 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExamining Vision Language Models through Multi-dimensional Experiments with Vision and Text Features
Sep 10, 2025Recent research on Vision Language Models (VLMs) suggests that they rely on inherent biases learned during training to respond to questions about visual properties of an image. These biases are exacerbated when VLMs are asked highly specific questions that require focusing on specific areas of the image. For example, a VLM tasked with counting stars on a modified American flag (e.g., with more than 50 stars) will often disregard the visual evidence and fail to answer accurately. We build upon this research and develop a multi-dimensional examination framework to systematically determine which characteristics of the input data, including both the image and the accompanying prompt, lead to such differences in performance. Using open-source VLMs, we further examine how attention values fluctuate with varying input parameters (e.g., image size, number of objects in the image, background color, prompt specificity). This research aims to learn how the behavior of vision language models changes and to explore methods for characterizing such changes. Our results suggest, among other things, that even minor modifications in image characteristics and prompt specificity can lead to large changes in how a VLM formulates its answer and, subsequently, its overall performance.
Towards Robust Multimodal Representation: A Unified Approach with Adaptive Experts and Alignment
Mar 12, 2025Healthcare relies on multiple types of data, such as medical images, genetic information, and clinical records, to improve diagnosis and treatment. However, missing data is a common challenge due to privacy restrictions, cost, and technical issues, making many existing multi-modal models unreliable. To address this, we propose a new multi-model model called Mixture of Experts, Symmetric Aligning, and Reconstruction (MoSARe), a deep learning framework that handles incomplete multimodal data while maintaining high accuracy. MoSARe integrates expert selection, cross-modal attention, and contrastive learning to improve feature representation and decision-making. Our results show that MoSARe outperforms existing models in situations when the data is complete. Furthermore, it provides reliable predictions even when some data are missing. This makes it especially useful in real-world healthcare settings, including resource-limited environments. Our code is publicly available at https://github.com/NazaninMn/MoSARe.
GenGMM: Generalized Gaussian-Mixture-based Domain Adaptation Model for Semantic Segmentation
Oct 21, 2024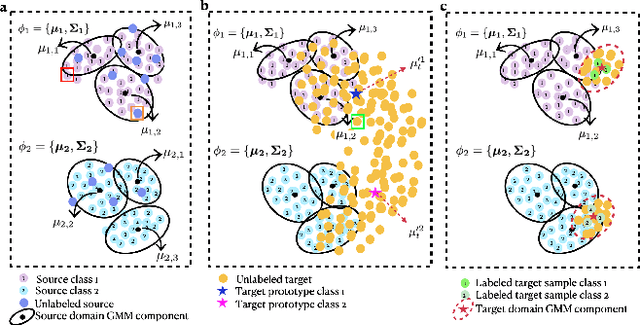


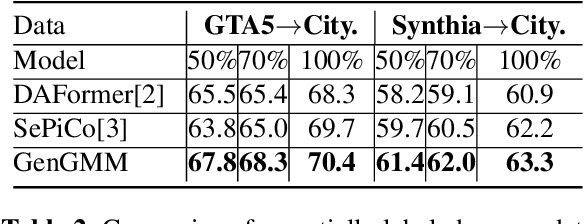
Domain adaptive semantic segmentation is the task of generating precise and dense predictions for an unlabeled target domain using a model trained on a labeled source domain. While significant efforts have been devoted to improving unsupervised domain adaptation for this task, it is crucial to note that many models rely on a strong assumption that the source data is entirely and accurately labeled, while the target data is unlabeled. In real-world scenarios, however, we often encounter partially or noisy labeled data in source and target domains, referred to as Generalized Domain Adaptation (GDA). In such cases, we suggest leveraging weak or unlabeled data from both domains to narrow the gap between them, resulting in effective adaptation. We introduce the Generalized Gaussian-mixture-based (GenGMM) domain adaptation model, which harnesses the underlying data distribution in both domains to refine noisy weak and pseudo labels. The experiments demonstrate the effectiveness of our approach.
ProtoGMM: Multi-prototype Gaussian-Mixture-based Domain Adaptation Model for Semantic Segmentation
Jun 27, 2024



Domain adaptive semantic segmentation aims to generate accurate and dense predictions for an unlabeled target domain by leveraging a supervised model trained on a labeled source domain. The prevalent self-training approach involves retraining the dense discriminative classifier of $p(class|pixel feature)$ using the pseudo-labels from the target domain. While many methods focus on mitigating the issue of noisy pseudo-labels, they often overlook the underlying data distribution p(pixel feature|class) in both the source and target domains. To address this limitation, we propose the multi-prototype Gaussian-Mixture-based (ProtoGMM) model, which incorporates the GMM into contrastive losses to perform guided contrastive learning. Contrastive losses are commonly executed in the literature using memory banks, which can lead to class biases due to underrepresented classes. Furthermore, memory banks often have fixed capacities, potentially restricting the model's ability to capture diverse representations of the target/source domains. An alternative approach is to use global class prototypes (i.e. averaged features per category). However, the global prototypes are based on the unimodal distribution assumption per class, disregarding within-class variation. To address these challenges, we propose the ProtoGMM model. This novel approach involves estimating the underlying multi-prototype source distribution by utilizing the GMM on the feature space of the source samples. The components of the GMM model act as representative prototypes. To achieve increased intra-class semantic similarity, decreased inter-class similarity, and domain alignment between the source and target domains, we employ multi-prototype contrastive learning between source distribution and target samples. The experiments show the effectiveness of our method on UDA benchmarks.
Label-efficient Contrastive Learning-based model for nuclei detection and classification in 3D Cardiovascular Immunofluorescent Images
Sep 08, 2023



Recently, deep learning-based methods achieved promising performance in nuclei detection and classification applications. However, training deep learning-based methods requires a large amount of pixel-wise annotated data, which is time-consuming and labor-intensive, especially in 3D images. An alternative approach is to adapt weak-annotation methods, such as labeling each nucleus with a point, but this method does not extend from 2D histopathology images (for which it was originally developed) to 3D immunofluorescent images. The reason is that 3D images contain multiple channels (z-axis) for nuclei and different markers separately, which makes training using point annotations difficult. To address this challenge, we propose the Label-efficient Contrastive learning-based (LECL) model to detect and classify various types of nuclei in 3D immunofluorescent images. Previous methods use Maximum Intensity Projection (MIP) to convert immunofluorescent images with multiple slices to 2D images, which can cause signals from different z-stacks to falsely appear associated with each other. To overcome this, we devised an Extended Maximum Intensity Projection (EMIP) approach that addresses issues using MIP. Furthermore, we performed a Supervised Contrastive Learning (SCL) approach for weakly supervised settings. We conducted experiments on cardiovascular datasets and found that our proposed framework is effective and efficient in detecting and classifying various types of nuclei in 3D immunofluorescent images.
Weakly Supervised Deep Instance Nuclei Detection using Points Annotation in 3D Cardiovascular Immunofluorescent Images
Jul 29, 2022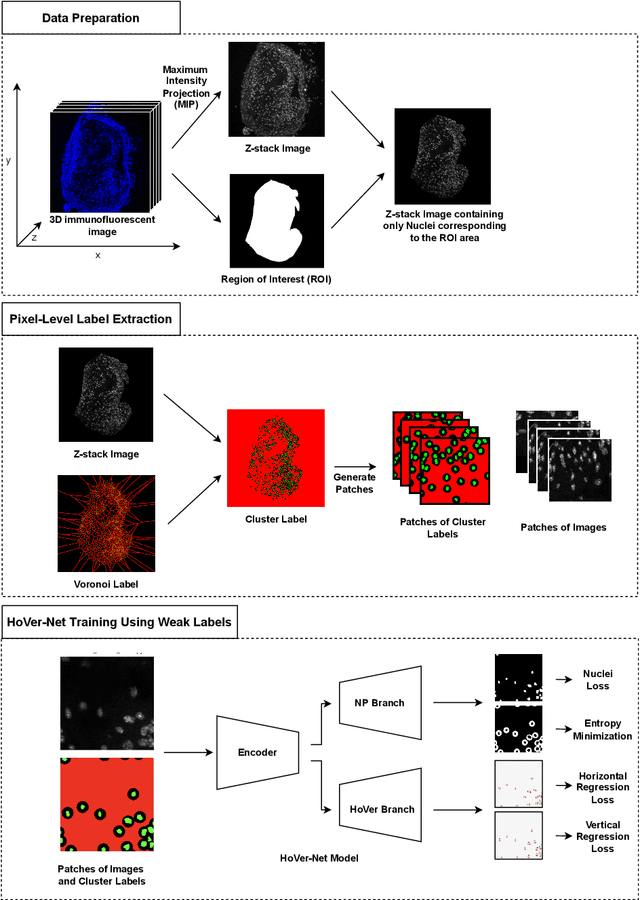


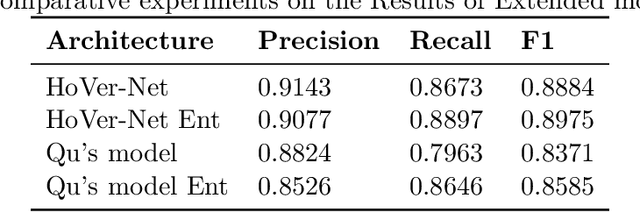
Two major causes of death in the United States and worldwide are stroke and myocardial infarction. The underlying cause of both is thrombi released from ruptured or eroded unstable atherosclerotic plaques that occlude vessels in the heart (myocardial infarction) or the brain (stroke). Clinical studies show that plaque composition plays a more important role than lesion size in plaque rupture or erosion events. To determine the plaque composition, various cell types in 3D cardiovascular immunofluorescent images of plaque lesions are counted. However, counting these cells manually is expensive, time-consuming, and prone to human error. These challenges of manual counting motivate the need for an automated approach to localize and count the cells in images. The purpose of this study is to develop an automatic approach to accurately detect and count cells in 3D immunofluorescent images with minimal annotation effort. In this study, we used a weakly supervised learning approach to train the HoVer-Net segmentation model using point annotations to detect nuclei in fluorescent images. The advantage of using point annotations is that they require less effort as opposed to pixel-wise annotation. To train the HoVer-Net model using point annotations, we adopted a popularly used cluster labeling approach to transform point annotations into accurate binary masks of cell nuclei. Traditionally, these approaches have generated binary masks from point annotations, leaving a region around the object unlabeled (which is typically ignored during model training). However, these areas may contain important information that helps determine the boundary between cells. Therefore, we used the entropy minimization loss function in these areas to encourage the model to output more confident predictions on the unlabeled areas. Our comparison studies indicate that the HoVer-Net model trained using our weakly ...
Universal Hysteresis Identification Using Extended Preisach Neural Network
Dec 22, 2019
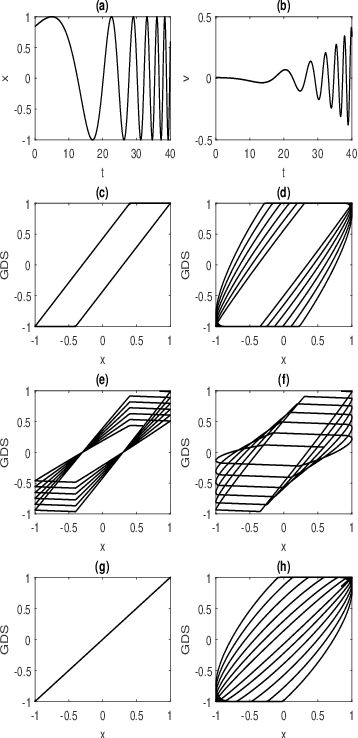
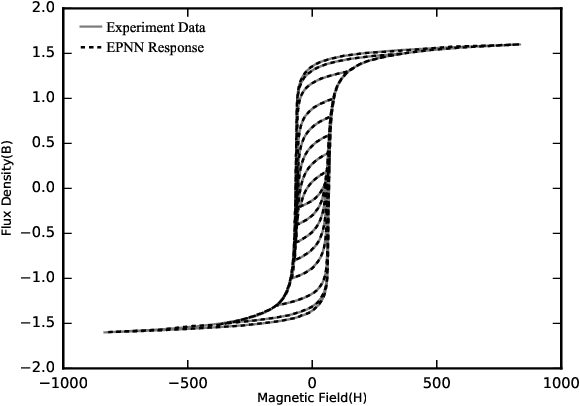
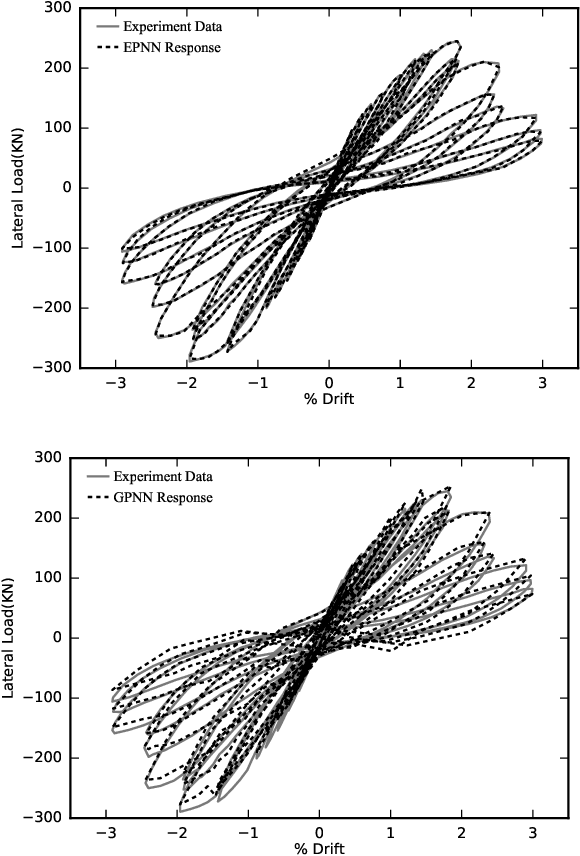
Hysteresis phenomena have been observed in different branches of physics and engineering sciences. Therefore, several models have been proposed for hysteresis simulation in different fields; however, almost neither of them can be utilized universally. In this paper by inspiring of Preisach Neural Network which was inspired by the Preisach model that basically stemmed from Madelungs rules and using the learning capability of the neural networks, an adaptive universal model for hysteresis is introduced and called Extended Preisach Neural Network Model. It is comprised of input, output and, two hidden layers. The input and output layers contain linear neurons while the first hidden layer incorporates neurons called Deteriorating Stop neurons, which their activation function follows Deteriorating Stop operator. Deteriorating Stop operators can generate non-congruent hysteresis loops. The second hidden layer includes Sigmoidal neurons. Adding the second hidden layer, helps the neural network learn non-Masing and asymmetric hysteresis loops very smoothly. At the input layer, besides input data the rate at which input data changes, is included as well in order to give the model the capability of learning rate-dependent hysteresis loops. Hence, the proposed approach has the capability of the simulation of both rate-independent and rate-dependent hysteresis with either congruent or non-congruent loops as well as symmetric and asymmetric loops. A new hybridized algorithm has been adopted for training the model which is based on a combination of the Genetic Algorithm and the optimization method of sub-gradient with space dilatation. The generality of the proposed model has been evaluated by applying it to various hysteresis from different areas of engineering with different characteristics. The results show that the model is successful in the identification of the considered hystereses.