 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenGMM: Generalized Gaussian-Mixture-based Domain Adaptation Model for Semantic Segmentation
Paper and Code
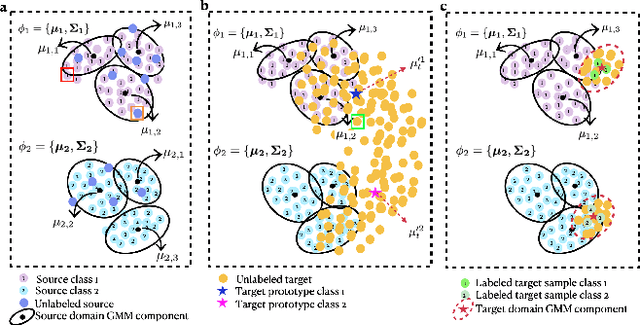


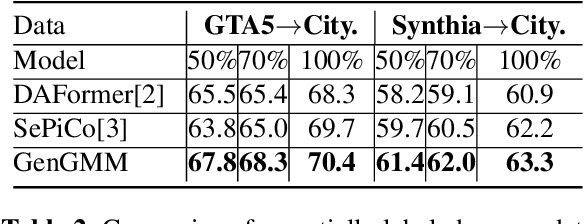
Domain adaptive semantic segmentation is the task of generating precise and dense predictions for an unlabeled target domain using a model trained on a labeled source domain. While significant efforts have been devoted to improving unsupervised domain adaptation for this task, it is crucial to note that many models rely on a strong assumption that the source data is entirely and accurately labeled, while the target data is unlabeled. In real-world scenarios, however, we often encounter partially or noisy labeled data in source and target domains, referred to as Generalized Domain Adaptation (GDA). In such cases, we suggest leveraging weak or unlabeled data from both domains to narrow the gap between them, resulting in effective adaptation. We introduce the Generalized Gaussian-mixture-based (GenGMM) domain adaptation model, which harnesses the underlying data distribution in both domains to refine noisy weak and pseudo labels. The experiments demonstrate the effectiveness of our approach.