 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorphological Embeddings for Named Entity Recognition in Morphologically Rich Languages
Jun 01, 2017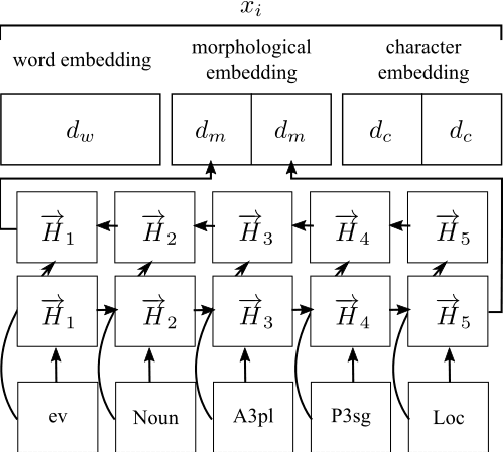

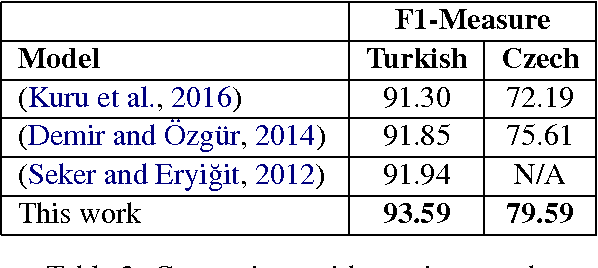
In this work, we present new state-of-the-art results of 93.59,% and 79.59,% for Turkish and Czech named entity recognition based on the model of (Lample et al., 2016). We contribute by proposing several schemes for representing the morphological analysis of a word in the context of named entity recognition. We show that a concatenation of this representation with the word and character embeddings improves the performance. The effect of these representation schemes on the tagging performance is also investigated.
A Morphology-aware Network for Morphological Disambiguation
Feb 13, 2017
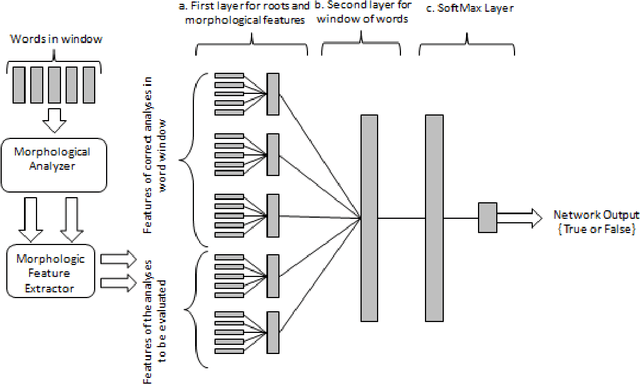


Agglutinative languages such as Turkish, Finnish and Hungarian require morphological disambiguation before further processing due to the complex morphology of words. A morphological disambiguator is used to select the correct morphological analysis of a word. Morphological disambiguation is important because it generally is one of the first steps of natural language processing and its performance affects subsequent analyses. In this paper, we propose a system that uses deep learning techniques for morphological disambiguation. Many of the state-of-the-art results in computer vision, speech recognition and natural language processing have been obtained through deep learning models. However, applying deep learning techniques to morphologically rich languages is not well studied. In this work, while we focus on Turkish morphological disambiguation we also present results for French and German in order to show that the proposed architecture achieves high accuracy with no language-specific feature engineering or additional resource. In the experiments, we achieve 84.12, 88.35 and 93.78 morphological disambiguation accuracy among the ambiguous words for Turkish, German and French respectively.
Automatically Annotated Turkish Corpus for Named Entity Recognition and Text Categorization using Large-Scale Gazetteers
Feb 09, 2017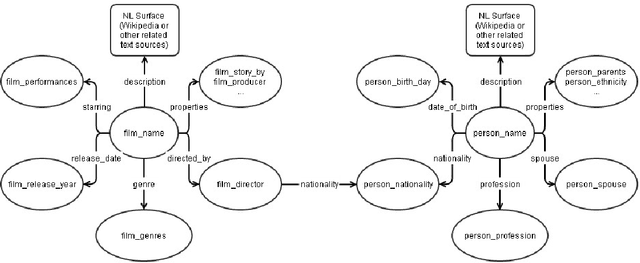
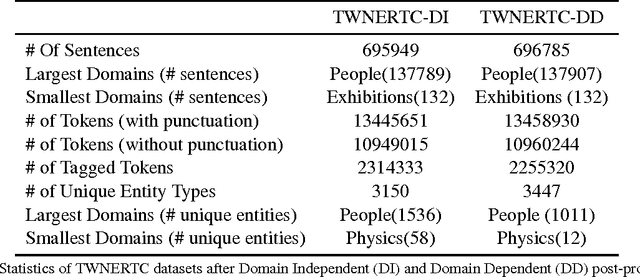

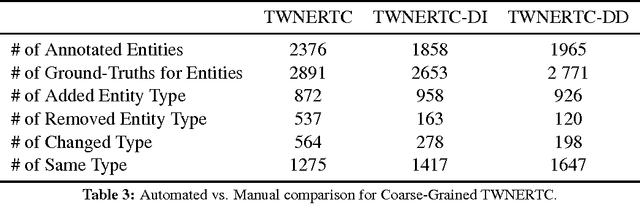
Turkish Wikipedia Named-Entity Recognition and Text Categorization (TWNERTC) dataset is a collection of automatically categorized and annotated sentences obtained from Wikipedia. We constructed large-scale gazetteers by using a graph crawler algorithm to extract relevant entity and domain information from a semantic knowledge base, Freebase. The constructed gazetteers contains approximately 300K entities with thousands of fine-grained entity types under 77 different domains. Since automated processes are prone to ambiguity, we also introduce two new content specific noise reduction methodologies. Moreover, we map fine-grained entity types to the equivalent four coarse-grained types: person, loc, org, misc. Eventually, we construct six different dataset versions and evaluate the quality of annotations by comparing ground truths from human annotators. We make these datasets publicly available to support studies on Turkish named-entity recognition (NER) and text categorization (TC).