 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-42: Enabling Determinism in LLM Inference with Verified Speculation
Jan 25, 2026In LLM inference, the same prompt may yield different outputs across different runs. At the system level, this non-determinism arises from floating-point non-associativity combined with dynamic batching and GPU kernels whose reduction orders vary with batch size. A straightforward way to eliminate non-determinism is to disable dynamic batching during inference, but doing so severely degrades throughput. Another approach is to make kernels batch-invariant; however, this tightly couples determinism to kernel design, requiring new implementations. This coupling also imposes fixed runtime overheads, regardless of how much of the workload actually requires determinism. Inspired by ideas from speculative decoding, we present LLM-42, a scheduling-based approach to enable determinism in LLM inference. Our key observation is that if a sequence is in a consistent state, the next emitted token is likely to be consistent even with dynamic batching. Moreover, most GPU kernels use shape-consistent reductions. Leveraging these insights, LLM-42 decodes tokens using a non-deterministic fast path and enforces determinism via a lightweight verify-rollback loop. The verifier replays candidate tokens under a fixed-shape reduction schedule, commits those that are guaranteed to be consistent across runs, and rolls back those violating determinism. LLM-42 mostly re-uses existing kernels unchanged and incurs overhead only in proportion to the traffic that requires determinism.
PyGraph: Robust Compiler Support for CUDA Graphs in PyTorch
Mar 25, 2025


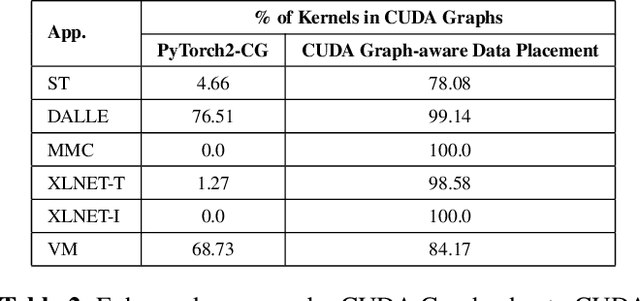
CUDA Graphs -- a recent hardware feature introduced for NVIDIA GPUs -- aim to reduce CPU launch overhead by capturing and launching a series of GPU tasks (kernels) as a DAG. However, deploying CUDA Graphs faces several challenges today due to the static structure of a graph. It also incurs performance overhead due to data copy. In fact, we show a counter-intuitive result -- deploying CUDA Graphs hurts performance in many cases. We introduce PyGraph, a novel approach to automatically harness the power of CUDA Graphs within PyTorch2. Driven by three key observations, PyGraph embodies three novel optimizations: it enables wider deployment of CUDA Graphs, reduces GPU kernel parameter copy overheads, and selectively deploys CUDA Graphs based on a cost-benefit analysis. PyGraph seamlessly integrates with PyTorch2's compilation toolchain, enabling efficient use of CUDA Graphs without manual modifications to the code. We evaluate PyGraph across various machine learning benchmarks, demonstrating substantial performance improvements over PyTorch2.
POD-Attention: Unlocking Full Prefill-Decode Overlap for Faster LLM Inference
Oct 23, 2024Each request in LLM inference goes through two phases: compute-bound prefill and memory-bandwidth-bound decode. To improve GPU utilization, recent systems use hybrid batching that combines the prefill and decode phases of different requests into the same batch. Hybrid batching works well for linear operations as it amortizes the cost of loading model weights from HBM. However, attention computation in hybrid batches remains inefficient because existing attention kernels are optimized for either prefill or decode. In this paper, we present POD-Attention -- the first GPU kernel that efficiently computes attention for hybrid batches. POD-Attention aims to maximize the utilization of both compute and memory bandwidth by carefully allocating the GPU's resources such that prefill and decode operations happen concurrently on the same multiprocessor. We integrate POD-Attention in a state-of-the-art LLM inference scheduler Sarathi-Serve. POD-Attention speeds up attention computation by up to 75% (mean 28%) and increases LLM serving throughput by up to 22% in offline inference. In online inference, POD-Attention enables lower time-to-first-token (TTFT), time-between-tokens (TBT), and request execution latency versus Sarathi-Serve.
Vidur: A Large-Scale Simulation Framework For LLM Inference
May 08, 2024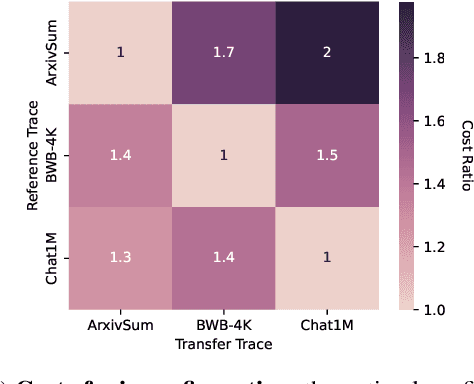

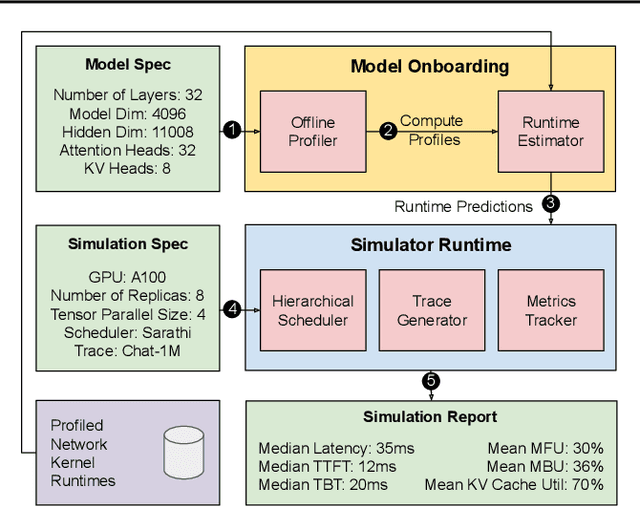
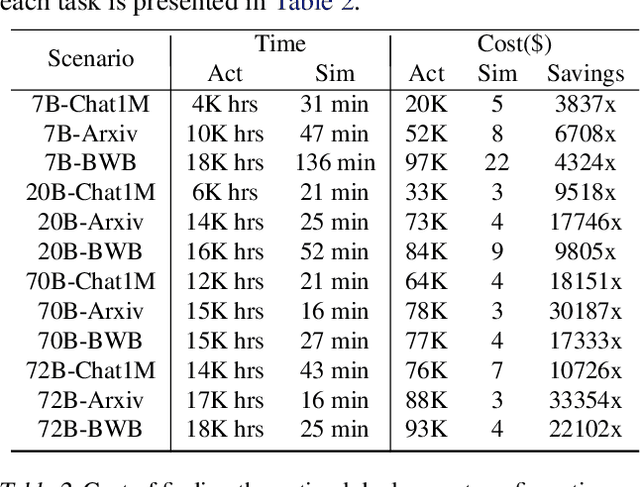
Optimizing the deployment of Large language models (LLMs) is expensive today since it requires experimentally running an application workload against an LLM implementation while exploring large configuration space formed by system knobs such as parallelization strategies, batching techniques, and scheduling policies. To address this challenge, we present Vidur - a large-scale, high-fidelity, easily-extensible simulation framework for LLM inference performance. Vidur models the performance of LLM operators using a combination of experimental profiling and predictive modeling, and evaluates the end-to-end inference performance for different workloads by estimating several metrics of interest such as latency and throughput. We validate the fidelity of Vidur on several LLMs and show that it estimates inference latency with less than 9% error across the range. Further, we present Vidur-Search, a configuration search tool that helps optimize LLM deployment. Vidur-Search uses Vidur to automatically identify the most cost-effective deployment configuration that meets application performance constraints. For example, Vidur-Search finds the best deployment configuration for LLaMA2-70B in one hour on a CPU machine, in contrast to a deployment-based exploration which would require 42K GPU hours - costing ~218K dollars. Source code for Vidur is available at https://github.com/microsoft/vidur.
vAttention: Dynamic Memory Management for Serving LLMs without PagedAttention
May 07, 2024



Efficient use of GPU memory is essential for high throughput LLM inference. Prior systems reserved memory for the KV-cache ahead-of-time, resulting in wasted capacity due to internal fragmentation. Inspired by OS-based virtual memory systems, vLLM proposed PagedAttention to enable dynamic memory allocation for KV-cache. This approach eliminates fragmentation, enabling high-throughput LLM serving with larger batch sizes. However, to be able to allocate physical memory dynamically, PagedAttention changes the layout of KV-cache from contiguous virtual memory to non-contiguous virtual memory. This change requires attention kernels to be rewritten to support paging, and serving framework to implement a memory manager. Thus, the PagedAttention model leads to software complexity, portability issues, redundancy and inefficiency. In this paper, we propose vAttention for dynamic KV-cache memory management. In contrast to PagedAttention, vAttention retains KV-cache in contiguous virtual memory and leverages low-level system support for demand paging, that already exists, to enable on-demand physical memory allocation. Thus, vAttention unburdens the attention kernel developer from having to explicitly support paging and avoids re-implementation of memory management in the serving framework. We show that vAttention enables seamless dynamic memory management for unchanged implementations of various attention kernels. vAttention also generates tokens up to 1.97x faster than vLLM, while processing input prompts up to 3.92x and 1.45x faster than the PagedAttention variants of FlashAttention and FlashInfer.
Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve
Mar 04, 2024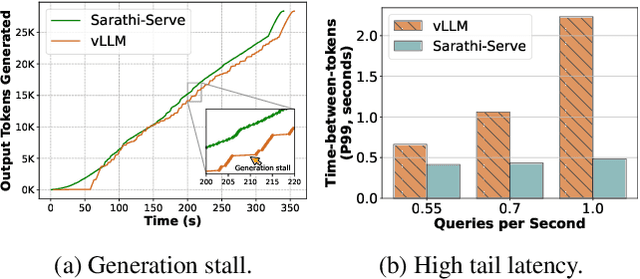

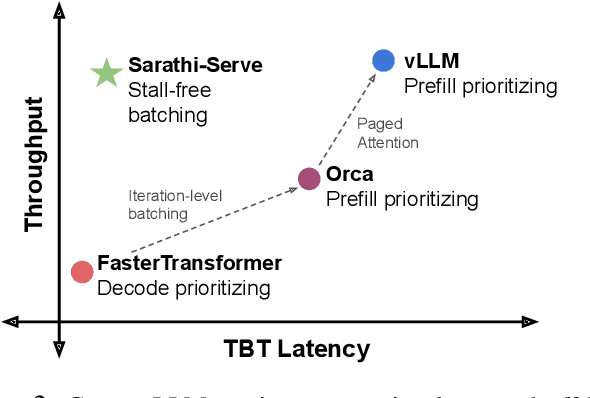

Each LLM serving request goes through two phases. The first is prefill which processes the entire input prompt to produce one output token and the second is decode which generates the rest of output tokens, one-at-a-time. Prefill iterations have high latency but saturate GPU compute due to parallel processing of the input prompt. In contrast, decode iterations have low latency but also low compute utilization because a decode iteration processes only a single token per request. This makes batching highly effective for decodes and consequently for overall throughput. However, batching multiple requests leads to an interleaving of prefill and decode iterations which makes it challenging to achieve both high throughput and low latency. We introduce an efficient LLM inference scheduler Sarathi-Serve inspired by the techniques we originally proposed for optimizing throughput in Sarathi. Sarathi-Serve leverages chunked-prefills from Sarathi to create stall-free schedules that can add new requests in a batch without pausing ongoing decodes. Stall-free scheduling unlocks the opportunity to improve throughput with large batch sizes while minimizing the effect of batching on latency. Our evaluation shows that Sarathi-Serve improves serving throughput within desired latency SLOs of Mistral-7B by up to 2.6x on a single A100 GPU and up to 6.9x for Falcon-180B on 8 A100 GPUs over Orca and vLLM.
SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills
Aug 31, 2023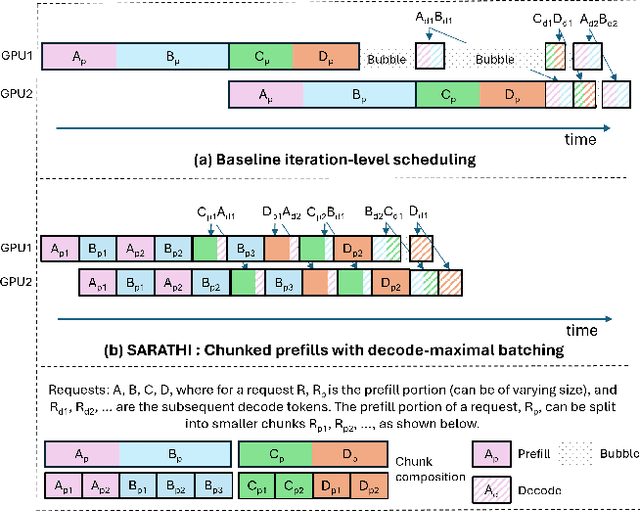
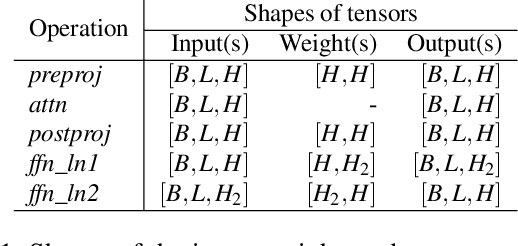
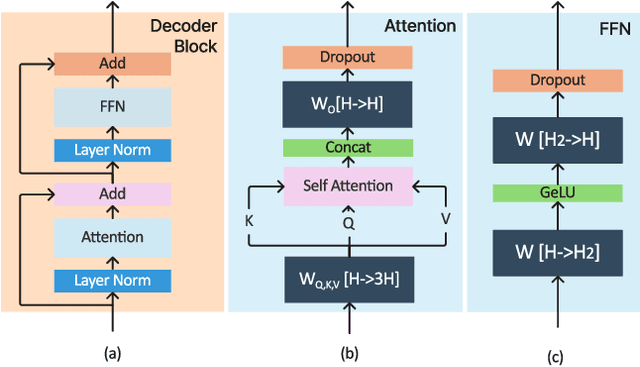
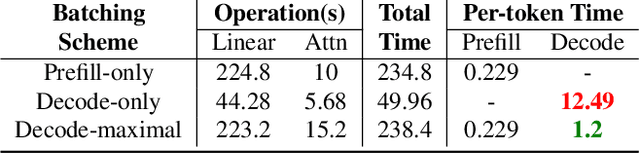
Large Language Model (LLM) inference consists of two distinct phases - prefill phase which processes the input prompt and decode phase which generates output tokens autoregressively. While the prefill phase effectively saturates GPU compute at small batch sizes, the decode phase results in low compute utilization as it generates one token at a time per request. The varying prefill and decode times also lead to imbalance across micro-batches when using pipeline parallelism, resulting in further inefficiency due to bubbles. We present SARATHI to address these challenges. SARATHI employs chunked-prefills, which splits a prefill request into equal sized chunks, and decode-maximal batching, which constructs a batch using a single prefill chunk and populates the remaining slots with decodes. During inference, the prefill chunk saturates GPU compute, while the decode requests 'piggyback' and cost up to an order of magnitude less compared to a decode-only batch. Chunked-prefills allows constructing multiple decode-maximal batches from a single prefill request, maximizing coverage of decodes that can piggyback. Furthermore, the uniform compute design of these batches ameliorates the imbalance between micro-batches, significantly reducing pipeline bubbles. Our techniques yield significant improvements in inference performance across models and hardware. For the LLaMA-13B model on A6000 GPU, SARATHI improves decode throughput by up to 10x, and accelerates end-to-end throughput by up to 1.33x. For LLaMa-33B on A100 GPU, we achieve 1.25x higher end-to-end-throughput and up to 4.25x higher decode throughput. When used with pipeline parallelism on GPT-3, SARATHI reduces bubbles by 6.29x, resulting in an end-to-end throughput improvement of 1.91x.