 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabiBERT: A Large-Scale ModernBERT Foundation Model and Unified Benchmarking Framework for Turkish
Dec 28, 2025Since the inception of BERT, encoder-only Transformers have evolved significantly in computational efficiency, training stability, and long-context modeling. ModernBERT consolidates these advances by integrating Rotary Positional Embeddings (RoPE), FlashAttention, and refined normalization. Despite these developments, Turkish NLP lacks a monolingual encoder trained from scratch incorporating such modern architectural paradigms. This work introduces TabiBERT, a monolingual Turkish encoder based on ModernBERT architecture trained from scratch on a large, curated corpus. TabiBERT is pre-trained on one trillion tokens sampled from an 84.88B token multi-domain corpus: web text (73%), scientific publications (20%), source code (6%), and mathematical content (0.3%). The model supports 8,192-token context length (16x original BERT), achieves up to 2.65x inference speedup, and reduces GPU memory consumption, enabling larger batch sizes. We introduce TabiBench with 28 datasets across eight task categories with standardized splits and protocols, evaluated using GLUE-style macro-averaging. TabiBERT attains 77.58 on TabiBench, outperforming BERTurk by 1.62 points and establishing state-of-the-art on five of eight categories: question answering (+9.55), code retrieval (+2.41), and document retrieval (+0.60). Compared with task-specific prior best results, including specialized models like TurkishBERTweet, TabiBERT achieves +1.47 average improvement, indicating robust cross-domain generalization. We release model weights, training configurations, and evaluation code for transparent, reproducible Turkish encoder research.
TURNA: A Turkish Encoder-Decoder Language Model for Enhanced Understanding and Generation
Jan 25, 2024The recent advances in natural language processing have predominantly favored well-resourced English-centric models, resulting in a significant gap with low-resource languages. In this work, we introduce the language model TURNA, which is developed for the low-resource language Turkish and is capable of both natural language understanding and generation tasks. TURNA is pretrained with an encoder-decoder architecture based on the unified framework UL2 with a diverse corpus that we specifically curated for this purpose. We evaluated TURNA with three generation tasks and five understanding tasks for Turkish. The results show that TURNA outperforms several multilingual models in both understanding and generation tasks, and competes with monolingual Turkish models in understanding tasks. TURNA is made available at https://huggingface.co/boun-tabi-LMG/TURNA .
Enhancements to the BOUN Treebank Reflecting the Agglutinative Nature of Turkish
Jul 24, 2022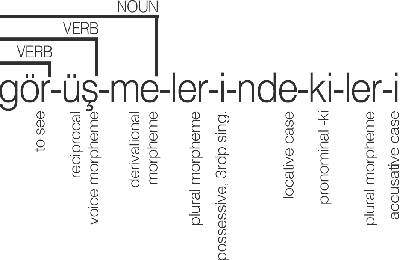
In this study, we aim to offer linguistically motivated solutions to resolve the issues of the lack of representation of null morphemes, highly productive derivational processes, and syncretic morphemes of Turkish in the BOUN Treebank without diverging from the Universal Dependencies framework. In order to tackle these issues, new annotation conventions were introduced by splitting certain lemmas and employing the MISC (miscellaneous) tab in the UD framework to denote derivation. Representational capabilities of the re-annotated treebank were tested on a LSTM-based dependency parser and an updated version of the BoAT Tool is introduced.
Improving Named Entity Recognition by Jointly Learning to Disambiguate Morphological Tags
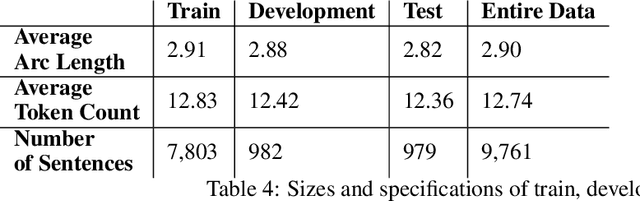
Jul 17, 2018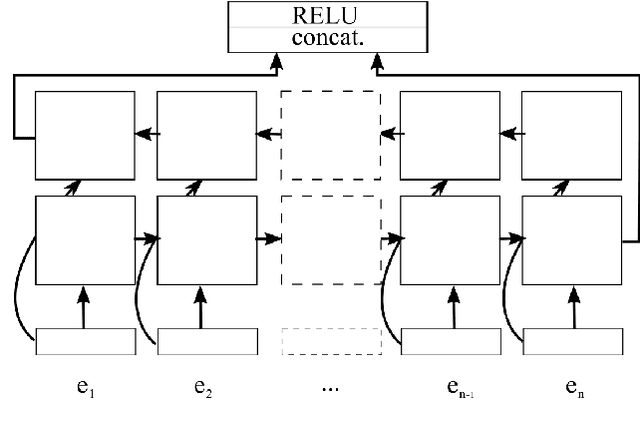
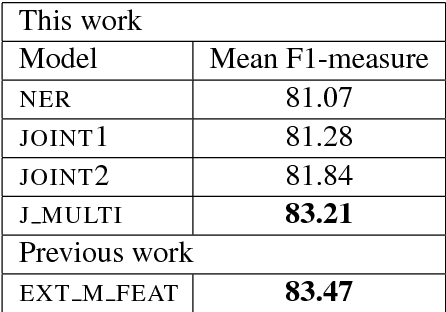
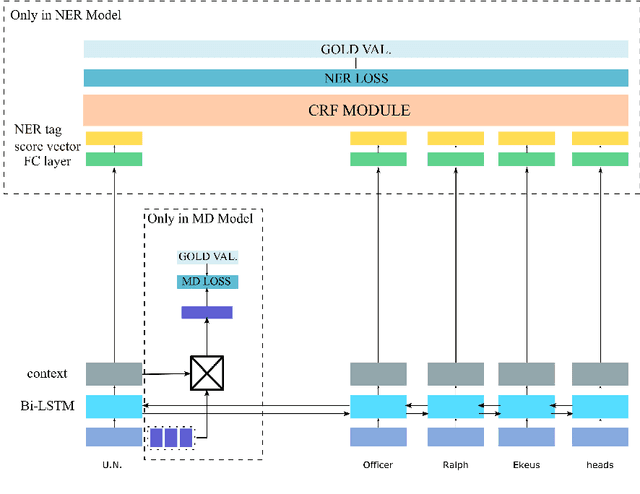
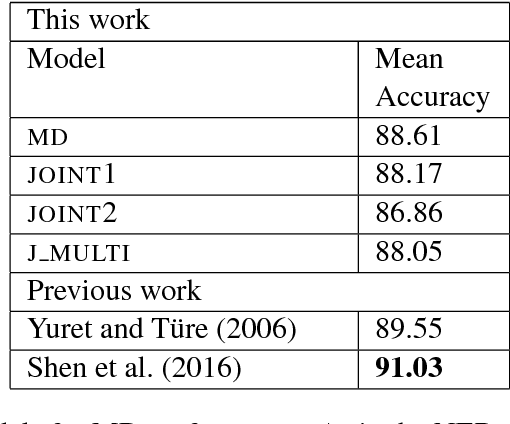
Previous studies have shown that linguistic features of a word such as possession, genitive or other grammatical cases can be employed in word representations of a named entity recognition (NER) tagger to improve the performance for morphologically rich languages. However, these taggers require external morphological disambiguation (MD) tools to function which are hard to obtain or non-existent for many languages. In this work, we propose a model which alleviates the need for such disambiguators by jointly learning NER and MD taggers in languages for which one can provide a list of candidate morphological analyses. We show that this can be done independent of the morphological annotation schemes, which differ among languages. Our experiments employing three different model architectures that join these two tasks show that joint learning improves NER performance. Furthermore, the morphological disambiguator's performance is shown to be competitive.