 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe intersection of video capsule endoscopy and artificial intelligence: addressing unique challenges using machine learning
Aug 24, 2023



Introduction: Technical burdens and time-intensive review processes limit the practical utility of video capsule endoscopy (VCE). Artificial intelligence (AI) is poised to address these limitations, but the intersection of AI and VCE reveals challenges that must first be overcome. We identified five challenges to address. Challenge #1: VCE data are stochastic and contains significant artifact. Challenge #2: VCE interpretation is cost-intensive. Challenge #3: VCE data are inherently imbalanced. Challenge #4: Existing VCE AIMLT are computationally cumbersome. Challenge #5: Clinicians are hesitant to accept AIMLT that cannot explain their process. Methods: An anatomic landmark detection model was used to test the application of convolutional neural networks (CNNs) to the task of classifying VCE data. We also created a tool that assists in expert annotation of VCE data. We then created more elaborate models using different approaches including a multi-frame approach, a CNN based on graph representation, and a few-shot approach based on meta-learning. Results: When used on full-length VCE footage, CNNs accurately identified anatomic landmarks (99.1%), with gradient weighted-class activation mapping showing the parts of each frame that the CNN used to make its decision. The graph CNN with weakly supervised learning (accuracy 89.9%, sensitivity of 91.1%), the few-shot model (accuracy 90.8%, precision 91.4%, sensitivity 90.9%), and the multi-frame model (accuracy 97.5%, precision 91.5%, sensitivity 94.8%) performed well. Discussion: Each of these five challenges is addressed, in part, by one of our AI-based models. Our goal of producing high performance using lightweight models that aim to improve clinician confidence was achieved.
Lesion2Vec: Deep Metric Learning for Few-Shot Multiple Lesions Recognition in Wireless Capsule Endoscopy Video
Jan 15, 2021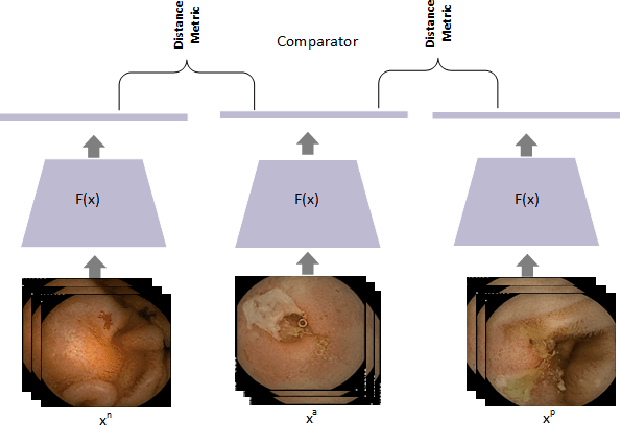
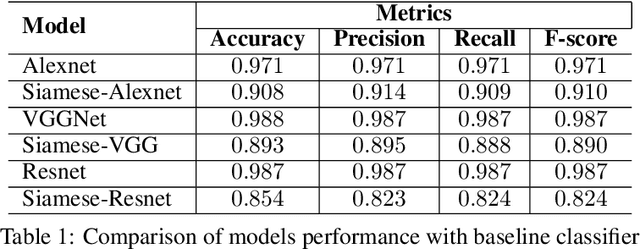
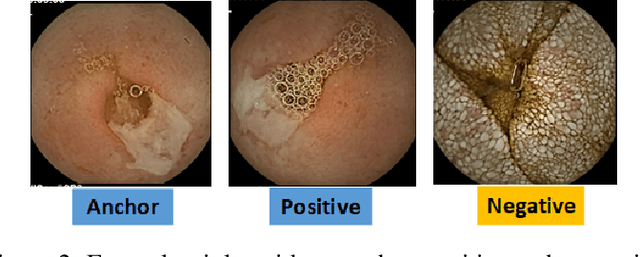
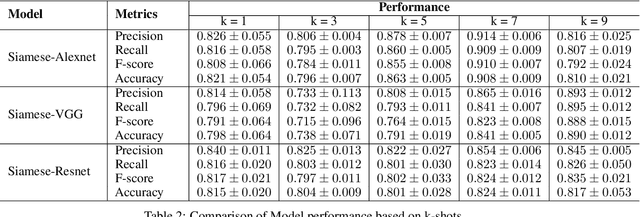
Effective and rapid detection of lesions in the Gastrointestinal tract is critical to gastroenterologist's response to some life-threatening diseases. Wireless Capsule Endoscopy (WCE) has revolutionized traditional endoscopy procedure by allowing gastroenterologists visualize the entire GI tract non-invasively. Once the tiny capsule is swallowed, it sequentially capture images of the GI tract at about 2 to 6 frames per second (fps). A single video can last up to 8 hours producing between 30,000 to 100,000 images. Automating the detection of frames containing specific lesion in WCE video would relieve gastroenterologists the arduous task of reviewing the entire video before making diagnosis. While the WCE produces large volume of images, only about 5\% of the frames contain lesions that aid the diagnosis process. Convolutional Neural Network (CNN) based models have been very successful in various image classification tasks. However, they suffer excessive parameters, are sample inefficient and rely on very large amount of training data. Deploying a CNN classifier for lesion detection task will require time-to-time fine-tuning to generalize to any unforeseen category. In this paper, we propose a metric-based learning framework followed by a few-shot lesion recognition in WCE data. Metric-based learning is a meta-learning framework designed to establish similarity or dissimilarity between concepts while few-shot learning (FSL) aims to identify new concepts from only a small number of examples. We train a feature extractor to learn a representation for different small bowel lesions using metric-based learning. At the testing stage, the category of an unseen sample is predicted from only a few support examples, thereby allowing the model to generalize to a new category that has never been seen before. We demonstrated the efficacy of this method on real patient capsule endoscopy data.