 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthesizing Access Control Policies using Large Language Models
Mar 14, 2025



Cloud compute systems allow administrators to write access control policies that govern access to private data. While policies are written in convenient languages, such as AWS Identity and Access Management Policy Language, manually written policies often become complex and error prone. In this paper, we investigate whether and how well Large Language Models (LLMs) can be used to synthesize access control policies. Our investigation focuses on the task of taking an access control request specification and zero-shot prompting LLMs to synthesize a well-formed access control policy which correctly adheres to the request specification. We consider two scenarios, one which the request specification is given as a concrete list of requests to be allowed or denied, and another in which a natural language description is used to specify sets of requests to be allowed or denied. We then argue that for zero-shot prompting, more precise and structured prompts using a syntax based approach are necessary and experimentally show preliminary results validating our approach.
Input-Dependent Power Usage in GPUs
Sep 26, 2024

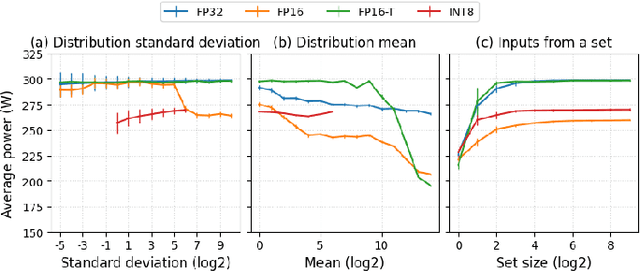
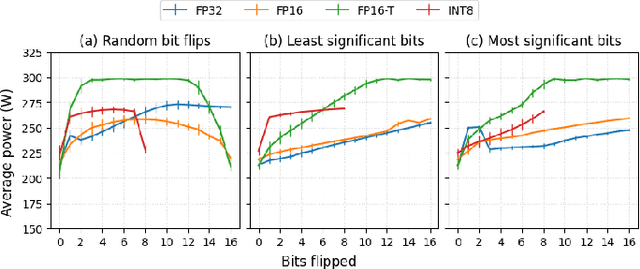
GPUs are known to be power-hungry, and due to the boom in artificial intelligence, they are currently the major contributors to the high power demands of upcoming datacenters. Most GPU usage in these popular workloads consist of large general matrix-matrix multiplications (GEMMs), which have therefore been optimized to achieve high utilization of hardware resources. In this work, we show that modifying the input data to GEMMs, while maintaining the matrix shapes and sizes can notably change the power consumption of these kernels. We experiment with four kinds of input variations: value distribution, bit similarity, placement, and sparsity, across different data types. Our findings indicate that these variations can change the GPU power usage during GEMM by almost 40%. We hypothesize that input-dependent power usage variations occur due to changes in the number of bit flips in the GPUs. We propose leveraging this property through compiler and scheduler optimizations to manage power and reduce energy consumption.
POLCA: Power Oversubscription in LLM Cloud Providers
Aug 24, 2023



Recent innovation in large language models (LLMs), and their myriad use-cases have rapidly driven up the compute capacity demand for datacenter GPUs. Several cloud providers and other enterprises have made substantial plans of growth in their datacenters to support these new workloads. One of the key bottleneck resources in datacenters is power, and given the increasing model sizes of LLMs, they are becoming increasingly power intensive. In this paper, we show that there is a significant opportunity to oversubscribe power in LLM clusters. Power oversubscription improves the power efficiency of these datacenters, allowing more deployable servers per datacenter, and reduces the deployment time, since building new datacenters is slow. We extensively characterize the power consumption patterns of a variety of LLMs and their configurations. We identify the differences between the inference and training power consumption patterns. Based on our analysis of these LLMs, we claim that the average and peak power utilization in LLM clusters for inference should not be very high. Our deductions align with the data from production LLM clusters, revealing that inference workloads offer substantial headroom for power oversubscription. However, the stringent set of telemetry and controls that GPUs offer in a virtualized environment, makes it challenging to have a reliable and robust power oversubscription mechanism. We propose POLCA, our framework for power oversubscription that is robust, reliable, and readily deployable for GPU clusters. Using open-source models to replicate the power patterns observed in production, we simulate POLCA and demonstrate that we can deploy 30% more servers in the same GPU cluster for inference, with minimal performance loss