 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Reproduction Study: The Kernel PCA Interpretation of Self-Attention Fails Under Scrutiny
May 12, 2025In this reproduction study, we revisit recent claims that self-attention implements kernel principal component analysis (KPCA) (Teo et al., 2024), positing that (i) value vectors $V$ capture the eigenvectors of the Gram matrix of the keys, and (ii) that self-attention projects queries onto the principal component axes of the key matrix $K$ in a feature space. Our analysis reveals three critical inconsistencies: (1) No alignment exists between learned self-attention value vectors and what is proposed in the KPCA perspective, with average similarity metrics (optimal cosine similarity $\leq 0.32$, linear CKA (Centered Kernel Alignment) $\leq 0.11$, kernel CKA $\leq 0.32$) indicating negligible correspondence; (2) Reported decreases in reconstruction loss $J_\text{proj}$, arguably justifying the claim that the self-attention minimizes the projection error of KPCA, are misinterpreted, as the quantities involved differ by orders of magnitude ($\sim\!10^3$); (3) Gram matrix eigenvalue statistics, introduced to justify that $V$ captures the eigenvector of the gram matrix, are irreproducible without undocumented implementation-specific adjustments. Across 10 transformer architectures, we conclude that the KPCA interpretation of self-attention lacks empirical support.
A Systematic Review on the Evaluation of Large Language Models in Theory of Mind Tasks
Feb 12, 2025In recent years, evaluating the Theory of Mind (ToM) capabilities of large language models (LLMs) has received significant attention within the research community. As the field rapidly evolves, navigating the diverse approaches and methodologies has become increasingly complex. This systematic review synthesizes current efforts to assess LLMs' ability to perform ToM tasks, an essential aspect of human cognition involving the attribution of mental states to oneself and others. Despite notable advancements, the proficiency of LLMs in ToM remains a contentious issue. By categorizing benchmarks and tasks through a taxonomy rooted in cognitive science, this review critically examines evaluation techniques, prompting strategies, and the inherent limitations of LLMs in replicating human-like mental state reasoning. A recurring theme in the literature reveals that while LLMs demonstrate emerging competence in ToM tasks, significant gaps persist in their emulation of human cognitive abilities.
A Data-Centric Approach: Dimensions of Visual Complexity and How to find Them
Jan 27, 2025


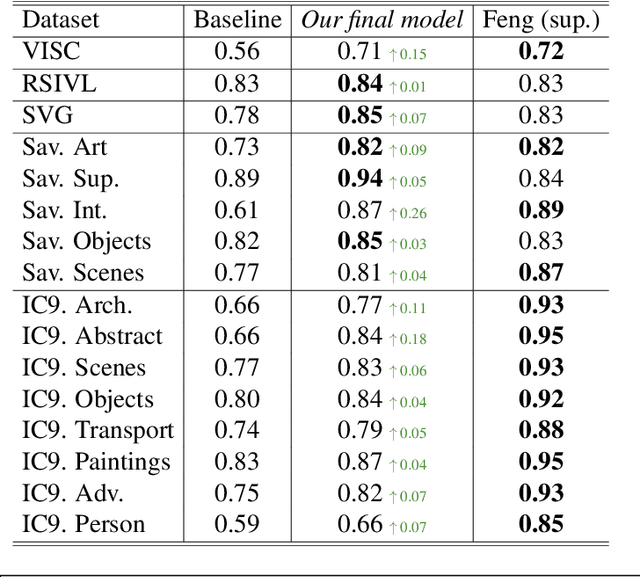
Understanding how humans perceive visual complexity is a key area of study in visual cognition. Previous approaches to modeling visual complexity have often resulted in intricate, difficult-to-interpret solutions that employ numerous features or sophisticated deep learning architectures. While these complex models achieve high performance on specific datasets, they often sacrifice interpretability, making it challenging to understand the factors driving human perception of complexity. A recent model based on image segmentations showed promise in addressing this challenge; however, it presented limitations in capturing structural and semantic aspects of visual complexity. In this paper, we propose viable and effective features to overcome these shortcomings. Specifically, we develop multiscale features for the structural aspect of complexity, including the Multiscale Sobel Gradient (MSG), which captures spatial intensity variations across scales, and Multiscale Unique Colors (MUC), which quantifies image colorfulness by indexing quantized RGB values. We also introduce a new dataset SVG based on Visual Genome to explore the semantic aspect of visual complexity, obtaining surprise scores based on the element of surprise in images, which we demonstrate significantly contributes to perceived complexity. Overall, we suggest that the nature of the data is fundamental to understanding and modeling visual complexity, highlighting the importance of both structural and semantic dimensions in providing a comprehensive, interpretable assessment. The code for our analysis, experimental setup, and dataset will be made publicly available upon acceptance.
Evaluating Self-Supervised Learning in Medical Imaging: A Benchmark for Robustness, Generalizability, and Multi-Domain Impact
Dec 26, 2024Self-supervised learning (SSL) has emerged as a promising paradigm in medical imaging, addressing the chronic challenge of limited labeled data in healthcare settings. While SSL has shown impressive results, existing studies in the medical domain are often limited in scope, focusing on specific datasets or modalities, or evaluating only isolated aspects of model performance. This fragmented evaluation approach poses a significant challenge, as models deployed in critical medical settings must not only achieve high accuracy but also demonstrate robust performance and generalizability across diverse datasets and varying conditions. To address this gap, we present a comprehensive evaluation of SSL methods within the medical domain, with a particular focus on robustness and generalizability. Using the MedMNIST dataset collection as a standardized benchmark, we evaluate 8 major SSL methods across 11 different medical datasets. Our study provides an in-depth analysis of model performance in both in-domain scenarios and the detection of out-of-distribution (OOD) samples, while exploring the effect of various initialization strategies, model architectures, and multi-domain pre-training. We further assess the generalizability of SSL methods through cross-dataset evaluations and the in-domain performance with varying label proportions (1%, 10%, and 100%) to simulate real-world scenarios with limited supervision. We hope this comprehensive benchmark helps practitioners and researchers make more informed decisions when applying SSL methods to medical applications.
A Comprehensive Analysis of Static Word Embeddings for Turkish
May 13, 2024



Word embeddings are fixed-length, dense and distributed word representations that are used in natural language processing (NLP) applications. There are basically two types of word embedding models which are non-contextual (static) models and contextual models. The former method generates a single embedding for a word regardless of its context, while the latter method produces distinct embeddings for a word based on the specific contexts in which it appears. There are plenty of works that compare contextual and non-contextual embedding models within their respective groups in different languages. However, the number of studies that compare the models in these two groups with each other is very few and there is no such study in Turkish. This process necessitates converting contextual embeddings into static embeddings. In this paper, we compare and evaluate the performance of several contextual and non-contextual models in both intrinsic and extrinsic evaluation settings for Turkish. We make a fine-grained comparison by analyzing the syntactic and semantic capabilities of the models separately. The results of the analyses provide insights about the suitability of different embedding models in different types of NLP tasks. We also build a Turkish word embedding repository comprising the embedding models used in this work, which may serve as a valuable resource for researchers and practitioners in the field of Turkish NLP. We make the word embeddings, scripts, and evaluation datasets publicly available.