compared to current siloed deployments, while maintaining QoS guarantees. Notably, under extreme load, our system reduces SLO violations by an order of magnitude compared to current strategies.
Towards Efficient Large Multimodal Model Serving
Feb 02, 2025Recent advances in generative AI have led to large multi-modal models (LMMs) capable of simultaneously processing inputs of various modalities such as text, images, video, and audio. While these models demonstrate impressive capabilities, efficiently serving them in production environments poses significant challenges due to their complex architectures and heterogeneous resource requirements. We present the first comprehensive systems analysis of two prominent LMM architectures, decoder-only and cross-attention, on six representative open-source models. We investigate their multi-stage inference pipelines and resource utilization patterns that lead to unique systems design implications. We also present an in-depth analysis of production LMM inference traces, uncovering unique workload characteristics, including variable, heavy-tailed request distributions, diverse modal combinations, and bursty traffic patterns. Our key findings reveal that different LMM inference stages exhibit highly heterogeneous performance characteristics and resource demands, while concurrent requests across modalities lead to significant performance interference. To address these challenges, we propose a decoupled serving architecture that enables independent resource allocation and adaptive scaling for each stage. We further propose optimizations such as stage colocation to maximize throughput and resource utilization while meeting the latency objectives.
POD-Attention: Unlocking Full Prefill-Decode Overlap for Faster LLM Inference
Oct 23, 2024Each request in LLM inference goes through two phases: compute-bound prefill and memory-bandwidth-bound decode. To improve GPU utilization, recent systems use hybrid batching that combines the prefill and decode phases of different requests into the same batch. Hybrid batching works well for linear operations as it amortizes the cost of loading model weights from HBM. However, attention computation in hybrid batches remains inefficient because existing attention kernels are optimized for either prefill or decode. In this paper, we present POD-Attention -- the first GPU kernel that efficiently computes attention for hybrid batches. POD-Attention aims to maximize the utilization of both compute and memory bandwidth by carefully allocating the GPU's resources such that prefill and decode operations happen concurrently on the same multiprocessor. We integrate POD-Attention in a state-of-the-art LLM inference scheduler Sarathi-Serve. POD-Attention speeds up attention computation by up to 75% (mean 28%) and increases LLM serving throughput by up to 22% in offline inference. In online inference, POD-Attention enables lower time-to-first-token (TTFT), time-between-tokens (TBT), and request execution latency versus Sarathi-Serve.
ASTRA: Accurate and Scalable ANNS-based Training of Extreme Classifiers
Sep 30, 2024`Extreme Classification'' (or XC) is the task of annotating data points (queries) with relevant labels (documents), from an extremely large set of $L$ possible labels, arising in search and recommendations. The most successful deep learning paradigm that has emerged over the last decade or so for XC is to embed the queries (and labels) using a deep encoder (e.g. DistilBERT), and use linear classifiers on top of the query embeddings. This architecture is of appeal because it enables millisecond-time inference using approximate nearest neighbor search (ANNS). The key question is how do we design training algorithms that are accurate as well as scale to $O(100M)$ labels on a limited number of GPUs. State-of-the-art XC techniques that demonstrate high accuracies (e.g., DEXML, Ren\'ee, DEXA) on standard datasets have per-epoch training time that scales as $O(L)$ or employ expensive negative sampling strategies, which are prohibitive in XC scenarios. In this work, we develop an accurate and scalable XC algorithm ASTRA with two key observations: (a) building ANNS index on the classifier vectors and retrieving hard negatives using the classifiers aligns the negative sampling strategy to the loss function optimized; (b) keeping the ANNS indices current as the classifiers change through the epochs is prohibitively expensive while using stale negatives (refreshed periodically) results in poor accuracy; to remedy this, we propose a negative sampling strategy that uses a mixture of importance sampling and uniform sampling. By extensive evaluation on standard XC as well as proprietary datasets with 120M labels, we demonstrate that ASTRA achieves SOTA precision, while reducing training time by 4x-15x relative to the second best.
Metron: Holistic Performance Evaluation Framework for LLM Inference Systems
Jul 09, 2024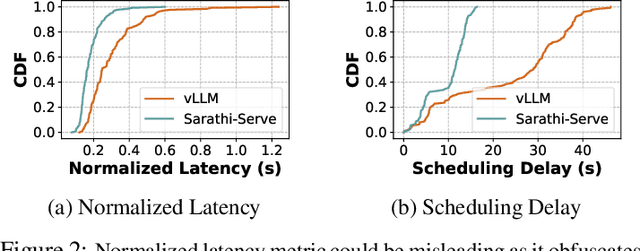
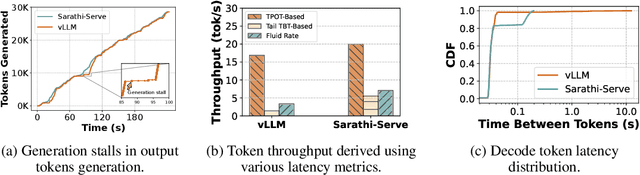
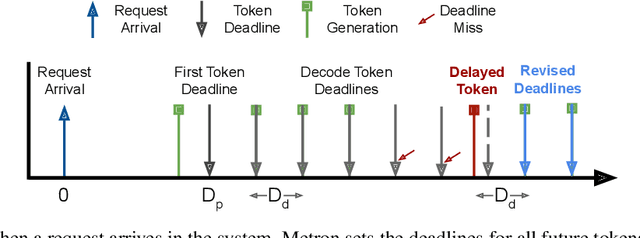
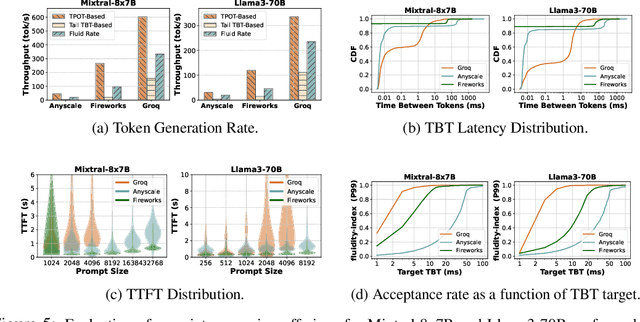
Serving large language models (LLMs) in production can incur substantial costs, which has prompted recent advances in inference system optimizations. Today, these systems are evaluated against conventional latency and throughput metrics (eg. TTFT, TBT, Normalised Latency and TPOT). However, these metrics fail to fully capture the nuances of LLM inference, leading to an incomplete assessment of user-facing performance crucial for real-time applications such as chat and translation. In this paper, we first identify the pitfalls of current performance metrics in evaluating LLM inference systems. We then propose Metron, a comprehensive performance evaluation framework that includes fluidity-index -- a novel metric designed to reflect the intricacies of the LLM inference process and its impact on real-time user experience. Finally, we evaluate various existing open-source platforms and model-as-a-service offerings using Metron, discussing their strengths and weaknesses. Metron is available at https://github.com/project-metron/metron.
Vidur: A Large-Scale Simulation Framework For LLM Inference
May 08, 2024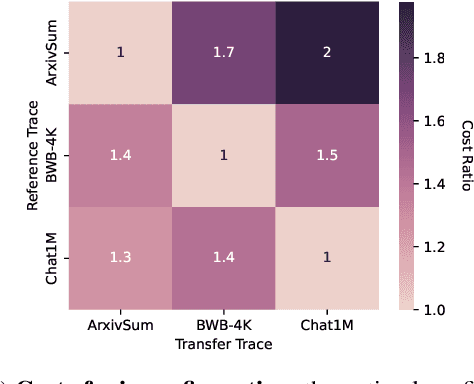

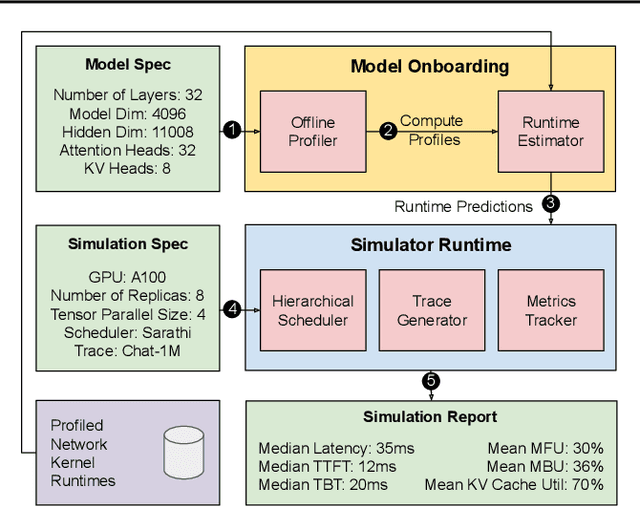
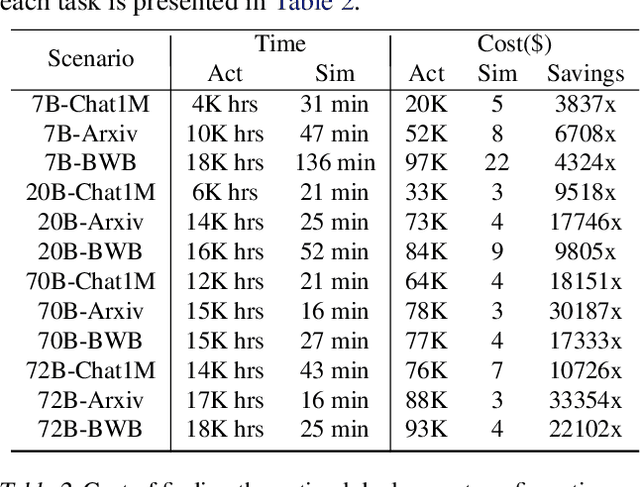
Optimizing the deployment of Large language models (LLMs) is expensive today since it requires experimentally running an application workload against an LLM implementation while exploring large configuration space formed by system knobs such as parallelization strategies, batching techniques, and scheduling policies. To address this challenge, we present Vidur - a large-scale, high-fidelity, easily-extensible simulation framework for LLM inference performance. Vidur models the performance of LLM operators using a combination of experimental profiling and predictive modeling, and evaluates the end-to-end inference performance for different workloads by estimating several metrics of interest such as latency and throughput. We validate the fidelity of Vidur on several LLMs and show that it estimates inference latency with less than 9% error across the range. Further, we present Vidur-Search, a configuration search tool that helps optimize LLM deployment. Vidur-Search uses Vidur to automatically identify the most cost-effective deployment configuration that meets application performance constraints. For example, Vidur-Search finds the best deployment configuration for LLaMA2-70B in one hour on a CPU machine, in contrast to a deployment-based exploration which would require 42K GPU hours - costing ~218K dollars. Source code for Vidur is available at https://github.com/microsoft/vidur.
vAttention: Dynamic Memory Management for Serving LLMs without PagedAttention
May 07, 2024



Efficient use of GPU memory is essential for high throughput LLM inference. Prior systems reserved memory for the KV-cache ahead-of-time, resulting in wasted capacity due to internal fragmentation. Inspired by OS-based virtual memory systems, vLLM proposed PagedAttention to enable dynamic memory allocation for KV-cache. This approach eliminates fragmentation, enabling high-throughput LLM serving with larger batch sizes. However, to be able to allocate physical memory dynamically, PagedAttention changes the layout of KV-cache from contiguous virtual memory to non-contiguous virtual memory. This change requires attention kernels to be rewritten to support paging, and serving framework to implement a memory manager. Thus, the PagedAttention model leads to software complexity, portability issues, redundancy and inefficiency. In this paper, we propose vAttention for dynamic KV-cache memory management. In contrast to PagedAttention, vAttention retains KV-cache in contiguous virtual memory and leverages low-level system support for demand paging, that already exists, to enable on-demand physical memory allocation. Thus, vAttention unburdens the attention kernel developer from having to explicitly support paging and avoids re-implementation of memory management in the serving framework. We show that vAttention enables seamless dynamic memory management for unchanged implementations of various attention kernels. vAttention also generates tokens up to 1.97x faster than vLLM, while processing input prompts up to 3.92x and 1.45x faster than the PagedAttention variants of FlashAttention and FlashInfer.
Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve
Mar 04, 2024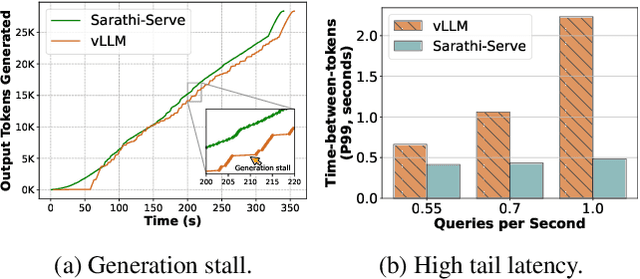

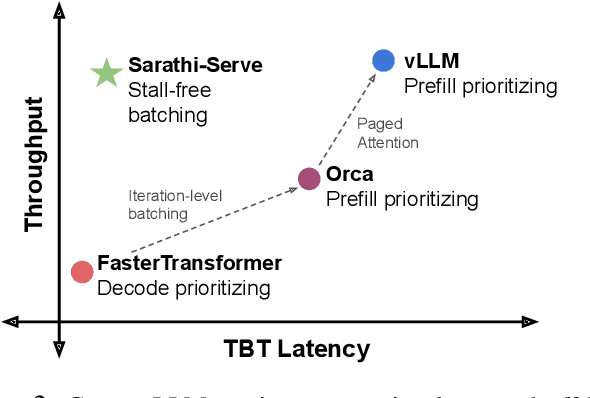

Each LLM serving request goes through two phases. The first is prefill which processes the entire input prompt to produce one output token and the second is decode which generates the rest of output tokens, one-at-a-time. Prefill iterations have high latency but saturate GPU compute due to parallel processing of the input prompt. In contrast, decode iterations have low latency but also low compute utilization because a decode iteration processes only a single token per request. This makes batching highly effective for decodes and consequently for overall throughput. However, batching multiple requests leads to an interleaving of prefill and decode iterations which makes it challenging to achieve both high throughput and low latency. We introduce an efficient LLM inference scheduler Sarathi-Serve inspired by the techniques we originally proposed for optimizing throughput in Sarathi. Sarathi-Serve leverages chunked-prefills from Sarathi to create stall-free schedules that can add new requests in a batch without pausing ongoing decodes. Stall-free scheduling unlocks the opportunity to improve throughput with large batch sizes while minimizing the effect of batching on latency. Our evaluation shows that Sarathi-Serve improves serving throughput within desired latency SLOs of Mistral-7B by up to 2.6x on a single A100 GPU and up to 6.9x for Falcon-180B on 8 A100 GPUs over Orca and vLLM.
SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills
Aug 31, 2023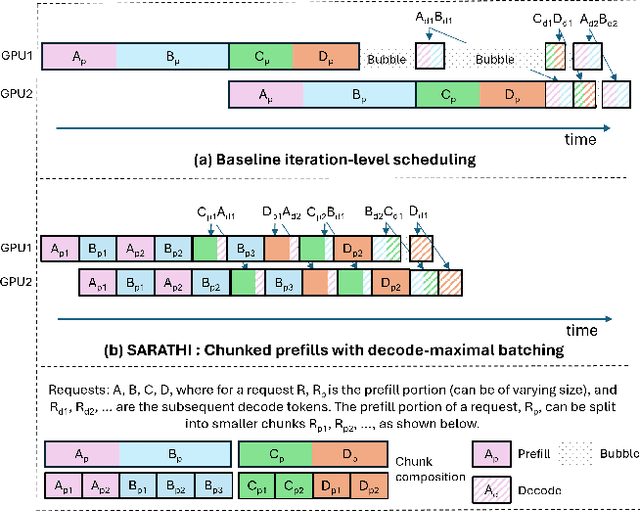
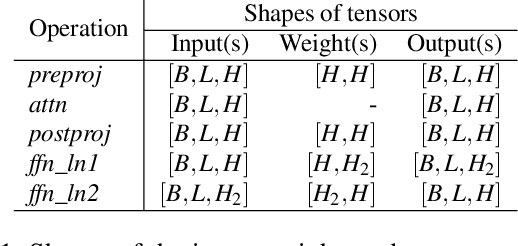
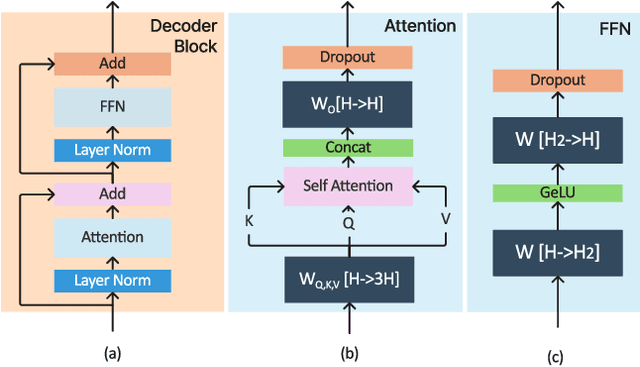
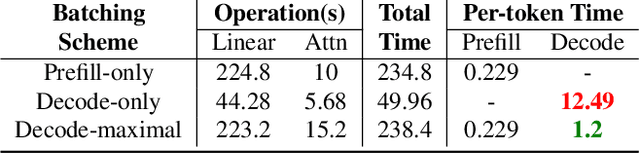
Large Language Model (LLM) inference consists of two distinct phases - prefill phase which processes the input prompt and decode phase which generates output tokens autoregressively. While the prefill phase effectively saturates GPU compute at small batch sizes, the decode phase results in low compute utilization as it generates one token at a time per request. The varying prefill and decode times also lead to imbalance across micro-batches when using pipeline parallelism, resulting in further inefficiency due to bubbles. We present SARATHI to address these challenges. SARATHI employs chunked-prefills, which splits a prefill request into equal sized chunks, and decode-maximal batching, which constructs a batch using a single prefill chunk and populates the remaining slots with decodes. During inference, the prefill chunk saturates GPU compute, while the decode requests 'piggyback' and cost up to an order of magnitude less compared to a decode-only batch. Chunked-prefills allows constructing multiple decode-maximal batches from a single prefill request, maximizing coverage of decodes that can piggyback. Furthermore, the uniform compute design of these batches ameliorates the imbalance between micro-batches, significantly reducing pipeline bubbles. Our techniques yield significant improvements in inference performance across models and hardware. For the LLaMA-13B model on A6000 GPU, SARATHI improves decode throughput by up to 10x, and accelerates end-to-end throughput by up to 1.33x. For LLaMa-33B on A100 GPU, we achieve 1.25x higher end-to-end-throughput and up to 4.25x higher decode throughput. When used with pipeline parallelism on GPT-3, SARATHI reduces bubbles by 6.29x, resulting in an end-to-end throughput improvement of 1.91x.