 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta Learning for Few-Shot Medical Text Classification
Dec 03, 2022Medical professionals frequently work in a data constrained setting to provide insights across a unique demographic. A few medical observations, for instance, informs the diagnosis and treatment of a patient. This suggests a unique setting for meta-learning, a method to learn models quickly on new tasks, to provide insights unattainable by other methods. We investigate the use of meta-learning and robustness techniques on a broad corpus of benchmark text and medical data. To do this, we developed new data pipelines, combined language models with meta-learning approaches, and extended existing meta-learning algorithms to minimize worst case loss. We find that meta-learning on text is a suitable framework for text-based data, providing better data efficiency and comparable performance to few-shot language models and can be successfully applied to medical note data. Furthermore, meta-learning models coupled with DRO can improve worst case loss across disease codes.
Singularity: Planet-Scale, Preemptive and Elastic Scheduling of AI Workloads
Feb 21, 2022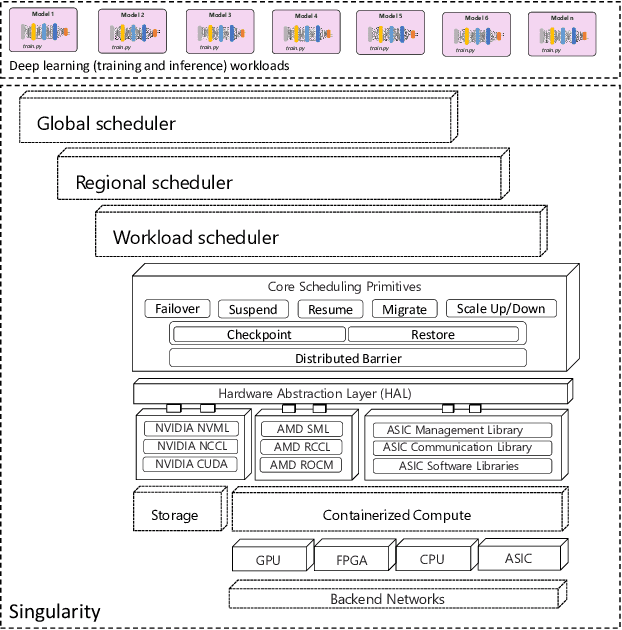
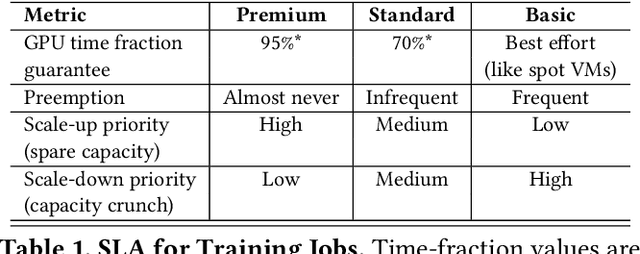
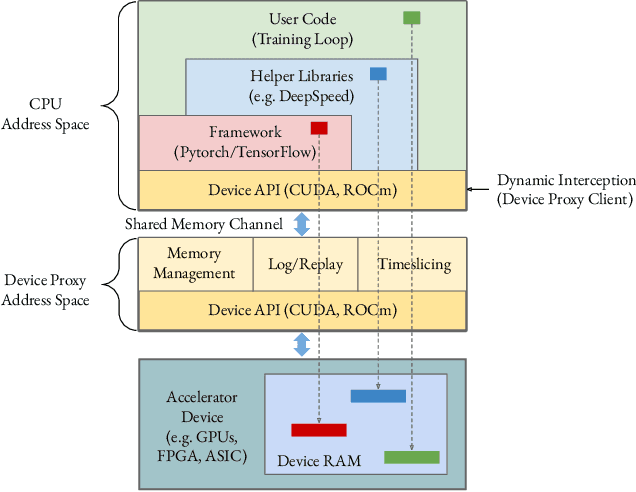
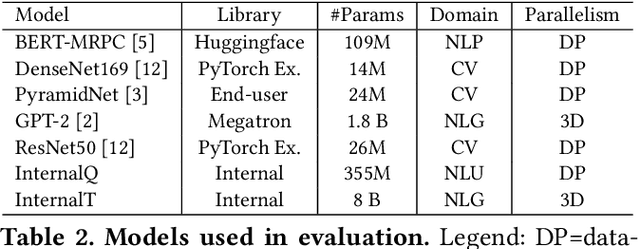
Lowering costs by driving high utilization across deep learning workloads is a crucial lever for cloud providers. We present Singularity, Microsoft's globally distributed scheduling service for highly-efficient and reliable execution of deep learning training and inference workloads. At the heart of Singularity is a novel, workload-aware scheduler that can transparently preempt and elastically scale deep learning workloads to drive high utilization without impacting their correctness or performance, across a global fleet of AI accelerators (e.g., GPUs, FPGAs). All jobs in Singularity are preemptable, migratable, and dynamically resizable (elastic) by default: a live job can be dynamically and transparently (a) preempted and migrated to a different set of nodes, cluster, data center or a region and resumed exactly from the point where the execution was preempted, and (b) resized (i.e., elastically scaled-up/down) on a varying set of accelerators of a given type. Our mechanisms are transparent in that they do not require the user to make any changes to their code or require using any custom libraries that may limit flexibility. Additionally, our approach significantly improves the reliability of deep learning workloads. We show that the resulting efficiency and reliability gains with Singularity are achieved with negligible impact on the steady-state performance. Finally, our design approach is agnostic of DNN architectures and handles a variety of parallelism strategies (e.g., data/pipeline/model parallelism).