 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentiment Analysis Using Averaged Weighted Word Vector Features
Feb 13, 2020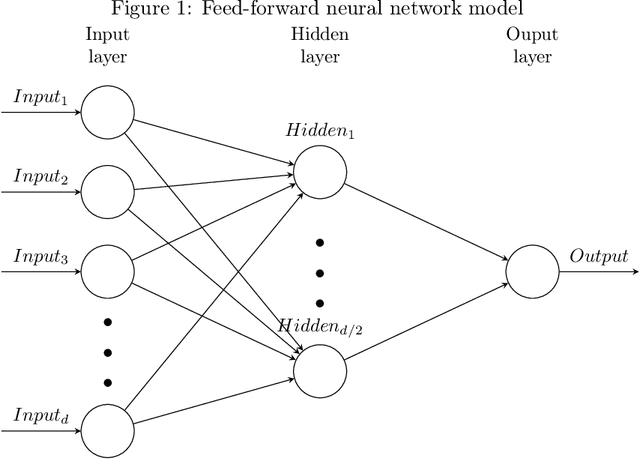

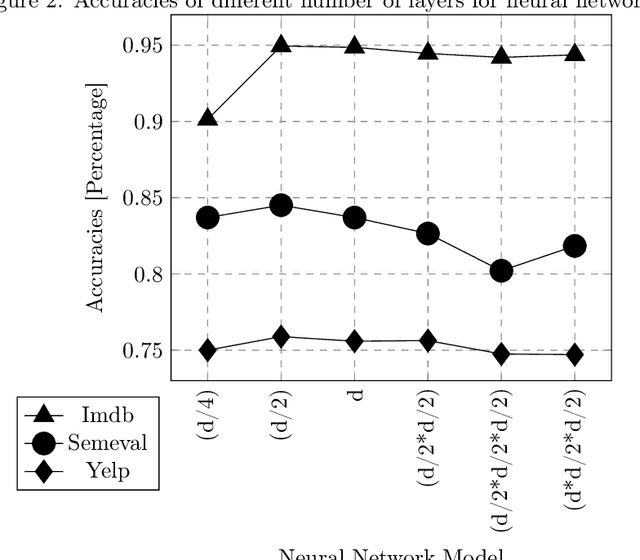
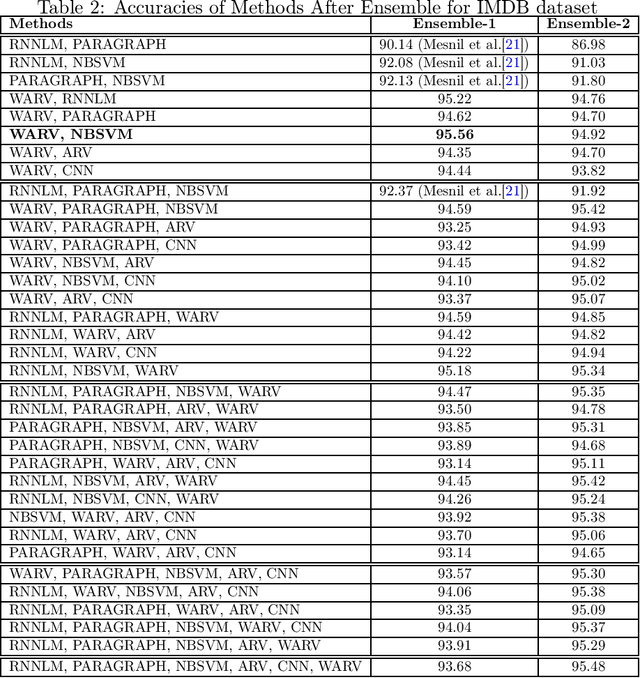
People use the world wide web heavily to share their experience with entities such as products, services, or travel destinations. Texts that provide online feedback in the form of reviews and comments are essential to make consumer decisions. These comments create a valuable source that may be used to measure satisfaction related to products or services. Sentiment analysis is the task of identifying opinions expressed in such text fragments. In this work, we develop two methods that combine different types of word vectors to learn and estimate polarity of reviews. We develop average review vectors from word vectors and add weights to this review vectors using word frequencies in positive and negative sensitivity-tagged reviews. We applied the methods to several datasets from different domains that are used as standard benchmarks for sentiment analysis. We ensemble the techniques with each other and existing methods, and we make a comparison with the approaches in the literature. The results show that the performances of our approaches outperform the state-of-the-art success rates.
Morphological Embeddings for Named Entity Recognition in Morphologically Rich Languages
Jun 01, 2017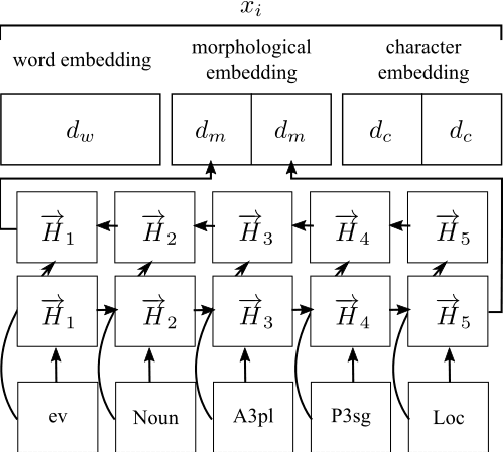

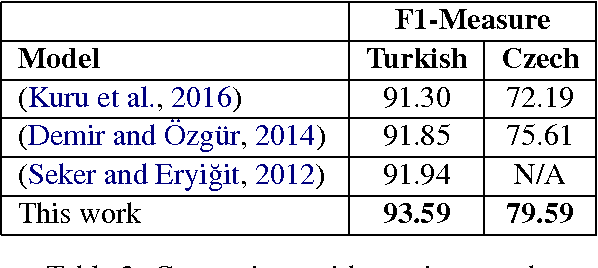
In this work, we present new state-of-the-art results of 93.59,% and 79.59,% for Turkish and Czech named entity recognition based on the model of (Lample et al., 2016). We contribute by proposing several schemes for representing the morphological analysis of a word in the context of named entity recognition. We show that a concatenation of this representation with the word and character embeddings improves the performance. The effect of these representation schemes on the tagging performance is also investigated.