 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Efficient Large Multimodal Model Serving
Feb 02, 2025Recent advances in generative AI have led to large multi-modal models (LMMs) capable of simultaneously processing inputs of various modalities such as text, images, video, and audio. While these models demonstrate impressive capabilities, efficiently serving them in production environments poses significant challenges due to their complex architectures and heterogeneous resource requirements. We present the first comprehensive systems analysis of two prominent LMM architectures, decoder-only and cross-attention, on six representative open-source models. We investigate their multi-stage inference pipelines and resource utilization patterns that lead to unique systems design implications. We also present an in-depth analysis of production LMM inference traces, uncovering unique workload characteristics, including variable, heavy-tailed request distributions, diverse modal combinations, and bursty traffic patterns. Our key findings reveal that different LMM inference stages exhibit highly heterogeneous performance characteristics and resource demands, while concurrent requests across modalities lead to significant performance interference. To address these challenges, we propose a decoupled serving architecture that enables independent resource allocation and adaptive scaling for each stage. We further propose optimizations such as stage colocation to maximize throughput and resource utilization while meeting the latency objectives.
Towards Resource-Efficient Compound AI Systems
Jan 29, 2025Compound AI Systems, integrating multiple interacting components like models, retrievers, and external tools, have emerged as essential for addressing complex AI tasks. However, current implementations suffer from inefficient resource utilization due to tight coupling between application logic and execution details, a disconnect between orchestration and resource management layers, and the perceived exclusiveness between efficiency and quality. We propose a vision for resource-efficient Compound AI Systems through a declarative workflow programming model and an adaptive runtime system for dynamic scheduling and resource-aware decision-making. Decoupling application logic from low-level details exposes levers for the runtime to flexibly configure the execution environment and resources, without compromising on quality. Enabling collaboration between the workflow orchestration and cluster manager enables higher efficiency through better scheduling and resource management. We are building a prototype system, called Murakkab, to realize this vision. Our preliminary evaluation demonstrates speedups up to $\sim 3.4\times$ in workflow completion times while delivering $\sim 4.5\times$ higher energy efficiency, showing promise in optimizing resources and advancing AI system design.
TAPAS: Thermal- and Power-Aware Scheduling for LLM Inference in Cloud Platforms
Jan 05, 2025



The rising demand for generative large language models (LLMs) poses challenges for thermal and power management in cloud datacenters. Traditional techniques often are inadequate for LLM inference due to the fine-grained, millisecond-scale execution phases, each with distinct performance, thermal, and power profiles. Additionally, LLM inference workloads are sensitive to various configuration parameters (e.g., model parallelism, size, and quantization) that involve trade-offs between performance, temperature, power, and output quality. Moreover, clouds often co-locate SaaS and IaaS workloads, each with different levels of visibility and flexibility. We propose TAPAS, a thermal- and power-aware framework designed for LLM inference clusters in the cloud. TAPAS enhances cooling and power oversubscription capabilities, reducing the total cost of ownership (TCO) while effectively handling emergencies (e.g., cooling and power failures). The system leverages historical temperature and power data, along with the adaptability of SaaS workloads, to: (1) efficiently place new GPU workload VMs within cooling and power constraints, (2) route LLM inference requests across SaaS VMs, and (3) reconfigure SaaS VMs to manage load spikes and emergency situations. Our evaluation on a large GPU cluster demonstrates significant reductions in thermal and power throttling events, boosting system efficiency.
Exploring LLM-based Agents for Root Cause Analysis
Mar 07, 2024The growing complexity of cloud based software systems has resulted in incident management becoming an integral part of the software development lifecycle. Root cause analysis (RCA), a critical part of the incident management process, is a demanding task for on-call engineers, requiring deep domain knowledge and extensive experience with a team's specific services. Automation of RCA can result in significant savings of time, and ease the burden of incident management on on-call engineers. Recently, researchers have utilized Large Language Models (LLMs) to perform RCA, and have demonstrated promising results. However, these approaches are not able to dynamically collect additional diagnostic information such as incident related logs, metrics or databases, severely restricting their ability to diagnose root causes. In this work, we explore the use of LLM based agents for RCA to address this limitation. We present a thorough empirical evaluation of a ReAct agent equipped with retrieval tools, on an out-of-distribution dataset of production incidents collected at Microsoft. Results show that ReAct performs competitively with strong retrieval and reasoning baselines, but with highly increased factual accuracy. We then extend this evaluation by incorporating discussions associated with incident reports as additional inputs for the models, which surprisingly does not yield significant performance improvements. Lastly, we conduct a case study with a team at Microsoft to equip the ReAct agent with tools that give it access to external diagnostic services that are used by the team for manual RCA. Our results show how agents can overcome the limitations of prior work, and practical considerations for implementing such a system in practice.
PACE-LM: Prompting and Augmentation for Calibrated Confidence Estimation with GPT-4 in Cloud Incident Root Cause Analysis
Sep 29, 2023Major cloud providers have employed advanced AI-based solutions like large language models to aid humans in identifying the root causes of cloud incidents. Despite the growing prevalence of AI-driven assistants in the root cause analysis process, their effectiveness in assisting on-call engineers is constrained by low accuracy due to the intrinsic difficulty of the task, a propensity for LLM-based approaches to hallucinate, and difficulties in distinguishing these well-disguised hallucinations. To address this challenge, we propose to perform confidence estimation for the predictions to help on-call engineers make decisions on whether to adopt the model prediction. Considering the black-box nature of many LLM-based root cause predictors, fine-tuning or temperature-scaling-based approaches are inapplicable. We therefore design an innovative confidence estimation framework based on prompting retrieval-augmented large language models (LLMs) that demand a minimal amount of information from the root cause predictor. This approach consists of two scoring phases: the LLM-based confidence estimator first evaluates its confidence in making judgments in the face of the current incident that reflects its ``grounded-ness" level in reference data, then rates the root cause prediction based on historical references. An optimization step combines these two scores for a final confidence assignment. We show that our method is able to produce calibrated confidence estimates for predicted root causes, validate the usefulness of retrieved historical data and the prompting strategy as well as the generalizability across different root cause prediction models. Our study takes an important move towards reliably and effectively embedding LLMs into cloud incident management systems.
Learning Search Space Partition for Black-box Optimization using Monte Carlo Tree Search
Jul 01, 2020

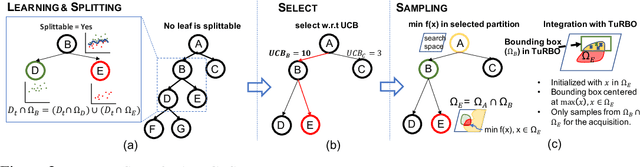
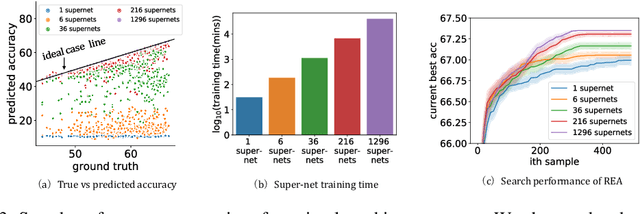
High dimensional black-box optimization has broad applications but remains a challenging problem to solve. Given a set of samples $\{\vx_i, y_i\}$, building a global model (like Bayesian Optimization (BO)) suffers from the curse of dimensionality in the high-dimensional search space, while a greedy search may lead to sub-optimality. By recursively splitting the search space into regions with high/low function values, recent works like LaNAS shows good performance in Neural Architecture Search (NAS), reducing the sample complexity empirically. In this paper, we coin LA-MCTS that extends LaNAS to other domains. Unlike previous approaches, LA-MCTS learns the partition of the search space using a few samples and their function values in an online fashion. While LaNAS uses linear partition and performs uniform sampling in each region, our LA-MCTS adopts a nonlinear decision boundary and learns a local model to pick good candidates. If the nonlinear partition function and the local model fits well with ground-truth black-box function, then good partitions and candidates can be reached with much fewer samples. LA-MCTS serves as a \emph{meta-algorithm} by using existing black-box optimizers (e.g., BO, TuRBO) as its local models, achieving strong performance in general black-box optimization and reinforcement learning benchmarks, in particular for high-dimensional problems.
Few-shot Neural Architecture Search
Jun 19, 2020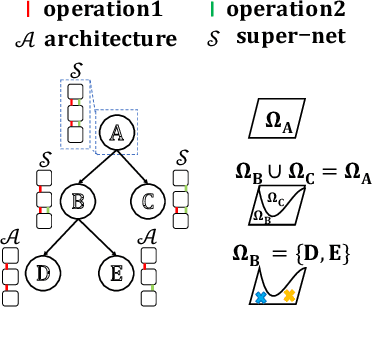
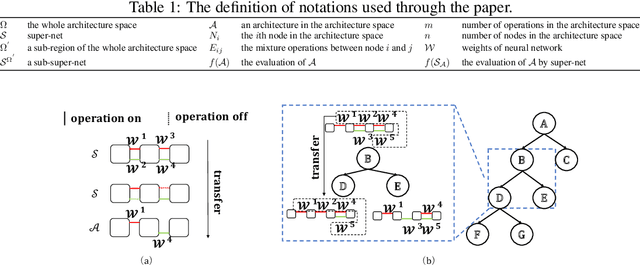
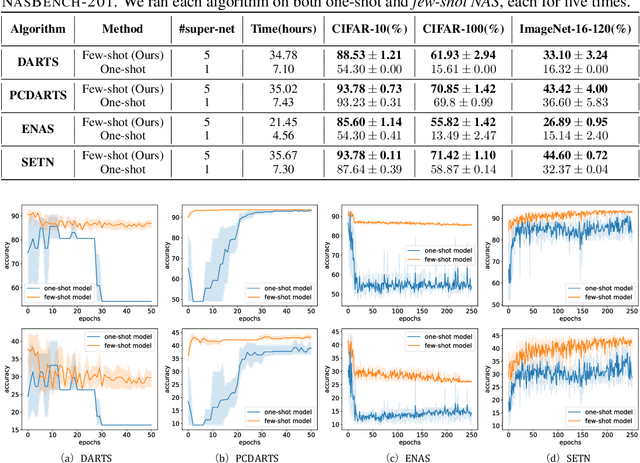
To improve the search efficiency for Neural Architecture Search (NAS), One-shot NAS proposes to train a single super-net to approximate the performance of proposal architectures during search via weight-sharing. While this greatly reduces the computation cost, due to approximation error, the performance prediction by a single super-net is less accurate than training each proposal architecture from scratch, leading to search inefficiency. In this work, we propose few-shot NAS that explores the choice of using multiple super-nets: each super-net is pre-trained to be in charge of a sub-region of the search space. This reduces the prediction error of each super-net. Moreover, training these super-nets can be done jointly via sequential fine-tuning. A natural choice of sub-region is to follow the splitting of search space in NAS. We empirically evaluate our approach on three different tasks in NAS-Bench-201. Extensive results have demonstrated that few-shot NAS, using only 5 super-nets, significantly improves performance of many search methods with slight increase of search time. The architectures found by DARTs and ENAS with few-shot models achieved 88.53% and 86.50% test accuracy on CIFAR-10 in NAS-Bench-201, significantly outperformed their one-shot counterparts (with 54.30% and 54.30% test accuracy). Moreover, on AUTOGAN and DARTS, few-shot NAS also outperforms previously state-of-the-art models.
Sample-Efficient Neural Architecture Search by Learning Action Space
Jun 17, 2019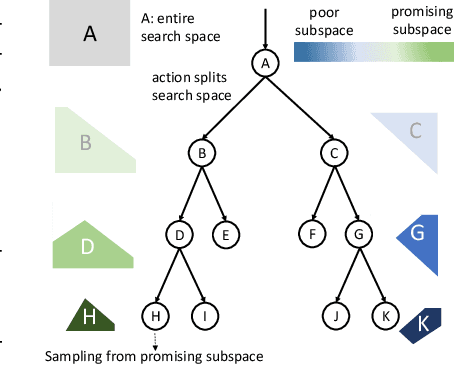
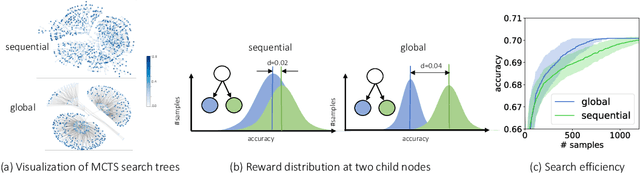
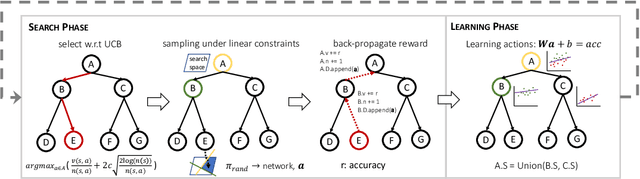
Neural Architecture Search (NAS) has emerged as a promising technique for automatic neural network design. However, existing NAS approaches often utilize manually designed action space, which is not directly related to the performance metric to be optimized (e.g., accuracy). As a result, using manually designed action space to perform NAS often leads to sample-inefficient explorations of architectures and thus can be sub-optimal. In order to improve sample efficiency, this paper proposes Latent Action Neural Architecture Search (LaNAS) that learns the action space to recursively partition the architecture search space into regions, each with concentrated performance metrics (\emph{i.e.}, low variance). During the search phase, as different architecture search action sequences lead to regions of different performance, the search efficiency can be significantly improved by biasing towards the regions with good performance. On the largest NAS dataset NasBench-101, our experimental results demonstrated that LaNAS is 22x, 14.6x and 12.4x more sample-efficient than random search, regularized evolution, and Monte Carlo Tree Search (MCTS) respectively. When applied to the open domain, LaNAS finds an architecture that achieves SoTA 98.0% accuracy on CIFAR-10 and 75.0% top1 accuracy on ImageNet (mobile setting), after exploring only 6,000 architectures.
AlphaX: eXploring Neural Architectures with Deep Neural Networks and Monte Carlo Tree Search
Mar 26, 2019
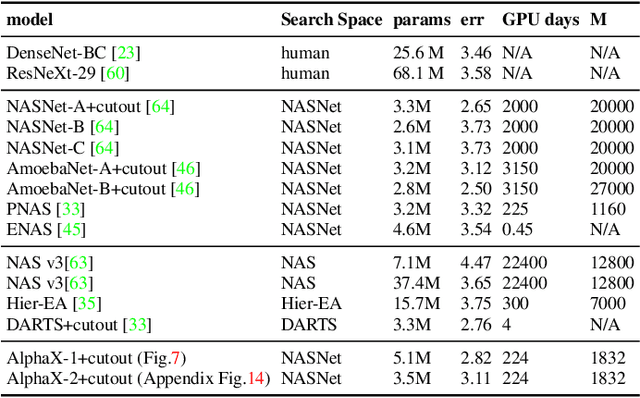
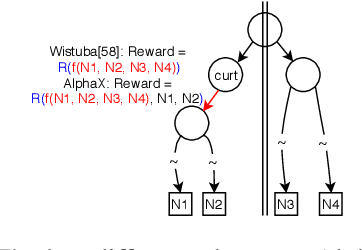
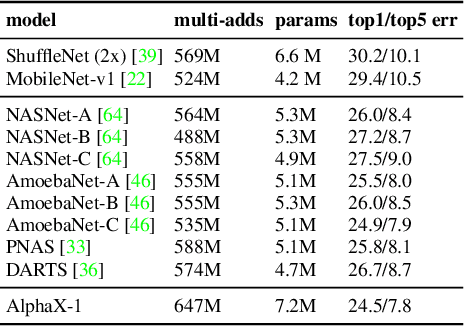
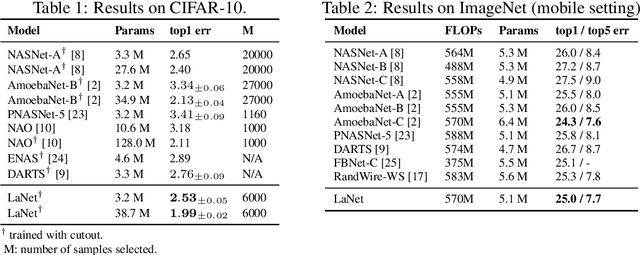
We present AlphaX, a fully automated agent that designs complex neural architectures from scratch. AlphaX explores the exponentially grown search space with a distributed Monte Carlo Tree Search (MCTS) and a Meta-Deep Neural Network (DNN). MCTS intrinsically improves the search efficiency by dynamically balancing the exploration and exploitation at fine-grained states, while Meta-DNN predicts the network accuracy to guide the search, and to provide an estimated reward to speed up the rollout. As the search progresses, AlphaX also generates the training data for Meta-DNN. So, the learning of Meta-DNN is end-to-end. In 14 days with only 16 GPUs (1832 samples), AlphaX found an architecture that reaches the state-of-the-art accuracies on both CIFAR-10(97.18%) and ImageNet(75.5% top-1 and 92.2% top-5). This demonstrates up to 10x speedup over the original searching for NASNet that used 500 GPUs in 4 days (20000 samples). On NASBench-101, AlphaX demonstrates 3x and 2.8x speedup over Random Search and Regularized Evolution. Finally, we show the searched architecture improves a variety of vision applications from Neural Style Transfer, to Image Captioning and Object Detection. Our implementation is available at https://github.com/linnanwang/AlphaX-NASBench101.
Scanning the Internet for ROS: A View of Security in Robotics Research
Jul 23, 2018


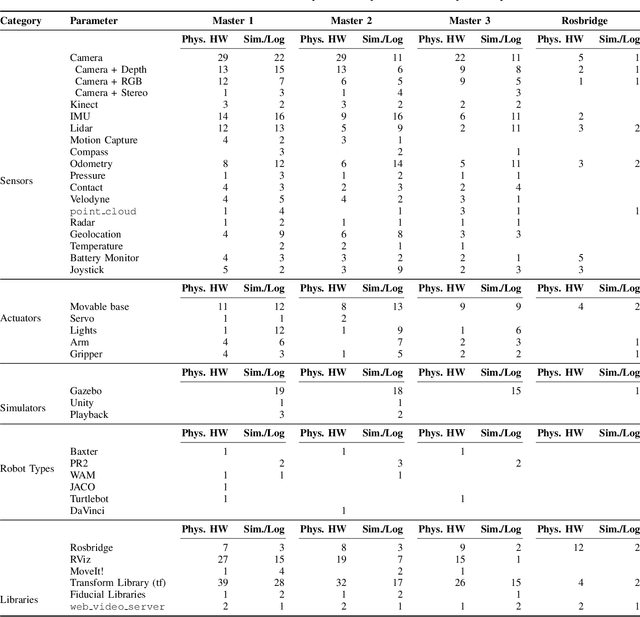
Because robots can directly perceive and affect the physical world, security issues take on particular importance. In this paper, we describe the results of our work on scanning the entire IPv4 address space of the Internet for instances of the Robot Operating System (ROS), a widely used robotics platform for research. Our results identified that a number of hosts supporting ROS are exposed to the public Internet, thereby allowing anyone to access robotic sensors and actuators. As a proof of concept, and with consent, we were able to read image sensor information and move the robot of a research group in a US university. This paper gives an overview of our findings, including the geographic distribution of publicly-accessible platforms, the sorts of sensor and actuator data that is available, as well as the different kinds of robots and sensors that our scan uncovered. Additionally, we offer recommendations on best practices to mitigate these security issues in the future.