 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancements to the BOUN Treebank Reflecting the Agglutinative Nature of Turkish
Jul 24, 2022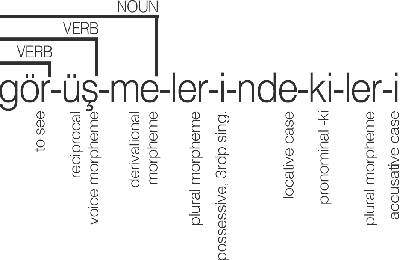
In this study, we aim to offer linguistically motivated solutions to resolve the issues of the lack of representation of null morphemes, highly productive derivational processes, and syncretic morphemes of Turkish in the BOUN Treebank without diverging from the Universal Dependencies framework. In order to tackle these issues, new annotation conventions were introduced by splitting certain lemmas and employing the MISC (miscellaneous) tab in the UD framework to denote derivation. Representational capabilities of the re-annotated treebank were tested on a LSTM-based dependency parser and an updated version of the BoAT Tool is introduced.
Improving Named Entity Recognition by Jointly Learning to Disambiguate Morphological Tags
Jul 17, 2018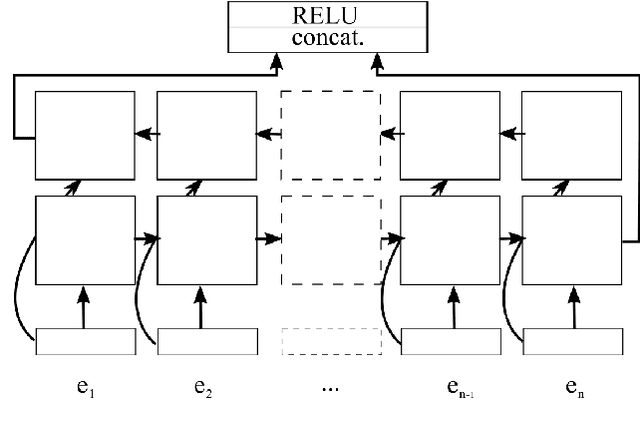
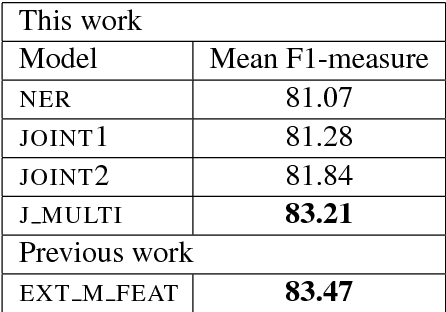
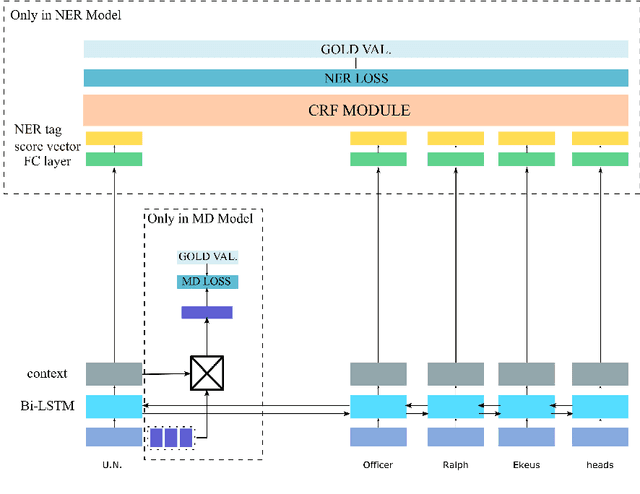
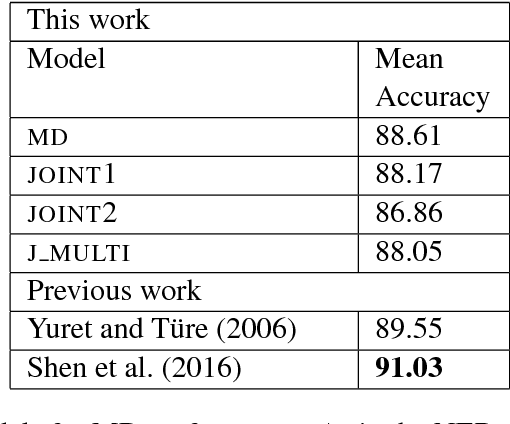
Previous studies have shown that linguistic features of a word such as possession, genitive or other grammatical cases can be employed in word representations of a named entity recognition (NER) tagger to improve the performance for morphologically rich languages. However, these taggers require external morphological disambiguation (MD) tools to function which are hard to obtain or non-existent for many languages. In this work, we propose a model which alleviates the need for such disambiguators by jointly learning NER and MD taggers in languages for which one can provide a list of candidate morphological analyses. We show that this can be done independent of the morphological annotation schemes, which differ among languages. Our experiments employing three different model architectures that join these two tasks show that joint learning improves NER performance. Furthermore, the morphological disambiguator's performance is shown to be competitive.