 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Knowledge Discovery Framework for Data Science Job Market in the United States
Jun 14, 2021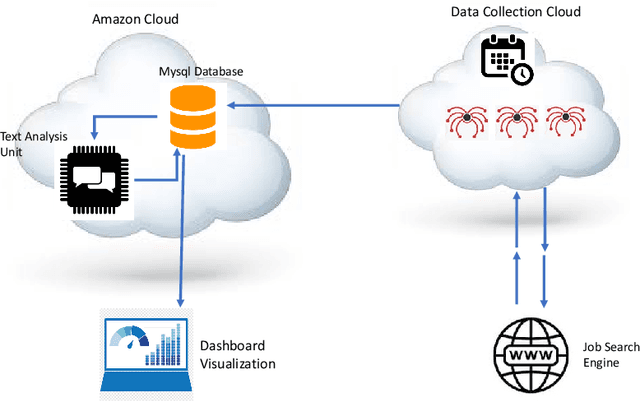
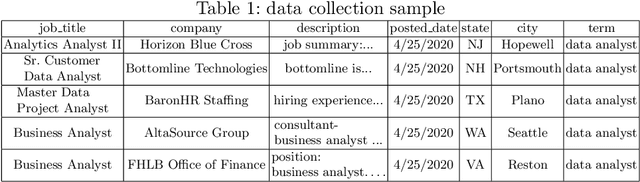
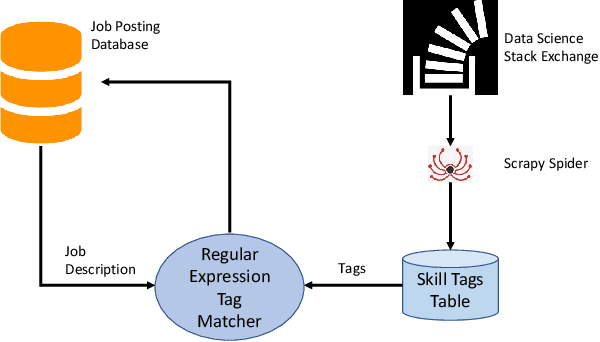
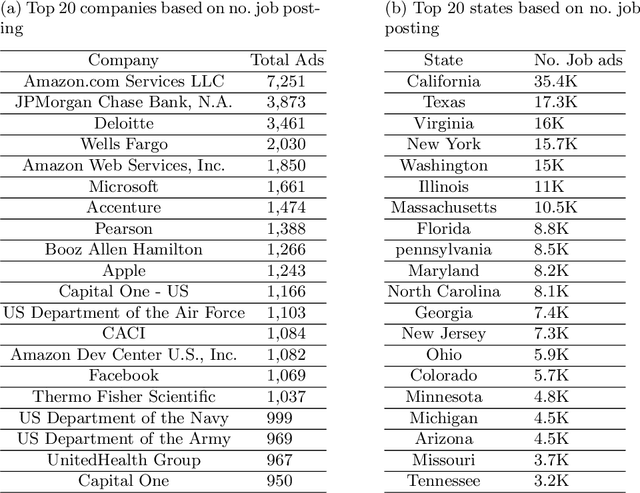
The growth of the data science field requires better tools to understand such a fast-paced growing domain. Moreover, individuals from different backgrounds became interested in following a career as data scientists. Therefore, providing a quantitative guide for individuals and organizations to understand the skills required in the job market would be crucial. This paper introduces a framework to analyze the job market for data science-related jobs within the US while providing an interface to access insights in this market. The proposed framework includes three sub-modules allowing continuous data collection, information extraction, and a web-based dashboard visualization to investigate the spatial and temporal distribution of data science-related jobs and skills. The result of this work shows important skills for the main branches of data science jobs and attempts to provide a skill-based definition of these data science branches. The current version of this application is deployed on the web and allows individuals and institutes to investigate skills required for data science positions through the industry lens.
Gender Detection on Social Networks using Ensemble Deep Learning
Apr 13, 2020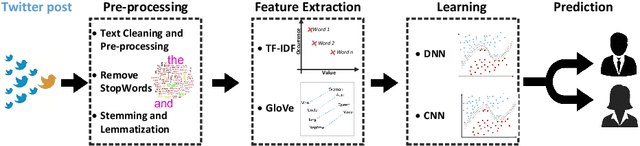
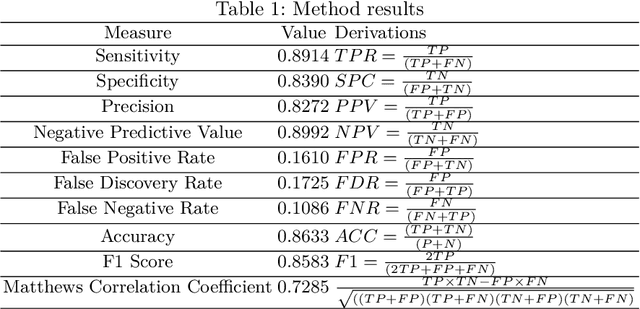


Analyzing the ever-increasing volume of posts on social media sites such as Facebook and Twitter requires improved information processing methods for profiling authorship. Document classification is central to this task, but the performance of traditional supervised classifiers has degraded as the volume of social media has increased. This paper addresses this problem in the context of gender detection through ensemble classification that employs multi-model deep learning architectures to generate specialized understanding from different feature spaces.
Women in ISIS Propaganda: A Natural Language Processing Analysis of Topics and Emotions in a Comparison with Mainstream Religious Group
Dec 09, 2019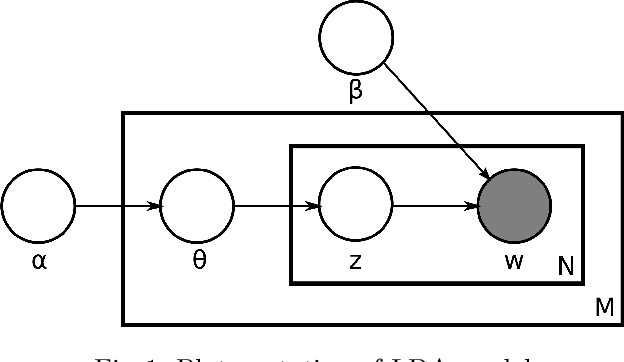

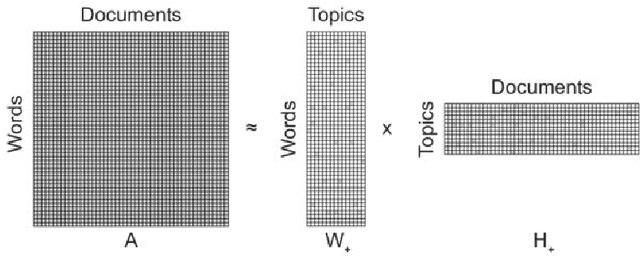

Online propaganda is central to the recruitment strategies of extremist groups and in recent years these efforts have increasingly extended to women. To investigate ISIS' approach to targeting women in their online propaganda and uncover implications for counterterrorism, we rely on text mining and natural language processing (NLP). Specifically, we extract articles published in Dabiq and Rumiyah (ISIS's online English language publications) to identify prominent topics. To identify similarities or differences between these texts and those produced by non-violent religious groups, we extend the analysis to articles from a Catholic forum dedicated to women. We also perform an emotional analysis of both of these resources to better understand the emotional components of propaganda. We rely on Depechemood (a lexical-base emotion analysis method) to detect emotions most likely to be evoked in readers of these materials. The findings indicate that the emotional appeal of ISIS and Catholic materials are similar
Text Classification Algorithms: A Survey
Apr 25, 2019
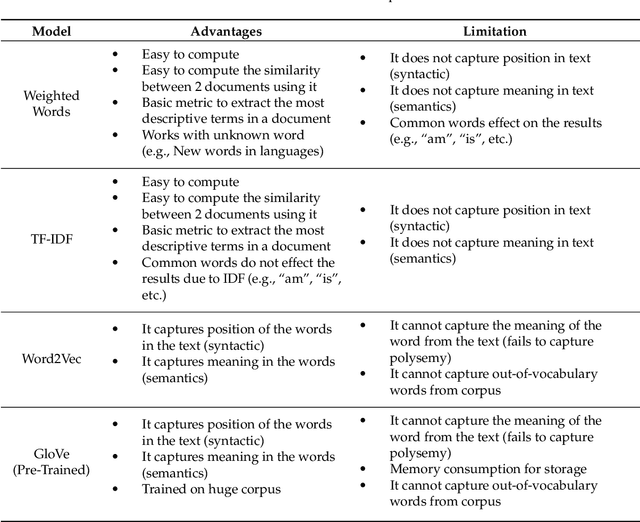
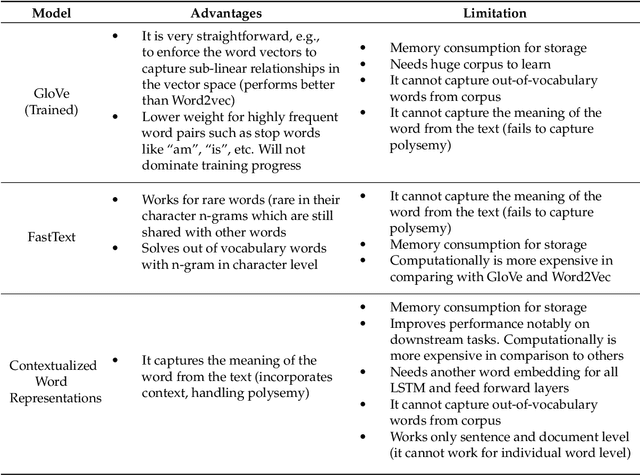
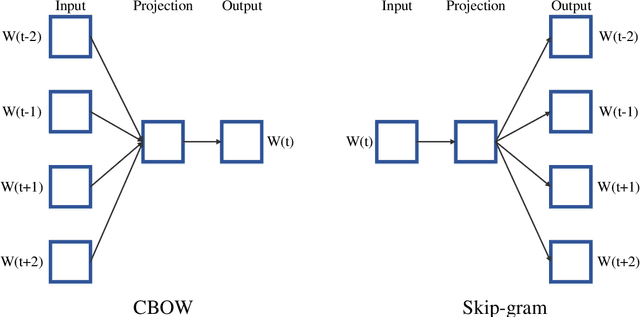
In recent years, there has been an exponential growth in the number of complex documents and texts that require a deeper understanding of machine learning methods to be able to accurately classify texts in many applications. Many machine learning approaches have achieved surpassing results in natural language processing. The success of these learning algorithms relies on their capacity to understand complex models and non-linear relationships within data. However, finding suitable structures, architectures, and techniques for text classification is a challenge for researchers. In this paper, a brief overview of text classification algorithms is discussed. This overview covers different text feature extractions, dimensionality reduction methods, existing algorithms and techniques, and evaluations methods. Finally, the limitations of each technique and their application in the real-world problem are discussed.
From Videos to URLs: A Multi-Browser Guide To Extract User's Behavior with Optical Character Recognition
Nov 15, 2018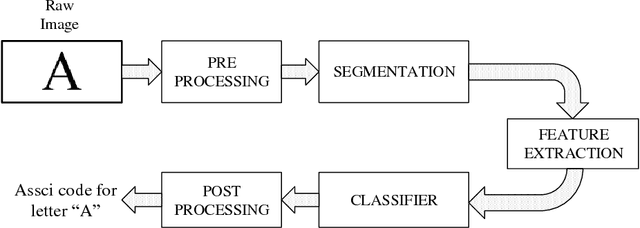
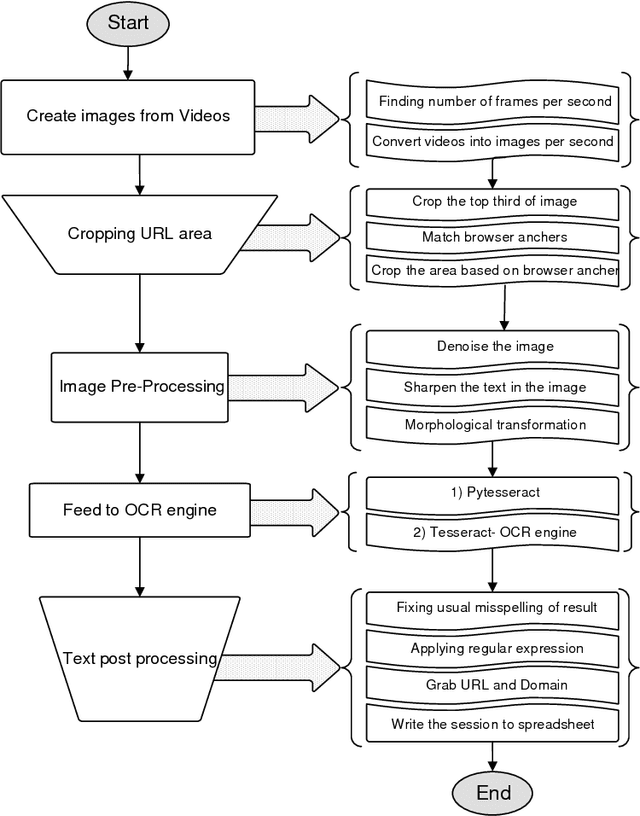

Tracking users' activities on the World Wide Web (WWW) allows researchers to analyze each user's internet behavior as time passes and for the amount of time spent on a particular domain. This analysis can be used in research design, as researchers may access to their participant's behaviors while browsing the web. Web search behavior has been a subject of interest because of its real-world applications in marketing, digital advertisement, and identifying potential threats online. In this paper, we present an image-processing based method to extract domains which are visited by a participant over multiple browsers during a lab session. This method could provide another way to collect users' activities during an online session given that the session recorder collected the data. The method can also be used to collect the textual content of web-pages that an individual visits for later analysis
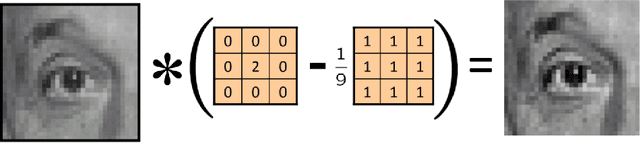
Analysis of Railway Accidents' Narratives Using Deep Learning
Oct 17, 2018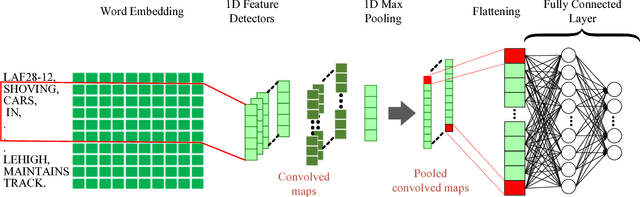

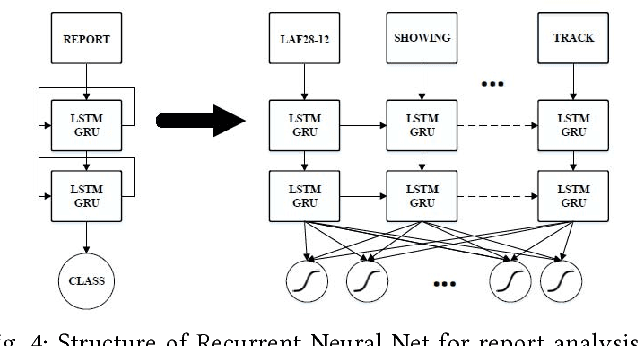
Automatic understanding of domain specific texts in order to extract useful relationships for later use is a non-trivial task. One such relationship would be between railroad accidents' causes and their correspondent descriptions in reports. From 2001 to 2016 rail accidents in the U.S. cost more than $4.6B. Railroads involved in accidents are required to submit an accident report to the Federal Railroad Administration (FRA). These reports contain a variety of fixed field entries including primary cause of the accidents (a coded variable with 389 values) as well as a narrative field which is a short text description of the accident. Although these narratives provide more information than a fixed field entry, the terminologies used in these reports are not easy to understand by a non-expert reader. Therefore, providing an assisting method to fill in the primary cause from such domain specific texts(narratives) would help to label the accidents with more accuracy. Another important question for transportation safety is whether the reported accident cause is consistent with narrative description. To address these questions, we applied deep learning methods together with powerful word embeddings such as Word2Vec and GloVe to classify accident cause values for the primary cause field using the text in the narratives. The results show that such approaches can both accurately classify accident causes based on report narratives and find important inconsistencies in accident reporting.
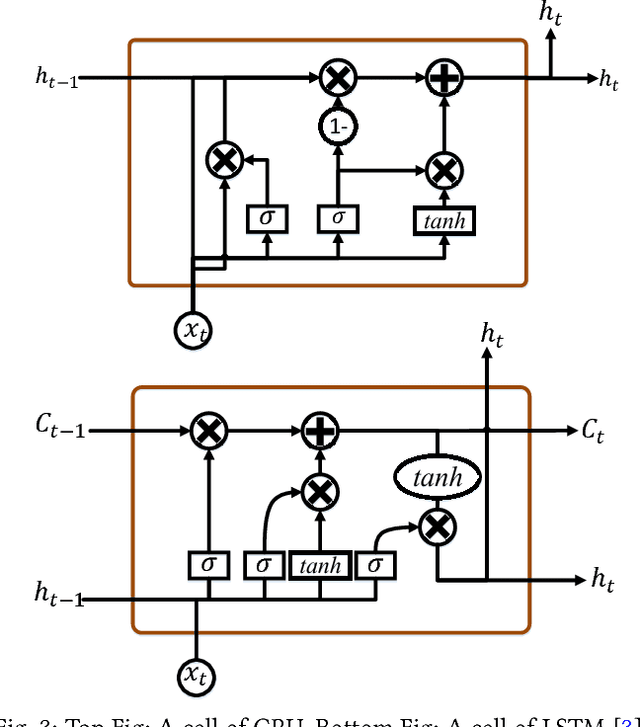
An Improvement of Data Classification Using Random Multimodel Deep Learning (RMDL)
Aug 23, 2018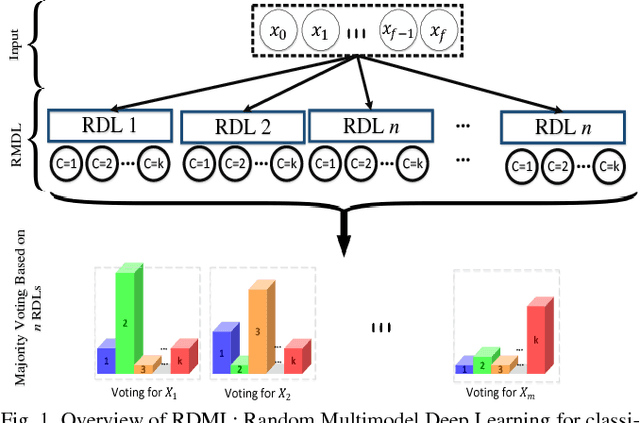
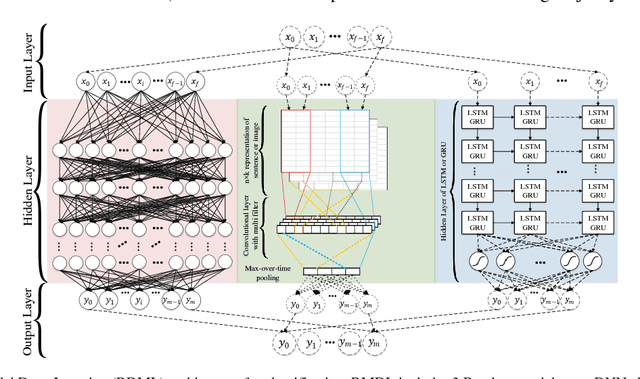
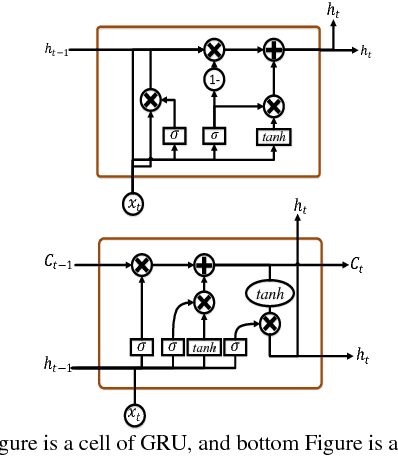

The exponential growth in the number of complex datasets every year requires more enhancement in machine learning methods to provide robust and accurate data classification. Lately, deep learning approaches have achieved surpassing results in comparison to previous machine learning algorithms. However, finding the suitable structure for these models has been a challenge for researchers. This paper introduces Random Multimodel Deep Learning (RMDL): a new ensemble, deep learning approach for classification. RMDL solves the problem of finding the best deep learning structure and architecture while simultaneously improving robustness and accuracy through ensembles of deep learning architectures. In short, RMDL trains multiple randomly generated models of Deep Neural Network (DNN), Convolutional Neural Network (CNN) and Recurrent Neural Network (RNN) in parallel and combines their results to produce better result of any of those models individually. In this paper, we describe RMDL model and compare the results for image and text classification as well as face recognition. We used MNIST and CIFAR-10 datasets as ground truth datasets for image classification and WOS, Reuters, IMDB, and 20newsgroup datasets for text classification. Lastly, we used ORL dataset to compare the model performance on face recognition task.
RMDL: Random Multimodel Deep Learning for Classification
May 31, 2018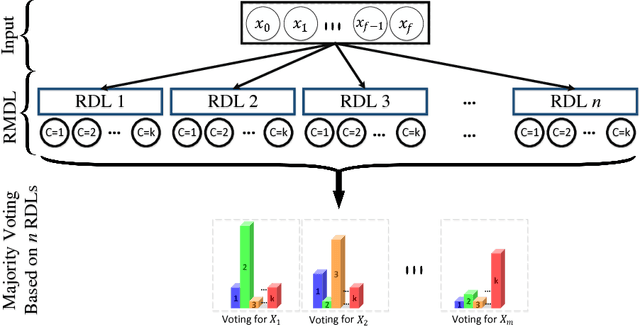
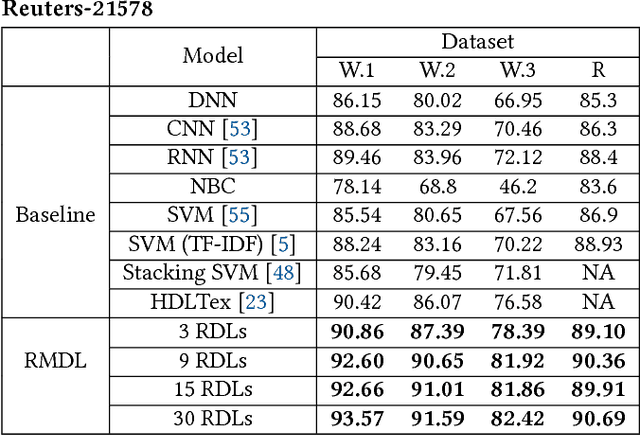

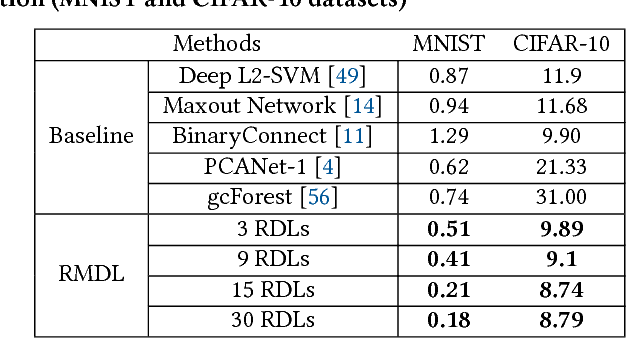
The continually increasing number of complex datasets each year necessitates ever improving machine learning methods for robust and accurate categorization of these data. This paper introduces Random Multimodel Deep Learning (RMDL): a new ensemble, deep learning approach for classification. Deep learning models have achieved state-of-the-art results across many domains. RMDL solves the problem of finding the best deep learning structure and architecture while simultaneously improving robustness and accuracy through ensembles of deep learning architectures. RDML can accept as input a variety data to include text, video, images, and symbolic. This paper describes RMDL and shows test results for image and text data including MNIST, CIFAR-10, WOS, Reuters, IMDB, and 20newsgroup. These test results show that RDML produces consistently better performance than standard methods over a broad range of data types and classification problems.
HDLTex: Hierarchical Deep Learning for Text Classification
Oct 06, 2017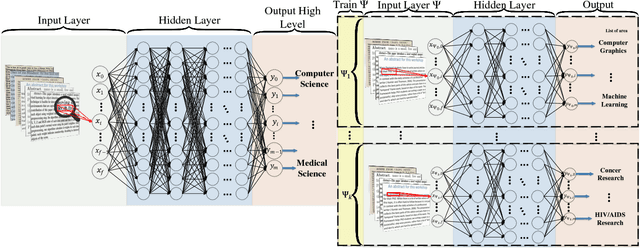
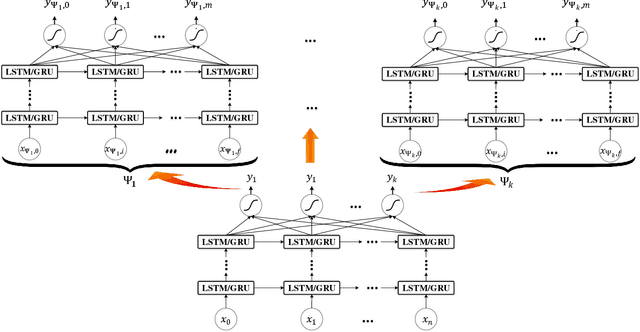
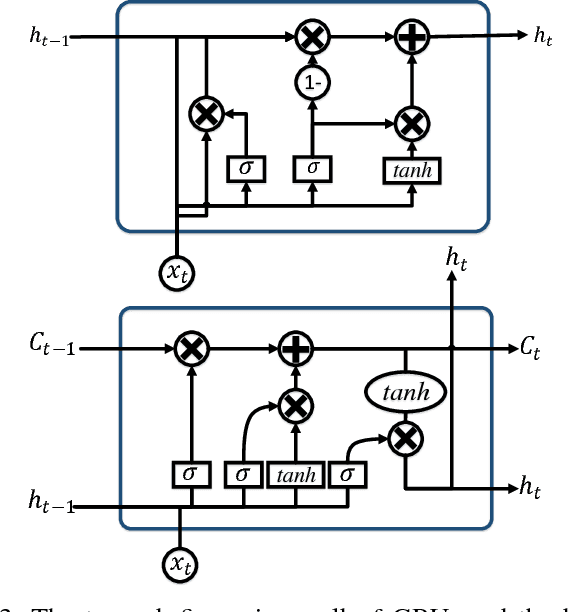
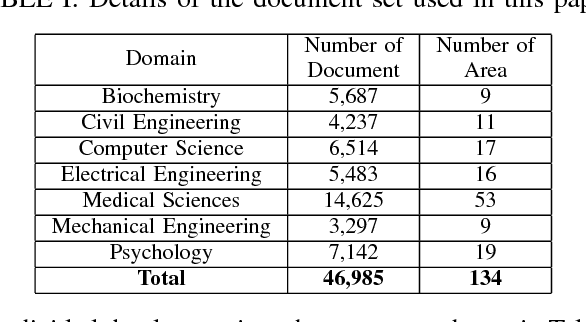
The continually increasing number of documents produced each year necessitates ever improving information processing methods for searching, retrieving, and organizing text. Central to these information processing methods is document classification, which has become an important application for supervised learning. Recently the performance of these traditional classifiers has degraded as the number of documents has increased. This is because along with this growth in the number of documents has come an increase in the number of categories. This paper approaches this problem differently from current document classification methods that view the problem as multi-class classification. Instead we perform hierarchical classification using an approach we call Hierarchical Deep Learning for Text classification (HDLTex). HDLTex employs stacks of deep learning architectures to provide specialized understanding at each level of the document hierarchy.