 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-42: Enabling Determinism in LLM Inference with Verified Speculation
Jan 25, 2026In LLM inference, the same prompt may yield different outputs across different runs. At the system level, this non-determinism arises from floating-point non-associativity combined with dynamic batching and GPU kernels whose reduction orders vary with batch size. A straightforward way to eliminate non-determinism is to disable dynamic batching during inference, but doing so severely degrades throughput. Another approach is to make kernels batch-invariant; however, this tightly couples determinism to kernel design, requiring new implementations. This coupling also imposes fixed runtime overheads, regardless of how much of the workload actually requires determinism. Inspired by ideas from speculative decoding, we present LLM-42, a scheduling-based approach to enable determinism in LLM inference. Our key observation is that if a sequence is in a consistent state, the next emitted token is likely to be consistent even with dynamic batching. Moreover, most GPU kernels use shape-consistent reductions. Leveraging these insights, LLM-42 decodes tokens using a non-deterministic fast path and enforces determinism via a lightweight verify-rollback loop. The verifier replays candidate tokens under a fixed-shape reduction schedule, commits those that are guaranteed to be consistent across runs, and rolls back those violating determinism. LLM-42 mostly re-uses existing kernels unchanged and incurs overhead only in proportion to the traffic that requires determinism.
POD-Attention: Unlocking Full Prefill-Decode Overlap for Faster LLM Inference
Oct 23, 2024Each request in LLM inference goes through two phases: compute-bound prefill and memory-bandwidth-bound decode. To improve GPU utilization, recent systems use hybrid batching that combines the prefill and decode phases of different requests into the same batch. Hybrid batching works well for linear operations as it amortizes the cost of loading model weights from HBM. However, attention computation in hybrid batches remains inefficient because existing attention kernels are optimized for either prefill or decode. In this paper, we present POD-Attention -- the first GPU kernel that efficiently computes attention for hybrid batches. POD-Attention aims to maximize the utilization of both compute and memory bandwidth by carefully allocating the GPU's resources such that prefill and decode operations happen concurrently on the same multiprocessor. We integrate POD-Attention in a state-of-the-art LLM inference scheduler Sarathi-Serve. POD-Attention speeds up attention computation by up to 75% (mean 28%) and increases LLM serving throughput by up to 22% in offline inference. In online inference, POD-Attention enables lower time-to-first-token (TTFT), time-between-tokens (TBT), and request execution latency versus Sarathi-Serve.
LLeMpower: Understanding Disparities in the Control and Access of Large Language Models
Apr 14, 2024



Large Language Models (LLMs) are a powerful technology that augment human skill to create new opportunities, akin to the development of steam engines and the internet. However, LLMs come with a high cost. They require significant computing resources and energy to train and serve. Inequity in their control and access has led to concentration of ownership and power to a small collection of corporations. In our study, we collect training and inference requirements for various LLMs. We then analyze the economic strengths of nations and organizations in the context of developing and serving these models. Additionally, we also look at whether individuals around the world can access and use this emerging technology. We compare and contrast these groups to show that these technologies are monopolized by a surprisingly few entities. We conclude with a qualitative study on the ethical implications of our findings and discuss future directions towards equity in LLM access.
Herding LLaMaS: Using LLMs as an OS Module
Jan 17, 2024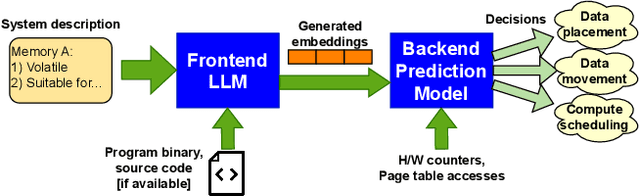
Computer systems are becoming increasingly heterogeneous with the emergence of new memory technologies and compute devices. GPUs alongside CPUs have become commonplace and CXL is poised to be a mainstay of cloud systems. The operating system is responsible for managing these hardware resources, requiring modification every time a new device is released. Years of research and development are sunk into tuning the OS for high performance with each new heterogeneous device. With the recent explosion in memory technologies and domain-specific accelerators, it would be beneficial to have an OS that could provide high performance for new devices without significant effort. We propose LLaMaS which can adapt to new devices easily. LLaMaS uses Large Language Models (LLMs) to extract the useful features of new devices from their textual description and uses these features to make operating system decisions at runtime. Adding support to LLaMaS for a new device is as simple as describing the system and new device properties in plaintext. LLaMaS reduces the burden on system administrators to enable easy integration of new devices into production systems. Preliminary evaluation using ChatGPT shows that LLMs are capable of extracting device features from text and make correct OS decisions based on those features.