Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDictionary-Based Concept Mining: An Application for Turkish
Jan 12, 2014

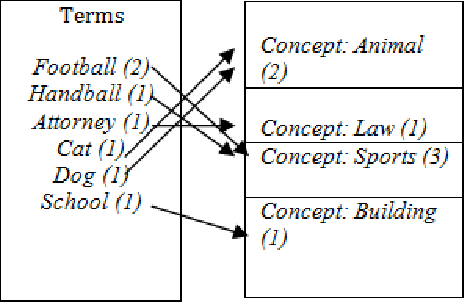
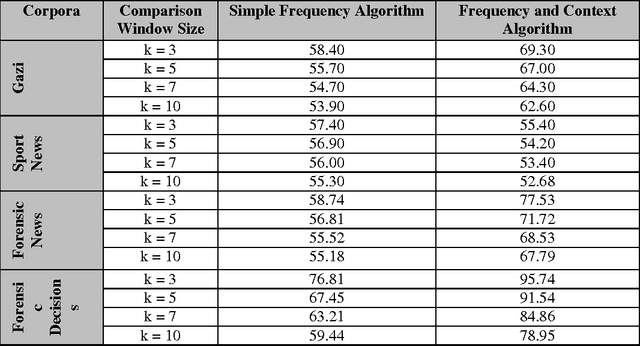
In this study, a dictionary-based method is used to extract expressive concepts from documents. So far, there have been many studies concerning concept mining in English, but this area of study for Turkish, an agglutinative language, is still immature. We used dictionary instead of WordNet, a lexical database grouping words into synsets that is widely used for concept extraction. The dictionaries are rarely used in the domain of concept mining, but taking into account that dictionary entries have synonyms, hypernyms, hyponyms and other relationships in their meaning texts, the success rate has been high for determining concepts. This concept extraction method is implemented on documents, that are collected from different corpora.
* 12 pages with 3 figures, to be published in "International Conference
on Foundations of Computer Science & Technology (CST 2014), Zurich,
Switzerland - January 2014 Proceedings, AIRCC"
Via