 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of Railway Accidents' Narratives Using Deep Learning
Paper and Code
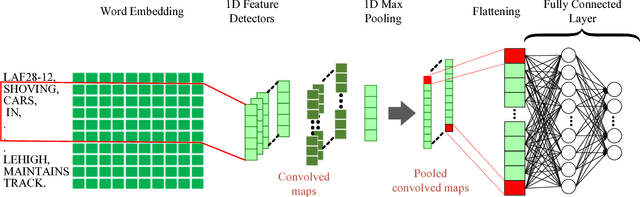

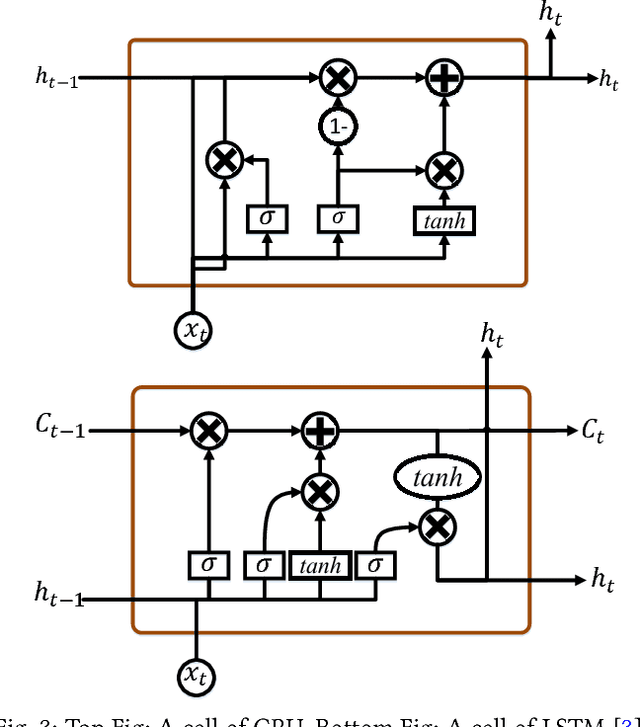
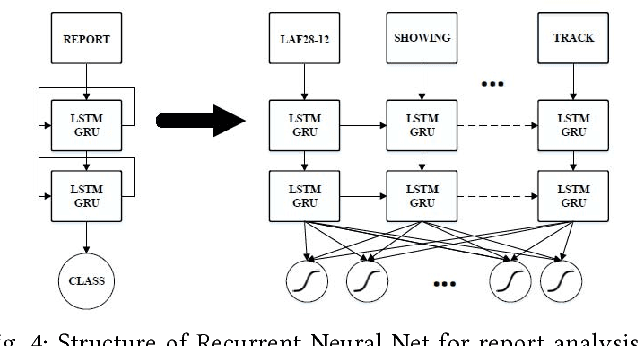
Automatic understanding of domain specific texts in order to extract useful relationships for later use is a non-trivial task. One such relationship would be between railroad accidents' causes and their correspondent descriptions in reports. From 2001 to 2016 rail accidents in the U.S. cost more than $4.6B. Railroads involved in accidents are required to submit an accident report to the Federal Railroad Administration (FRA). These reports contain a variety of fixed field entries including primary cause of the accidents (a coded variable with 389 values) as well as a narrative field which is a short text description of the accident. Although these narratives provide more information than a fixed field entry, the terminologies used in these reports are not easy to understand by a non-expert reader. Therefore, providing an assisting method to fill in the primary cause from such domain specific texts(narratives) would help to label the accidents with more accuracy. Another important question for transportation safety is whether the reported accident cause is consistent with narrative description. To address these questions, we applied deep learning methods together with powerful word embeddings such as Word2Vec and GloVe to classify accident cause values for the primary cause field using the text in the narratives. The results show that such approaches can both accurately classify accident causes based on report narratives and find important inconsistencies in accident reporting.