 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo We Know What LLMs Don't Know? A Study of Consistency in Knowledge Probing
May 27, 2025The reliability of large language models (LLMs) is greatly compromised by their tendency to hallucinate, underscoring the need for precise identification of knowledge gaps within LLMs. Various methods for probing such gaps exist, ranging from calibration-based to prompting-based methods. To evaluate these probing methods, in this paper, we propose a new process based on using input variations and quantitative metrics. Through this, we expose two dimensions of inconsistency in knowledge gap probing. (1) Intra-method inconsistency: Minimal non-semantic perturbations in prompts lead to considerable variance in detected knowledge gaps within the same probing method; e.g., the simple variation of shuffling answer options can decrease agreement to around 40%. (2) Cross-method inconsistency: Probing methods contradict each other on whether a model knows the answer. Methods are highly inconsistent -- with decision consistency across methods being as low as 7% -- even though the model, dataset, and prompt are all the same. These findings challenge existing probing methods and highlight the urgent need for perturbation-robust probing frameworks.
How far can bias go? -- Tracing bias from pretraining data to alignment
Nov 28, 2024


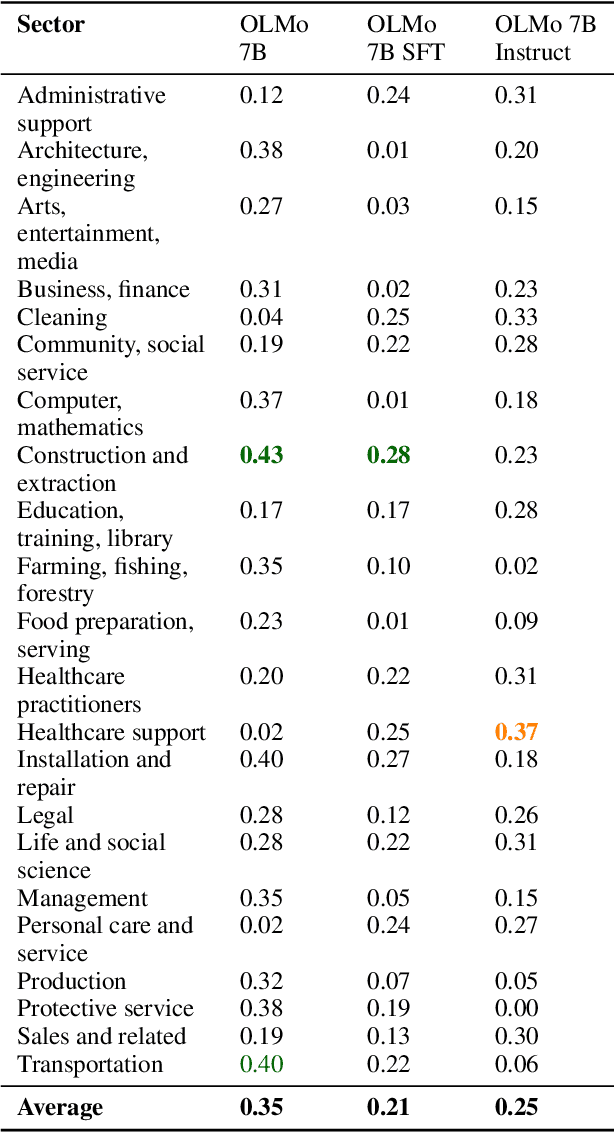
As LLMs are increasingly integrated into user-facing applications, addressing biases that perpetuate societal inequalities is crucial. While much work has gone into measuring or mitigating biases in these models, fewer studies have investigated their origins. Therefore, this study examines the correlation between gender-occupation bias in pre-training data and their manifestation in LLMs, focusing on the Dolma dataset and the OLMo model. Using zero-shot prompting and token co-occurrence analyses, we explore how biases in training data influence model outputs. Our findings reveal that biases present in pre-training data are amplified in model outputs. The study also examines the effects of prompt types, hyperparameters, and instruction-tuning on bias expression, finding instruction-tuning partially alleviating representational bias while still maintaining overall stereotypical gender associations, whereas hyperparameters and prompting variation have a lesser effect on bias expression. Our research traces bias throughout the LLM development pipeline and underscores the importance of mitigating bias at the pretraining stage.
Evaluating Morphological Compositional Generalization in Large Language Models
Oct 16, 2024Large language models (LLMs) have demonstrated significant progress in various natural language generation and understanding tasks. However, their linguistic generalization capabilities remain questionable, raising doubts about whether these models learn language similarly to humans. While humans exhibit compositional generalization and linguistic creativity in language use, the extent to which LLMs replicate these abilities, particularly in morphology, is under-explored. In this work, we systematically investigate the morphological generalization abilities of LLMs through the lens of compositionality. We define morphemes as compositional primitives and design a novel suite of generative and discriminative tasks to assess morphological productivity and systematicity. Focusing on agglutinative languages such as Turkish and Finnish, we evaluate several state-of-the-art instruction-finetuned multilingual models, including GPT-4 and Gemini. Our analysis shows that LLMs struggle with morphological compositional generalization particularly when applied to novel word roots, with performance declining sharply as morphological complexity increases. While models can identify individual morphological combinations better than chance, their performance lacks systematicity, leading to significant accuracy gaps compared to humans.
CRAFT Your Dataset: Task-Specific Synthetic Dataset Generation Through Corpus Retrieval and Augmentation
Sep 03, 2024Building high-quality datasets for specialized tasks is a time-consuming and resource-intensive process that often requires specialized domain knowledge. We propose Corpus Retrieval and Augmentation for Fine-Tuning (CRAFT), a method for generating synthetic datasets, given a small number of user-written few-shots that demonstrate the task to be performed. Given the few-shot examples, we use large-scale public web-crawled corpora and similarity-based document retrieval to find other relevant human-written documents. Lastly, instruction-tuned large language models (LLMs) augment the retrieved documents into custom-formatted task samples, which then can be used for fine-tuning. We demonstrate that CRAFT can efficiently generate large-scale task-specific training datasets for four diverse tasks: biology question-answering (QA), medicine QA and commonsense QA as well as summarization. Our experiments show that CRAFT-based models outperform or achieve comparable performance to general LLMs for QA tasks, while CRAFT-based summarization models outperform models trained on human-curated data by 46 preference points.
SYNTHEVAL: Hybrid Behavioral Testing of NLP Models with Synthetic CheckLists
Aug 30, 2024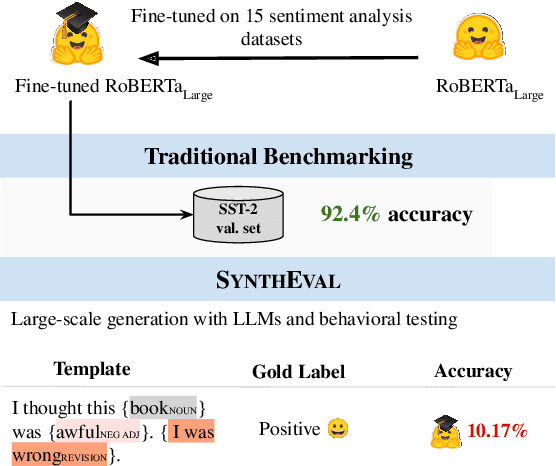

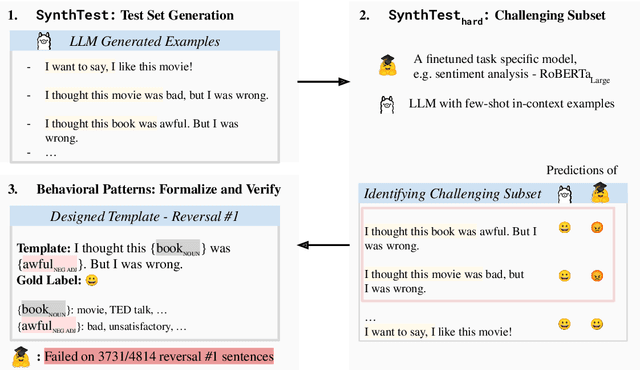

Traditional benchmarking in NLP typically involves using static held-out test sets. However, this approach often results in an overestimation of performance and lacks the ability to offer comprehensive, interpretable, and dynamic assessments of NLP models. Recently, works like DynaBench (Kiela et al., 2021) and CheckList (Ribeiro et al., 2020) have addressed these limitations through behavioral testing of NLP models with test types generated by a multistep human-annotated pipeline. Unfortunately, manually creating a variety of test types requires much human labor, often at prohibitive cost. In this work, we propose SYNTHEVAL, a hybrid behavioral testing framework that leverages large language models (LLMs) to generate a wide range of test types for a comprehensive evaluation of NLP models. SYNTHEVAL first generates sentences via LLMs using controlled generation, and then identifies challenging examples by comparing the predictions made by LLMs with task-specific NLP models. In the last stage, human experts investigate the challenging examples, manually design templates, and identify the types of failures the taskspecific models consistently exhibit. We apply SYNTHEVAL to two classification tasks, sentiment analysis and toxic language detection, and show that our framework is effective in identifying weaknesses of strong models on these tasks. We share our code in https://github.com/Loreley99/SynthEval_CheckList.
TurkishMMLU: Measuring Massive Multitask Language Understanding in Turkish
Jul 17, 2024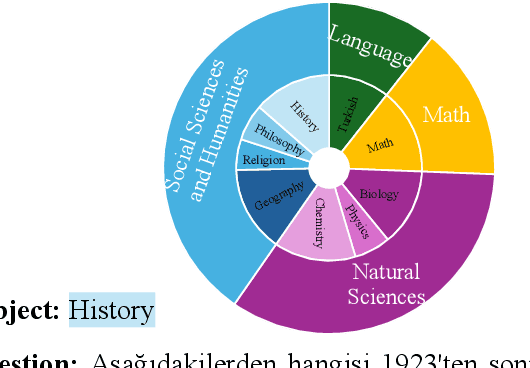
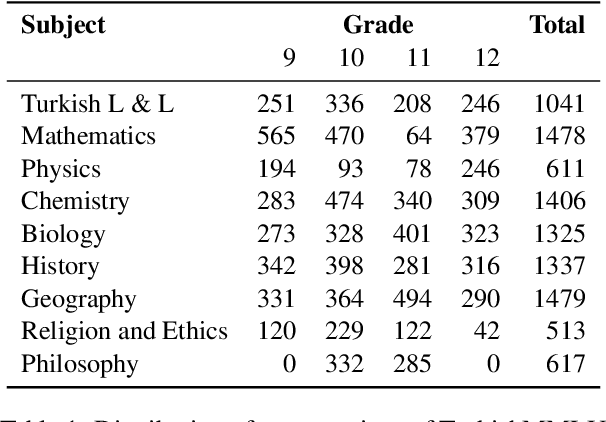
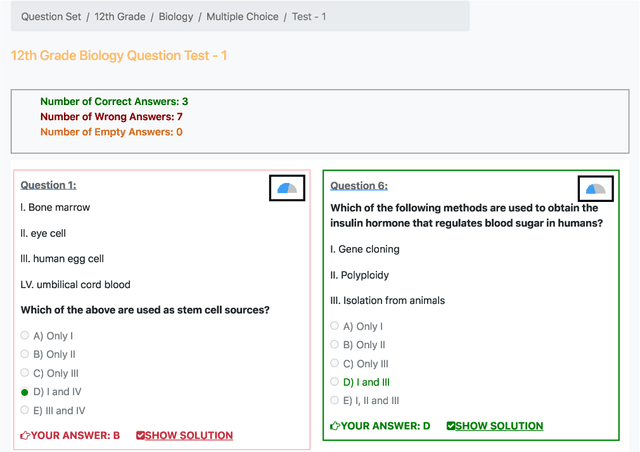
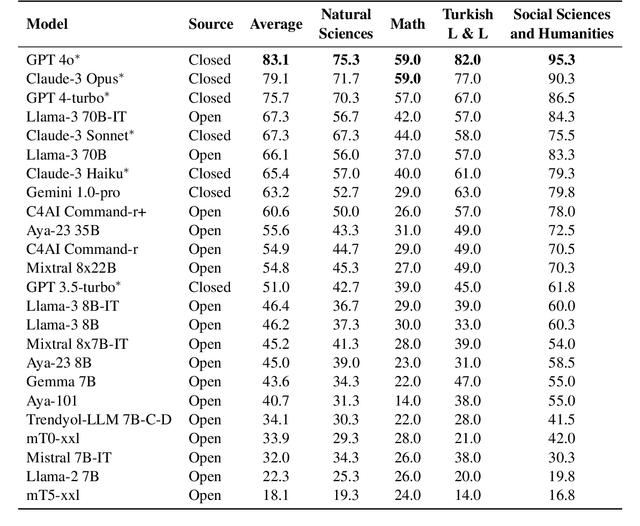
Multiple choice question answering tasks evaluate the reasoning, comprehension, and mathematical abilities of Large Language Models (LLMs). While existing benchmarks employ automatic translation for multilingual evaluation, this approach is error-prone and potentially introduces culturally biased questions, especially in social sciences. We introduce the first multitask, multiple-choice Turkish QA benchmark, TurkishMMLU, to evaluate LLMs' understanding of the Turkish language. TurkishMMLU includes over 10,000 questions, covering 9 different subjects from Turkish high-school education curricula. These questions are written by curriculum experts, suitable for the high-school curricula in Turkey, covering subjects ranging from natural sciences and math questions to more culturally representative topics such as Turkish Literature and the history of the Turkish Republic. We evaluate over 20 LLMs, including multilingual open-source (e.g., Gemma, Llama, MT5), closed-source (GPT 4o, Claude, Gemini), and Turkish-adapted (e.g., Trendyol) models. We provide an extensive evaluation, including zero-shot and few-shot evaluation of LLMs, chain-of-thought reasoning, and question difficulty analysis along with model performance. We provide an in-depth analysis of the Turkish capabilities and limitations of current LLMs to provide insights for future LLMs for the Turkish language. We publicly release our code for the dataset and evaluation: https://github.com/ArdaYueksel/TurkishMMLU.
Consistent Document-Level Relation Extraction via Counterfactuals
Jul 09, 2024Many datasets have been developed to train and evaluate document-level relation extraction (RE) models. Most of these are constructed using real-world data. It has been shown that RE models trained on real-world data suffer from factual biases. To evaluate and address this issue, we present CovEReD, a counterfactual data generation approach for document-level relation extraction datasets using entity replacement. We first demonstrate that models trained on factual data exhibit inconsistent behavior: while they accurately extract triples from factual data, they fail to extract the same triples after counterfactual modification. This inconsistency suggests that models trained on factual data rely on spurious signals such as specific entities and external knowledge $\unicode{x2013}$ rather than on the input context $\unicode{x2013}$ to extract triples. We show that by generating document-level counterfactual data with CovEReD and training models on them, consistency is maintained with minimal impact on RE performance. We release our CovEReD pipeline as well as Re-DocRED-CF, a dataset of counterfactual RE documents, to assist in evaluating and addressing inconsistency in document-level RE.
MemLLM: Finetuning LLMs to Use An Explicit Read-Write Memory
Apr 17, 2024



While current large language models (LLMs) demonstrate some capabilities in knowledge-intensive tasks, they are limited by relying on their parameters as an implicit storage mechanism. As a result, they struggle with infrequent knowledge and temporal degradation. In addition, the uninterpretable nature of parametric memorization makes it challenging to understand and prevent hallucination. Parametric memory pools and model editing are only partial solutions. Retrieval Augmented Generation (RAG) $\unicode{x2013}$ though non-parametric $\unicode{x2013}$ has its own limitations: it lacks structure, complicates interpretability and makes it hard to effectively manage stored knowledge. In this paper, we introduce MemLLM, a novel method of enhancing LLMs by integrating a structured and explicit read-and-write memory module. MemLLM tackles the aforementioned challenges by enabling dynamic interaction with the memory and improving the LLM's capabilities in using stored knowledge. Our experiments indicate that MemLLM enhances the LLM's performance and interpretability, in language modeling in general and knowledge-intensive tasks in particular. We see MemLLM as an important step towards making LLMs more grounded and factual through memory augmentation.
Hybrid Human-LLM Corpus Construction and LLM Evaluation for Rare Linguistic Phenomena
Mar 11, 2024


Argument Structure Constructions (ASCs) are one of the most well-studied construction groups, providing a unique opportunity to demonstrate the usefulness of Construction Grammar (CxG). For example, the caused-motion construction (CMC, ``She sneezed the foam off her cappuccino'') demonstrates that constructions must carry meaning, otherwise the fact that ``sneeze'' in this context causes movement cannot be explained. We form the hypothesis that this remains challenging even for state-of-the-art Large Language Models (LLMs), for which we devise a test based on substituting the verb with a prototypical motion verb. To be able to perform this test at statistically significant scale, in the absence of adequate CxG corpora, we develop a novel pipeline of NLP-assisted collection of linguistically annotated text. We show how dependency parsing and GPT-3.5 can be used to significantly reduce annotation cost and thus enable the annotation of rare phenomena at scale. We then evaluate GPT, Gemini, Llama2 and Mistral models for their understanding of the CMC using the newly collected corpus. We find that all models struggle with understanding the motion component that the CMC adds to a sentence.
Hallucination Augmented Recitations for Language Models
Nov 13, 2023Attribution is a key concept in large language models (LLMs) as it enables control over information sources and enhances the factuality of LLMs. While existing approaches utilize open book question answering to improve attribution, factual datasets may reward language models to recall facts that they already know from their pretraining data, not attribution. In contrast, counterfactual open book QA datasets would further improve attribution because the answer could only be grounded in the given text. We propose Hallucination Augmented Recitations (HAR) for creating counterfactual datasets by utilizing hallucination in LLMs to improve attribution. For open book QA as a case study, we demonstrate that models finetuned with our counterfactual datasets improve text grounding, leading to better open book QA performance, with up to an 8.0% increase in F1 score. Our counterfactual dataset leads to significantly better performance than using humanannotated factual datasets, even with 4x smaller datasets and 4x smaller models. We observe that improvements are consistent across various model sizes and datasets, including multi-hop, biomedical, and adversarial QA datasets.