 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Aspect Extraction Framework using Different Embedding Types, Learning Models, and Dependency Structure
Mar 05, 2025Aspect-based sentiment analysis has gained significant attention in recent years due to its ability to provide fine-grained insights for sentiment expressions related to specific features of entities. An important component of aspect-based sentiment analysis is aspect extraction, which involves identifying and extracting aspect terms from text. Effective aspect extraction serves as the foundation for accurate sentiment analysis at the aspect level. In this paper, we propose aspect extraction models that use different types of embeddings for words and part-of-speech tags and that combine several learning models. We also propose tree positional encoding that is based on dependency parsing output to capture better the aspect positions in sentences. In addition, a new aspect extraction dataset is built for Turkish by machine translating an English dataset in a controlled setting. The experiments conducted on two Turkish datasets showed that the proposed models mostly outperform the studies that use the same datasets, and incorporating tree positional encoding increases the performance of the models.
Sentiment Analysis Using Averaged Weighted Word Vector Features
Feb 13, 2020

People use the world wide web heavily to share their experience with entities such as products, services, or travel destinations. Texts that provide online feedback in the form of reviews and comments are essential to make consumer decisions. These comments create a valuable source that may be used to measure satisfaction related to products or services. Sentiment analysis is the task of identifying opinions expressed in such text fragments. In this work, we develop two methods that combine different types of word vectors to learn and estimate polarity of reviews. We develop average review vectors from word vectors and add weights to this review vectors using word frequencies in positive and negative sensitivity-tagged reviews. We applied the methods to several datasets from different domains that are used as standard benchmarks for sentiment analysis. We ensemble the techniques with each other and existing methods, and we make a comparison with the approaches in the literature. The results show that the performances of our approaches outperform the state-of-the-art success rates.
Generating Word and Document Embeddings for Sentiment Analysis
Jan 05, 2020
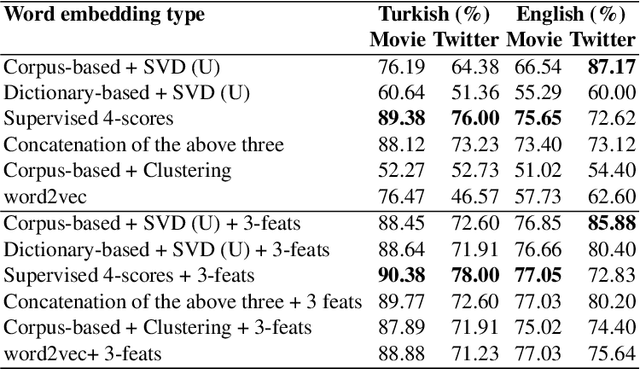
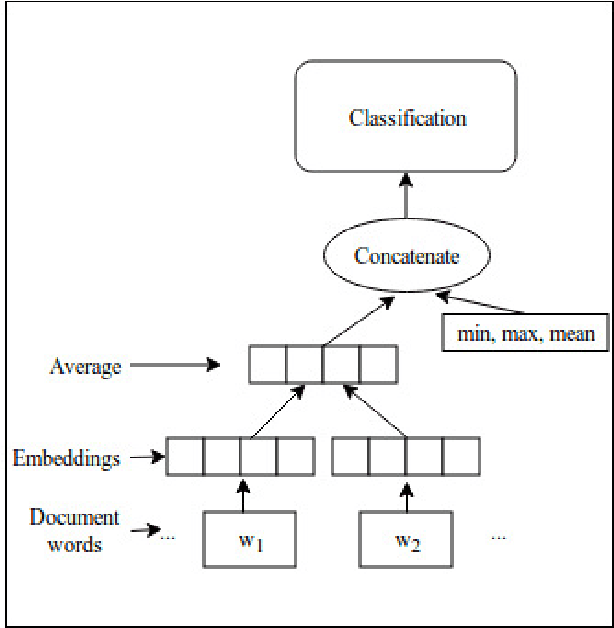
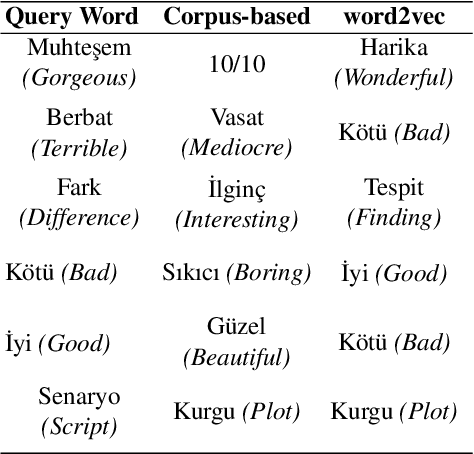
Sentiments of words differ from one corpus to another. Inducing general sentiment lexicons for languages and using them cannot, in general, produce meaningful results for different domains. In this paper, we combine contextual and supervised information with the general semantic representations of words occurring in the dictionary. Contexts of words help us capture the domain-specific information and supervised scores of words are indicative of the polarities of those words. When we combine supervised features of words with the features extracted from their dictionary definitions, we observe an increase in the success rates. We try out the combinations of contextual, supervised, and dictionary-based approaches, and generate original vectors. We also combine the word2vec approach with hand-crafted features. We induce domain-specific sentimental vectors for two corpora, which are the movie domain and the Twitter datasets in Turkish. When we thereafter generate document vectors and employ the support vector machines method utilising those vectors, our approaches perform better than the baseline studies for Turkish with a significant margin. We evaluated our models on two English corpora as well and these also outperformed the word2vec approach. It shows that our approaches are cross-lingual and cross-domain.
* Accepted and presented as a full paper at 20th International Conference on Computational Linguistics and Intelligent Text Processing (CICLing 2019), April 7-13, 2019, La Rochelle, France
Dictionary-Based Concept Mining: An Application for Turkish
Jan 12, 2014

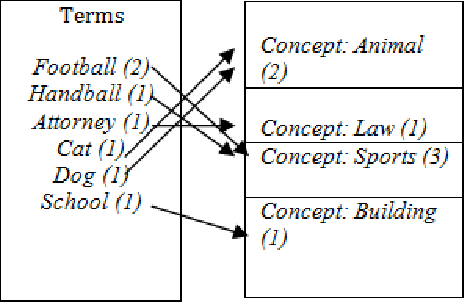
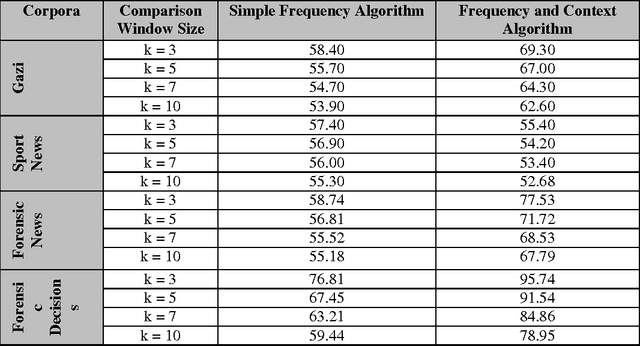
In this study, a dictionary-based method is used to extract expressive concepts from documents. So far, there have been many studies concerning concept mining in English, but this area of study for Turkish, an agglutinative language, is still immature. We used dictionary instead of WordNet, a lexical database grouping words into synsets that is widely used for concept extraction. The dictionaries are rarely used in the domain of concept mining, but taking into account that dictionary entries have synonyms, hypernyms, hyponyms and other relationships in their meaning texts, the success rate has been high for determining concepts. This concept extraction method is implemented on documents, that are collected from different corpora.