 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-shot Neural Architecture Search
Paper and Code
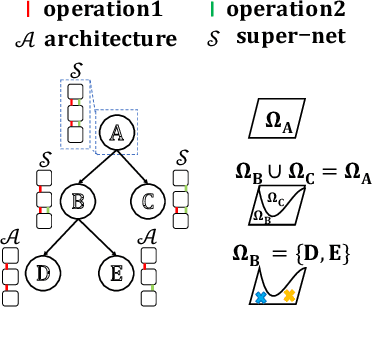
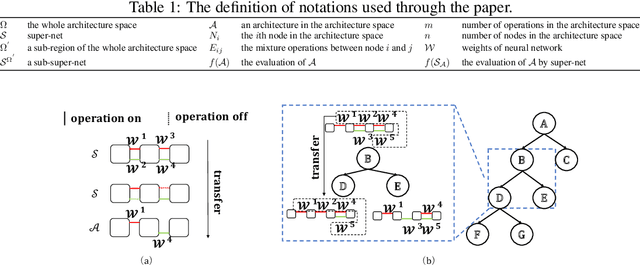
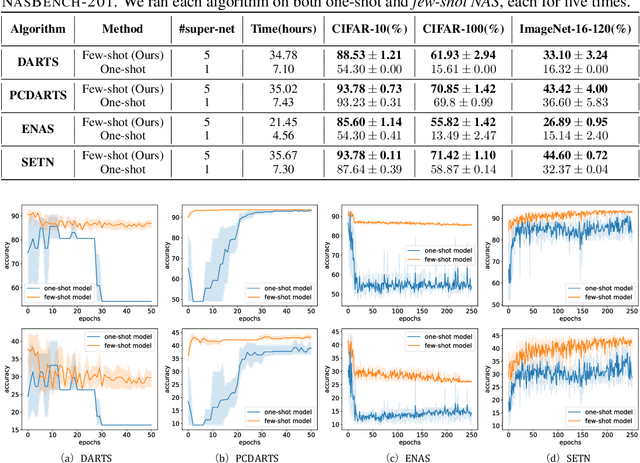
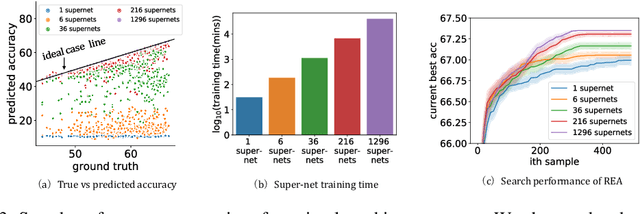
To improve the search efficiency for Neural Architecture Search (NAS), One-shot NAS proposes to train a single super-net to approximate the performance of proposal architectures during search via weight-sharing. While this greatly reduces the computation cost, due to approximation error, the performance prediction by a single super-net is less accurate than training each proposal architecture from scratch, leading to search inefficiency. In this work, we propose few-shot NAS that explores the choice of using multiple super-nets: each super-net is pre-trained to be in charge of a sub-region of the search space. This reduces the prediction error of each super-net. Moreover, training these super-nets can be done jointly via sequential fine-tuning. A natural choice of sub-region is to follow the splitting of search space in NAS. We empirically evaluate our approach on three different tasks in NAS-Bench-201. Extensive results have demonstrated that few-shot NAS, using only 5 super-nets, significantly improves performance of many search methods with slight increase of search time. The architectures found by DARTs and ENAS with few-shot models achieved 88.53% and 86.50% test accuracy on CIFAR-10 in NAS-Bench-201, significantly outperformed their one-shot counterparts (with 54.30% and 54.30% test accuracy). Moreover, on AUTOGAN and DARTS, few-shot NAS also outperforms previously state-of-the-art models.