 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMONETA: Multimodal Industry Classification through Geographic Information with Multi Agent Systems
Apr 09, 2026Industry classification schemes are integral parts of public and corporate databases as they classify businesses based on economic activity. Due to the size of the company registers, manual annotation is costly, and fine-tuning models with every update in industry classification schemes requires significant data collection. We replicate the manual expert verification by using existing or easily retrievable multimodal resources for industry classification. We present MONETA, the first multimodal industry classification benchmark with text (Website, Wikipedia, Wikidata) and geospatial sources (OpenStreetMap and satellite imagery). Our dataset enlists 1,000 businesses in Europe with 20 economic activity labels according to EU guidelines (NACE). Our training-free baseline reaches 62.10% and 74.10% with open and closed-source Multimodal Large Language Models (MLLM). We observe an increase of up to 22.80% with the combination of multi-turn design, context enrichment, and classification explanations. We will release our dataset and the enhanced guidelines.
TurkishMMLU: Measuring Massive Multitask Language Understanding in Turkish
Jul 17, 2024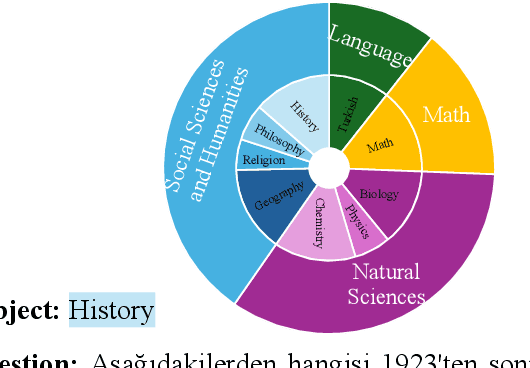
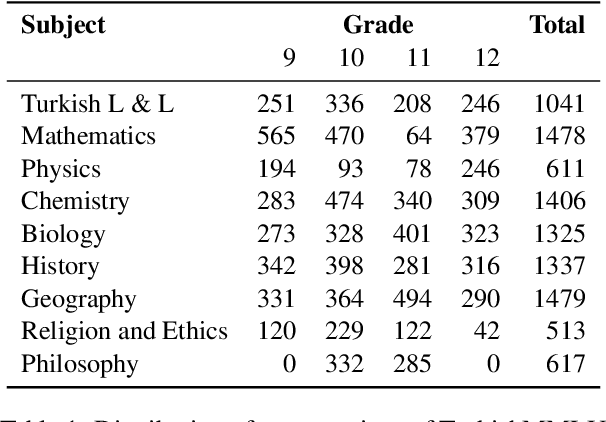
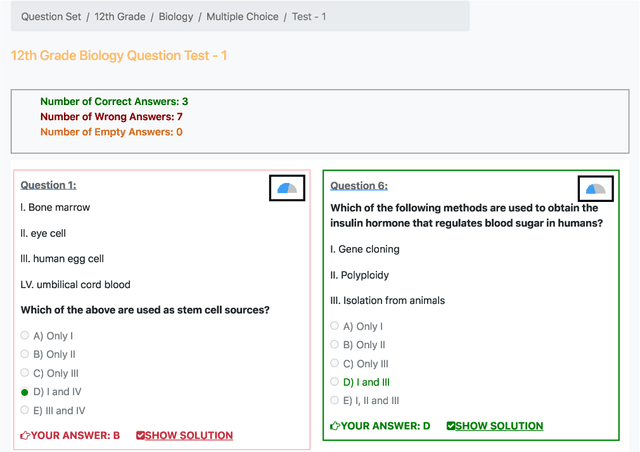
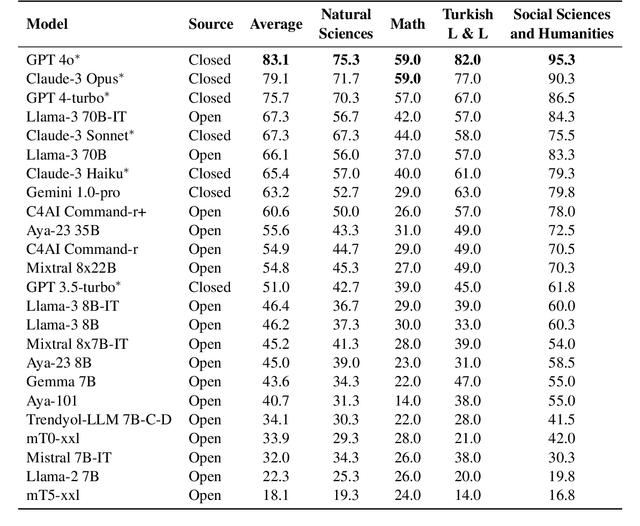
Multiple choice question answering tasks evaluate the reasoning, comprehension, and mathematical abilities of Large Language Models (LLMs). While existing benchmarks employ automatic translation for multilingual evaluation, this approach is error-prone and potentially introduces culturally biased questions, especially in social sciences. We introduce the first multitask, multiple-choice Turkish QA benchmark, TurkishMMLU, to evaluate LLMs' understanding of the Turkish language. TurkishMMLU includes over 10,000 questions, covering 9 different subjects from Turkish high-school education curricula. These questions are written by curriculum experts, suitable for the high-school curricula in Turkey, covering subjects ranging from natural sciences and math questions to more culturally representative topics such as Turkish Literature and the history of the Turkish Republic. We evaluate over 20 LLMs, including multilingual open-source (e.g., Gemma, Llama, MT5), closed-source (GPT 4o, Claude, Gemini), and Turkish-adapted (e.g., Trendyol) models. We provide an extensive evaluation, including zero-shot and few-shot evaluation of LLMs, chain-of-thought reasoning, and question difficulty analysis along with model performance. We provide an in-depth analysis of the Turkish capabilities and limitations of current LLMs to provide insights for future LLMs for the Turkish language. We publicly release our code for the dataset and evaluation: https://github.com/ArdaYueksel/TurkishMMLU.
Butterfly Effect Attack: Tiny and Seemingly Unrelated Perturbations for Object Detection
Nov 14, 2022



This work aims to explore and identify tiny and seemingly unrelated perturbations of images in object detection that will lead to performance degradation. While tininess can naturally be defined using $L_p$ norms, we characterize the degree of "unrelatedness" of an object by the pixel distance between the occurred perturbation and the object. Triggering errors in prediction while satisfying two objectives can be formulated as a multi-objective optimization problem where we utilize genetic algorithms to guide the search. The result successfully demonstrates that (invisible) perturbations on the right part of the image can drastically change the outcome of object detection on the left. An extensive evaluation reaffirms our conjecture that transformer-based object detection networks are more susceptible to butterfly effects in comparison to single-stage object detection networks such as YOLOv5.