 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Word and Document Embeddings for Sentiment Analysis
Paper and Code
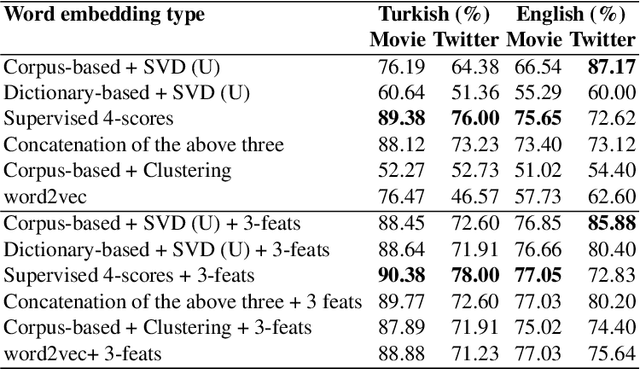
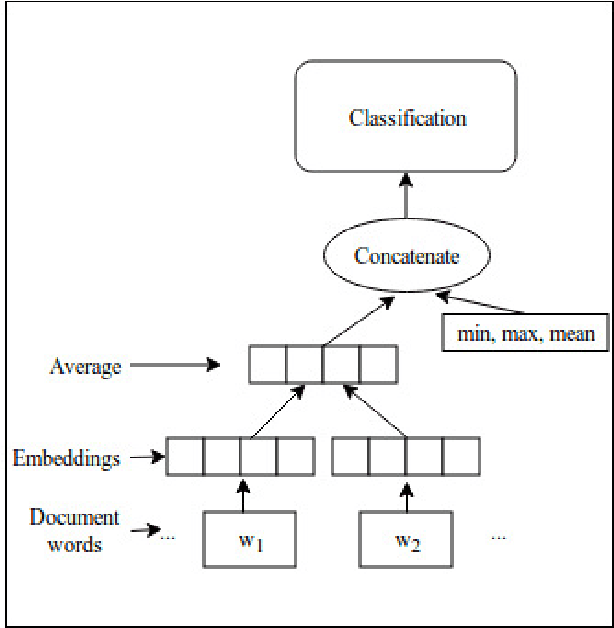
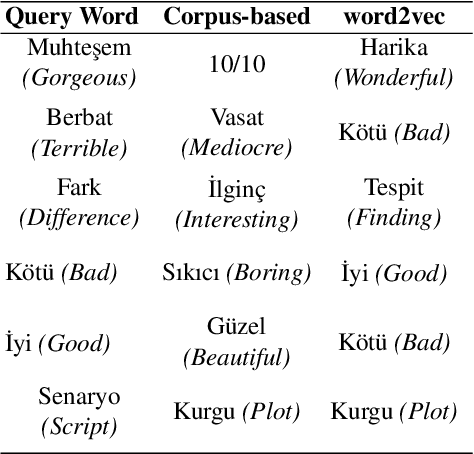
Sentiments of words differ from one corpus to another. Inducing general sentiment lexicons for languages and using them cannot, in general, produce meaningful results for different domains. In this paper, we combine contextual and supervised information with the general semantic representations of words occurring in the dictionary. Contexts of words help us capture the domain-specific information and supervised scores of words are indicative of the polarities of those words. When we combine supervised features of words with the features extracted from their dictionary definitions, we observe an increase in the success rates. We try out the combinations of contextual, supervised, and dictionary-based approaches, and generate original vectors. We also combine the word2vec approach with hand-crafted features. We induce domain-specific sentimental vectors for two corpora, which are the movie domain and the Twitter datasets in Turkish. When we thereafter generate document vectors and employ the support vector machines method utilising those vectors, our approaches perform better than the baseline studies for Turkish with a significant margin. We evaluated our models on two English corpora as well and these also outperformed the word2vec approach. It shows that our approaches are cross-lingual and cross-domain.