 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatically Annotated Turkish Corpus for Named Entity Recognition and Text Categorization using Large-Scale Gazetteers
Paper and Code
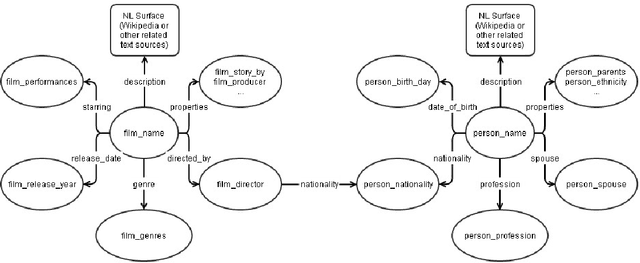
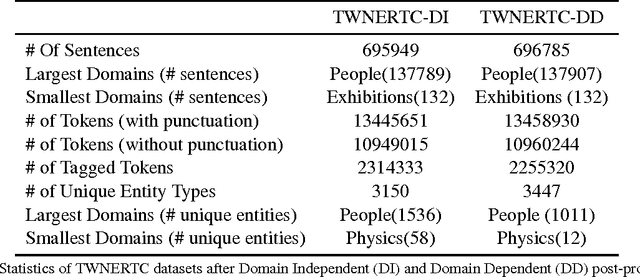

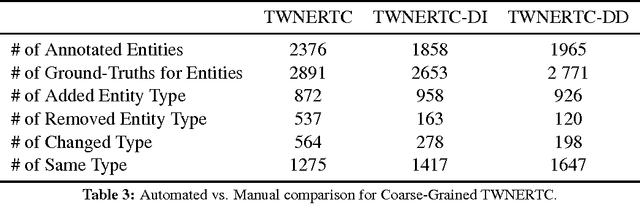
Turkish Wikipedia Named-Entity Recognition and Text Categorization (TWNERTC) dataset is a collection of automatically categorized and annotated sentences obtained from Wikipedia. We constructed large-scale gazetteers by using a graph crawler algorithm to extract relevant entity and domain information from a semantic knowledge base, Freebase. The constructed gazetteers contains approximately 300K entities with thousands of fine-grained entity types under 77 different domains. Since automated processes are prone to ambiguity, we also introduce two new content specific noise reduction methodologies. Moreover, we map fine-grained entity types to the equivalent four coarse-grained types: person, loc, org, misc. Eventually, we construct six different dataset versions and evaluate the quality of annotations by comparing ground truths from human annotators. We make these datasets publicly available to support studies on Turkish named-entity recognition (NER) and text categorization (TC).