 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVulcan: Instance-Optimal Systems Heuristics Through LLM-Driven Search
Dec 31, 2025Resource-management tasks in modern operating and distributed systems continue to rely primarily on hand-designed heuristics for tasks such as scheduling, caching, or active queue management. Designing performant heuristics is an expensive, time-consuming process that we are forced to continuously go through due to the constant flux of hardware, workloads and environments. We propose a new alternative: synthesizing instance-optimal heuristics -- specialized for the exact workloads and hardware where they will be deployed -- using code-generating large language models (LLMs). To make this synthesis tractable, Vulcan separates policy and mechanism through LLM-friendly, task-agnostic interfaces. With these interfaces, users specify the inputs and objectives of their desired policy, while Vulcan searches for performant policies via evolutionary search over LLM-generated code. This interface is expressive enough to capture a wide range of system policies, yet sufficiently constrained to allow even small, inexpensive LLMs to generate correct and executable code. We use Vulcan to synthesize performant heuristics for cache eviction and memory tiering, and find that these heuristics outperform all human-designed state-of-the-art algorithms by upto 69% and 7.9% in performance for each of these tasks respectively.
Herding LLaMaS: Using LLMs as an OS Module
Jan 17, 2024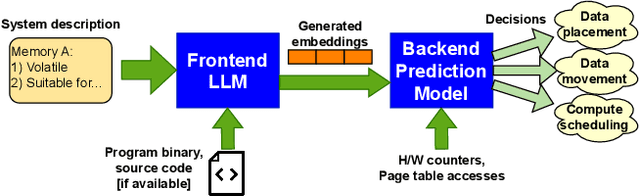
Computer systems are becoming increasingly heterogeneous with the emergence of new memory technologies and compute devices. GPUs alongside CPUs have become commonplace and CXL is poised to be a mainstay of cloud systems. The operating system is responsible for managing these hardware resources, requiring modification every time a new device is released. Years of research and development are sunk into tuning the OS for high performance with each new heterogeneous device. With the recent explosion in memory technologies and domain-specific accelerators, it would be beneficial to have an OS that could provide high performance for new devices without significant effort. We propose LLaMaS which can adapt to new devices easily. LLaMaS uses Large Language Models (LLMs) to extract the useful features of new devices from their textual description and uses these features to make operating system decisions at runtime. Adding support to LLaMaS for a new device is as simple as describing the system and new device properties in plaintext. LLaMaS reduces the burden on system administrators to enable easy integration of new devices into production systems. Preliminary evaluation using ChatGPT shows that LLMs are capable of extracting device features from text and make correct OS decisions based on those features.