Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorphological Embeddings for Named Entity Recognition in Morphologically Rich Languages
Paper and Code
Jun 01, 2017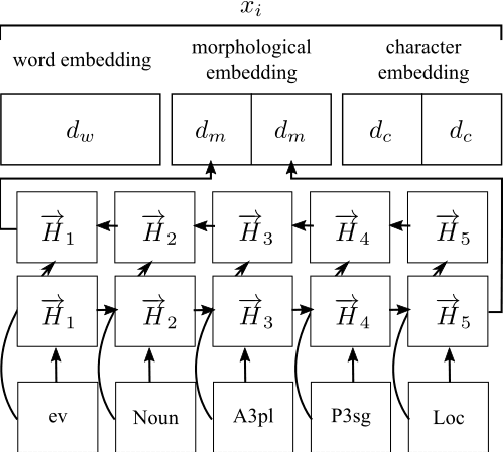

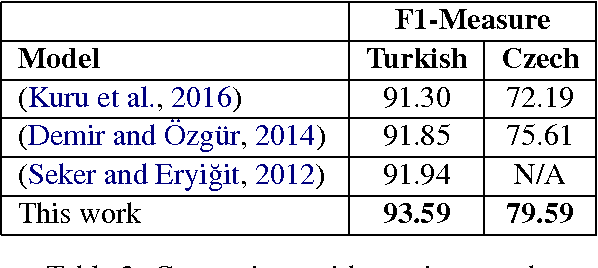
In this work, we present new state-of-the-art results of 93.59,% and 79.59,% for Turkish and Czech named entity recognition based on the model of (Lample et al., 2016). We contribute by proposing several schemes for representing the morphological analysis of a word in the context of named entity recognition. We show that a concatenation of this representation with the word and character embeddings improves the performance. The effect of these representation schemes on the tagging performance is also investigated.
* Working draft
View paper on