 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRearchitecting Datacenter Lifecycle for AI: A TCO-Driven Framework
Sep 30, 2025The rapid rise of large language models (LLMs) has been driving an enormous demand for AI inference infrastructure, mainly powered by high-end GPUs. While these accelerators offer immense computational power, they incur high capital and operational costs due to frequent upgrades, dense power consumption, and cooling demands, making total cost of ownership (TCO) for AI datacenters a critical concern for cloud providers. Unfortunately, traditional datacenter lifecycle management (designed for general-purpose workloads) struggles to keep pace with AI's fast-evolving models, rising resource needs, and diverse hardware profiles. In this paper, we rethink the AI datacenter lifecycle scheme across three stages: building, hardware refresh, and operation. We show how design choices in power, cooling, and networking provisioning impact long-term TCO. We also explore refresh strategies aligned with hardware trends. Finally, we use operation software optimizations to reduce cost. While these optimizations at each stage yield benefits, unlocking the full potential requires rethinking the entire lifecycle. Thus, we present a holistic lifecycle management framework that coordinates and co-optimizes decisions across all three stages, accounting for workload dynamics, hardware evolution, and system aging. Our system reduces the TCO by up to 40\% over traditional approaches. Using our framework we provide guidelines on how to manage AI datacenter lifecycle for the future.
Towards Efficient Large Multimodal Model Serving
Feb 02, 2025Recent advances in generative AI have led to large multi-modal models (LMMs) capable of simultaneously processing inputs of various modalities such as text, images, video, and audio. While these models demonstrate impressive capabilities, efficiently serving them in production environments poses significant challenges due to their complex architectures and heterogeneous resource requirements. We present the first comprehensive systems analysis of two prominent LMM architectures, decoder-only and cross-attention, on six representative open-source models. We investigate their multi-stage inference pipelines and resource utilization patterns that lead to unique systems design implications. We also present an in-depth analysis of production LMM inference traces, uncovering unique workload characteristics, including variable, heavy-tailed request distributions, diverse modal combinations, and bursty traffic patterns. Our key findings reveal that different LMM inference stages exhibit highly heterogeneous performance characteristics and resource demands, while concurrent requests across modalities lead to significant performance interference. To address these challenges, we propose a decoupled serving architecture that enables independent resource allocation and adaptive scaling for each stage. We further propose optimizations such as stage colocation to maximize throughput and resource utilization while meeting the latency objectives.
Towards Resource-Efficient Compound AI Systems
Jan 29, 2025Compound AI Systems, integrating multiple interacting components like models, retrievers, and external tools, have emerged as essential for addressing complex AI tasks. However, current implementations suffer from inefficient resource utilization due to tight coupling between application logic and execution details, a disconnect between orchestration and resource management layers, and the perceived exclusiveness between efficiency and quality. We propose a vision for resource-efficient Compound AI Systems through a declarative workflow programming model and an adaptive runtime system for dynamic scheduling and resource-aware decision-making. Decoupling application logic from low-level details exposes levers for the runtime to flexibly configure the execution environment and resources, without compromising on quality. Enabling collaboration between the workflow orchestration and cluster manager enables higher efficiency through better scheduling and resource management. We are building a prototype system, called Murakkab, to realize this vision. Our preliminary evaluation demonstrates speedups up to $\sim 3.4\times$ in workflow completion times while delivering $\sim 4.5\times$ higher energy efficiency, showing promise in optimizing resources and advancing AI system design.
TAPAS: Thermal- and Power-Aware Scheduling for LLM Inference in Cloud Platforms
Jan 05, 2025



The rising demand for generative large language models (LLMs) poses challenges for thermal and power management in cloud datacenters. Traditional techniques often are inadequate for LLM inference due to the fine-grained, millisecond-scale execution phases, each with distinct performance, thermal, and power profiles. Additionally, LLM inference workloads are sensitive to various configuration parameters (e.g., model parallelism, size, and quantization) that involve trade-offs between performance, temperature, power, and output quality. Moreover, clouds often co-locate SaaS and IaaS workloads, each with different levels of visibility and flexibility. We propose TAPAS, a thermal- and power-aware framework designed for LLM inference clusters in the cloud. TAPAS enhances cooling and power oversubscription capabilities, reducing the total cost of ownership (TCO) while effectively handling emergencies (e.g., cooling and power failures). The system leverages historical temperature and power data, along with the adaptability of SaaS workloads, to: (1) efficiently place new GPU workload VMs within cooling and power constraints, (2) route LLM inference requests across SaaS VMs, and (3) reconfigure SaaS VMs to manage load spikes and emergency situations. Our evaluation on a large GPU cluster demonstrates significant reductions in thermal and power throttling events, boosting system efficiency.
Mnemosyne: Parallelization Strategies for Efficiently Serving Multi-Million Context Length LLM Inference Requests Without Approximations
Sep 25, 2024
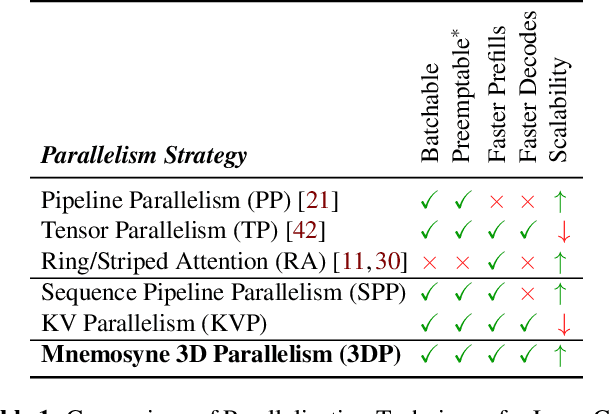
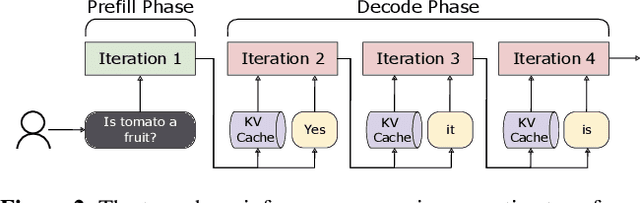
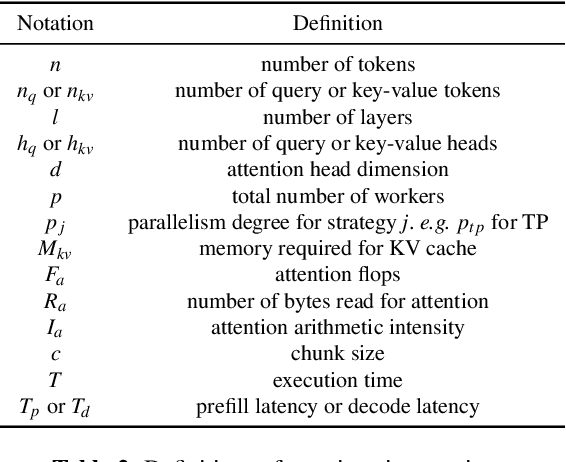
As large language models (LLMs) evolve to handle increasingly longer contexts, serving inference requests for context lengths in the range of millions of tokens presents unique challenges. While existing techniques are effective for training, they fail to address the unique challenges of inference, such as varying prefill and decode phases and their associated latency constraints - like Time to First Token (TTFT) and Time Between Tokens (TBT). Furthermore, there are no long context inference solutions that allow batching requests to increase the hardware utilization today. In this paper, we propose three key innovations for efficient interactive long context LLM inference, without resorting to any approximation: adaptive chunking to reduce prefill overheads in mixed batching, Sequence Pipeline Parallelism (SPP) to lower TTFT, and KV Cache Parallelism (KVP) to minimize TBT. These contributions are combined into a 3D parallelism strategy, enabling Mnemosyne to scale interactive inference to context lengths at least up to 10 million tokens with high throughput enabled with batching. To our knowledge, Mnemosyne is the first to be able to achieve support for 10 million long context inference efficiently, while satisfying production-grade SLOs on TBT (30ms) on contexts up to and including 10 million.
DynamoLLM: Designing LLM Inference Clusters for Performance and Energy Efficiency
Aug 01, 2024



The rapid evolution and widespread adoption of generative large language models (LLMs) have made them a pivotal workload in various applications. Today, LLM inference clusters receive a large number of queries with strict Service Level Objectives (SLOs). To achieve the desired performance, these models execute on power-hungry GPUs causing the inference clusters to consume large amount of energy and, consequently, result in excessive carbon emissions. Fortunately, we find that there is a great opportunity to exploit the heterogeneity in inference compute properties and fluctuations in inference workloads, to significantly improve energy-efficiency. However, such a diverse and dynamic environment creates a large search-space where different system configurations (e.g., number of instances, model parallelism, and GPU frequency) translate into different energy-performance trade-offs. To address these challenges, we propose DynamoLLM, the first energy-management framework for LLM inference environments. DynamoLLM automatically and dynamically reconfigures the inference cluster to optimize for energy and cost of LLM serving under the service's performance SLOs. We show that at a service-level, DynamoLLM conserves 53% energy and 38% operational carbon emissions, and reduces 61% cost to the customer, while meeting the latency SLOs.
POLCA: Power Oversubscription in LLM Cloud Providers
Aug 24, 2023



Recent innovation in large language models (LLMs), and their myriad use-cases have rapidly driven up the compute capacity demand for datacenter GPUs. Several cloud providers and other enterprises have made substantial plans of growth in their datacenters to support these new workloads. One of the key bottleneck resources in datacenters is power, and given the increasing model sizes of LLMs, they are becoming increasingly power intensive. In this paper, we show that there is a significant opportunity to oversubscribe power in LLM clusters. Power oversubscription improves the power efficiency of these datacenters, allowing more deployable servers per datacenter, and reduces the deployment time, since building new datacenters is slow. We extensively characterize the power consumption patterns of a variety of LLMs and their configurations. We identify the differences between the inference and training power consumption patterns. Based on our analysis of these LLMs, we claim that the average and peak power utilization in LLM clusters for inference should not be very high. Our deductions align with the data from production LLM clusters, revealing that inference workloads offer substantial headroom for power oversubscription. However, the stringent set of telemetry and controls that GPUs offer in a virtualized environment, makes it challenging to have a reliable and robust power oversubscription mechanism. We propose POLCA, our framework for power oversubscription that is robust, reliable, and readily deployable for GPU clusters. Using open-source models to replicate the power patterns observed in production, we simulate POLCA and demonstrate that we can deploy 30% more servers in the same GPU cluster for inference, with minimal performance loss