 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Apprenticeship Learning via Kernel-based Inverse Reinforcement Learning
Feb 25, 2020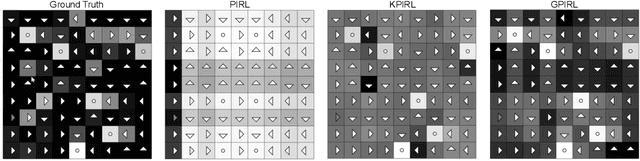

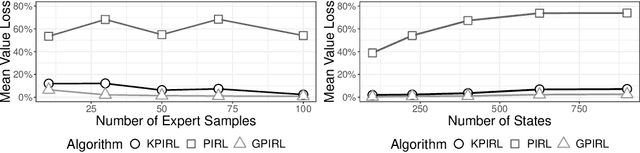

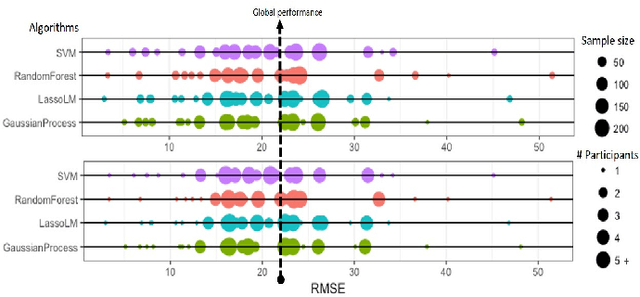
This paper considers if a reward function learned via inverse reinforcement from a human expert can be used as a feedback intervention to alter future human performance as desired (i.e., human to human apprenticeship learning). To learn reward functions two new algorithms are developed: a kernel-based inverse reinforcement learning algorithm and a Monte Carlo reinforcement learning algorithm. The algorithms are benchmarked against well-known alternatives within their respective corpus and are shown to outperform in terms of efficiency and optimality. To test the feedback intervention two randomized experiments are performed with 3,256 human participants. The experimental results demonstrate with significance that the rewards learned from "expert" individuals are effective as feedback interventions. In addition to the algorithmic contributions and successful experiments, the paper also describes three reward function modifications to improve reward function feedback interventions for humans.
Cluster-based Approach to Improve Affect Recognition from Passively Sensed Data
Jan 31, 2018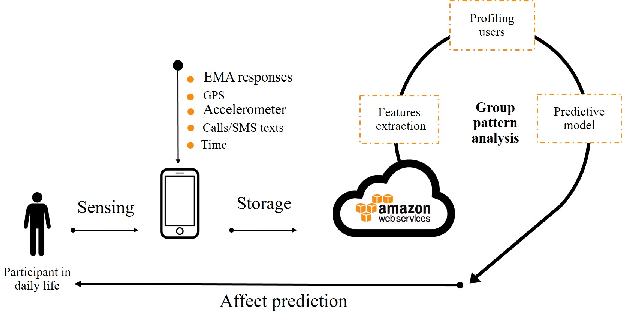
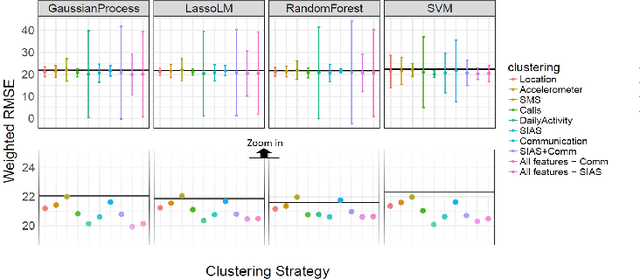
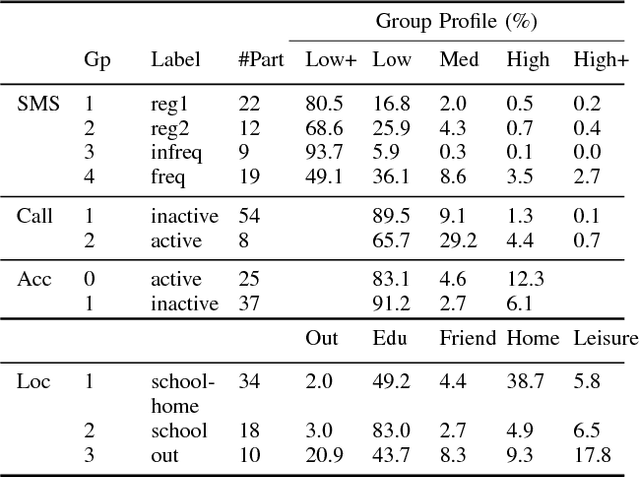
Negative affect is a proxy for mental health in adults. By being able to predict participants' negative affect states unobtrusively, researchers and clinicians will be better positioned to deliver targeted, just-in-time mental health interventions via mobile applications. This work attempts to personalize the passive recognition of negative affect states via group-based modeling of user behavior patterns captured from mobility, communication, and activity patterns. Results show that group models outperform generalized models in a dataset based on two weeks of users' daily lives.
HDLTex: Hierarchical Deep Learning for Text Classification
Oct 06, 2017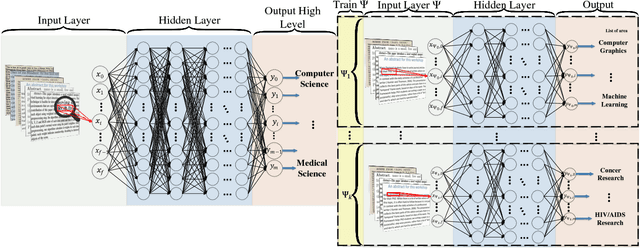
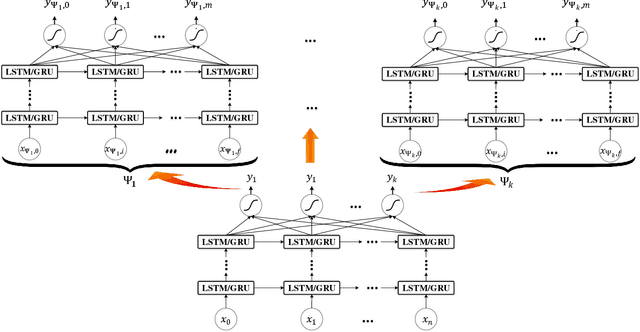
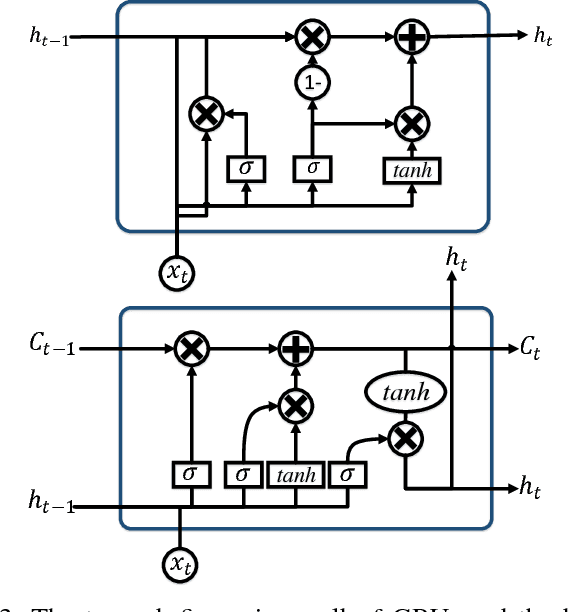
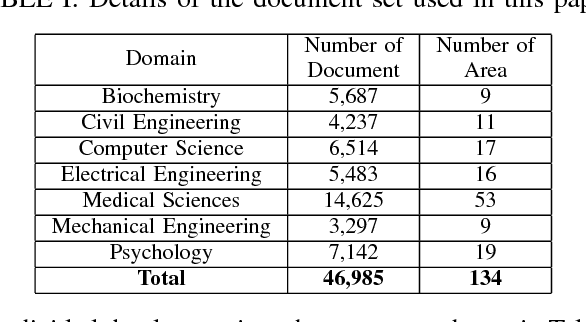
The continually increasing number of documents produced each year necessitates ever improving information processing methods for searching, retrieving, and organizing text. Central to these information processing methods is document classification, which has become an important application for supervised learning. Recently the performance of these traditional classifiers has degraded as the number of documents has increased. This is because along with this growth in the number of documents has come an increase in the number of categories. This paper approaches this problem differently from current document classification methods that view the problem as multi-class classification. Instead we perform hierarchical classification using an approach we call Hierarchical Deep Learning for Text classification (HDLTex). HDLTex employs stacks of deep learning architectures to provide specialized understanding at each level of the document hierarchy.