 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancements to the BOUN Treebank Reflecting the Agglutinative Nature of Turkish
Jul 24, 2022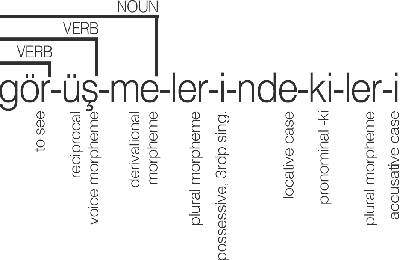
In this study, we aim to offer linguistically motivated solutions to resolve the issues of the lack of representation of null morphemes, highly productive derivational processes, and syncretic morphemes of Turkish in the BOUN Treebank without diverging from the Universal Dependencies framework. In order to tackle these issues, new annotation conventions were introduced by splitting certain lemmas and employing the MISC (miscellaneous) tab in the UD framework to denote derivation. Representational capabilities of the re-annotated treebank were tested on a LSTM-based dependency parser and an updated version of the BoAT Tool is introduced.
A Hybrid Approach to Dependency Parsing: Combining Rules and Morphology with Deep Learning
Feb 24, 2020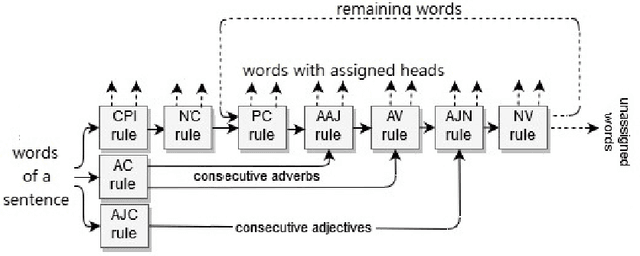



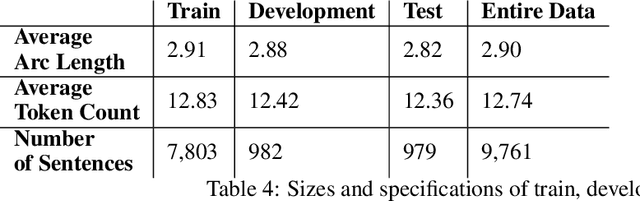
Fully data-driven, deep learning-based models are usually designed as language-independent and have been shown to be successful for many natural language processing tasks. However, when the studied language is low-resourced and the amount of training data is insufficient, these models can benefit from the integration of natural language grammar-based information. We propose two approaches to dependency parsing especially for languages with restricted amount of training data. Our first approach combines a state-of-the-art deep learning-based parser with a rule-based approach and the second one incorporates morphological information into the parser. In the rule-based approach, the parsing decisions made by the rules are encoded and concatenated with the vector representations of the input words as additional information to the deep network. The morphology-based approach proposes different methods to include the morphological structure of words into the parser network. Experiments are conducted on the IMST-UD Treebank and the results suggest that integration of explicit knowledge about the target language to a neural parser through a rule-based parsing system and morphological analysis leads to more accurate annotations and hence, increases the parsing performance in terms of attachment scores. The proposed methods are developed for Turkish, but can be adapted to other languages as well.