 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePencils to Pixels: A Systematic Study of Creative Drawings across Children, Adults and AI
Feb 09, 2025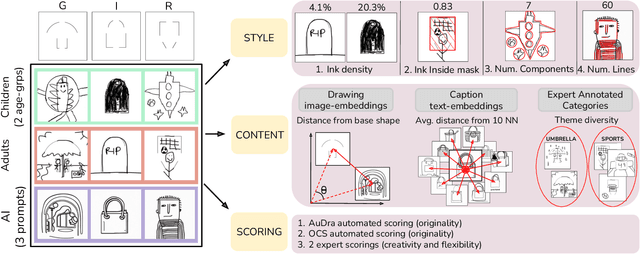
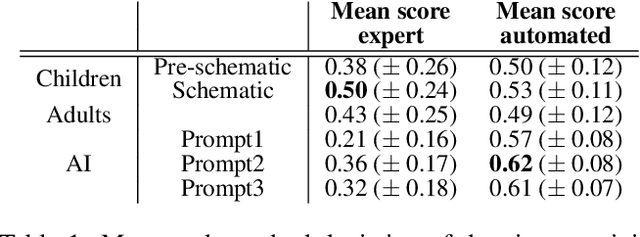
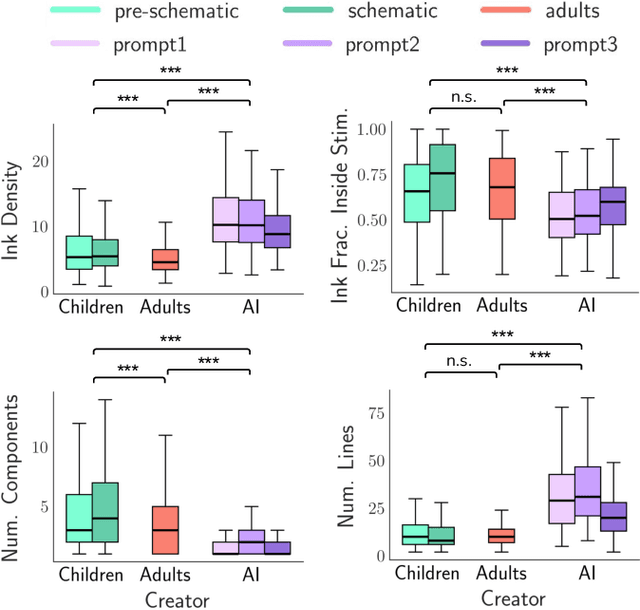

Can we derive computational metrics to quantify visual creativity in drawings across intelligent agents, while accounting for inherent differences in technical skill and style? To answer this, we curate a novel dataset consisting of 1338 drawings by children, adults and AI on a creative drawing task. We characterize two aspects of the drawings -- (1) style and (2) content. For style, we define measures of ink density, ink distribution and number of elements. For content, we use expert-annotated categories to study conceptual diversity, and image and text embeddings to compute distance measures. We compare the style, content and creativity of children, adults and AI drawings and build simple models to predict expert and automated creativity scores. We find significant differences in style and content in the groups -- children's drawings had more components, AI drawings had greater ink density, and adult drawings revealed maximum conceptual diversity. Notably, we highlight a misalignment between creativity judgments obtained through expert and automated ratings and discuss its implications. Through these efforts, our work provides, to the best of our knowledge, the first framework for studying human and artificial creativity beyond the textual modality, and attempts to arrive at the domain-agnostic principles underlying creativity. Our data and scripts are available on GitHub.
A Data-Centric Approach: Dimensions of Visual Complexity and How to find Them
Jan 27, 2025


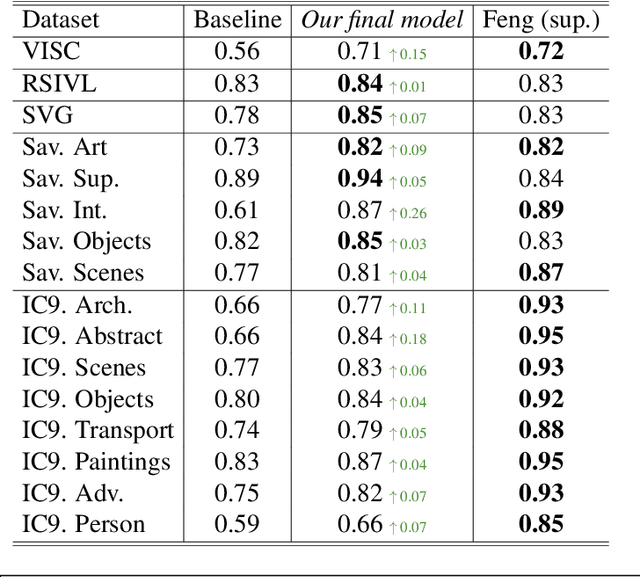
Understanding how humans perceive visual complexity is a key area of study in visual cognition. Previous approaches to modeling visual complexity have often resulted in intricate, difficult-to-interpret solutions that employ numerous features or sophisticated deep learning architectures. While these complex models achieve high performance on specific datasets, they often sacrifice interpretability, making it challenging to understand the factors driving human perception of complexity. A recent model based on image segmentations showed promise in addressing this challenge; however, it presented limitations in capturing structural and semantic aspects of visual complexity. In this paper, we propose viable and effective features to overcome these shortcomings. Specifically, we develop multiscale features for the structural aspect of complexity, including the Multiscale Sobel Gradient (MSG), which captures spatial intensity variations across scales, and Multiscale Unique Colors (MUC), which quantifies image colorfulness by indexing quantized RGB values. We also introduce a new dataset SVG based on Visual Genome to explore the semantic aspect of visual complexity, obtaining surprise scores based on the element of surprise in images, which we demonstrate significantly contributes to perceived complexity. Overall, we suggest that the nature of the data is fundamental to understanding and modeling visual complexity, highlighting the importance of both structural and semantic dimensions in providing a comprehensive, interpretable assessment. The code for our analysis, experimental setup, and dataset will be made publicly available upon acceptance.
Simplicity in Complexity
Mar 05, 2024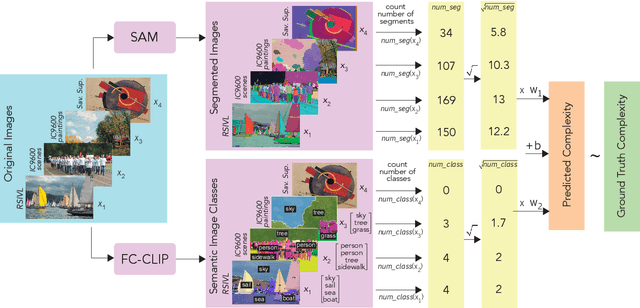
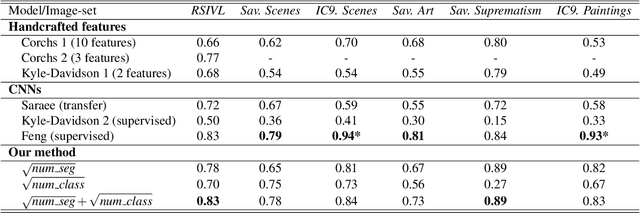
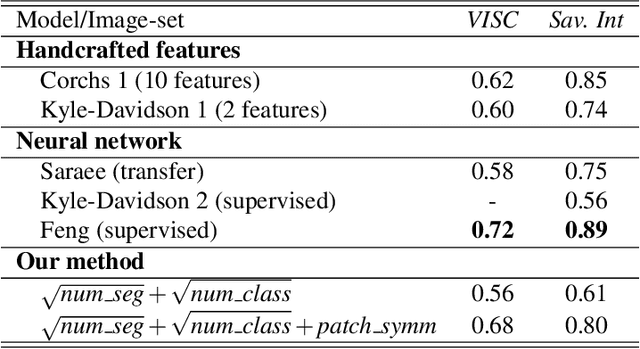

The complexity of visual stimuli plays an important role in many cognitive phenomena, including attention, engagement, memorability, time perception and aesthetic evaluation. Despite its importance, complexity is poorly understood and ironically, previous models of image complexity have been quite \textit{complex}. There have been many attempts to find handcrafted features that explain complexity, but these features are usually dataset specific, and hence fail to generalise. On the other hand, more recent work has employed deep neural networks to predict complexity, but these models remain difficult to interpret, and do not guide a theoretical understanding of the problem. Here we propose to model complexity using segment-based representations of images. We use state-of-the-art segmentation models, SAM and FC-CLIP, to quantify the number of segments at multiple granularities, and the number of classes in an image respectively. We find that complexity is well-explained by a simple linear model with these two features across six diverse image-sets of naturalistic scene and art images. This suggests that the complexity of images can be surprisingly simple.
Universal EEG Encoder for Learning Diverse Intelligent Tasks
Nov 26, 2019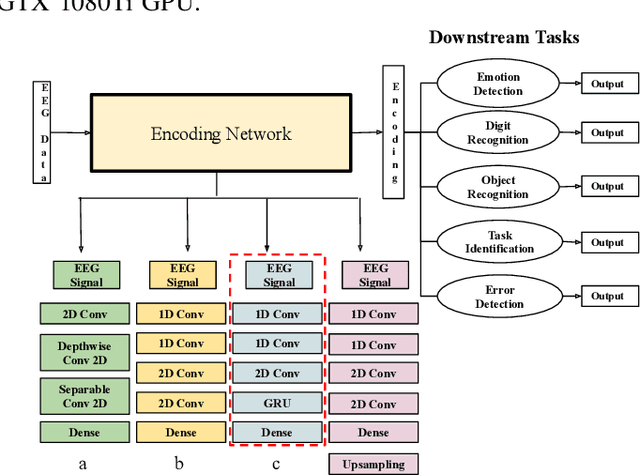
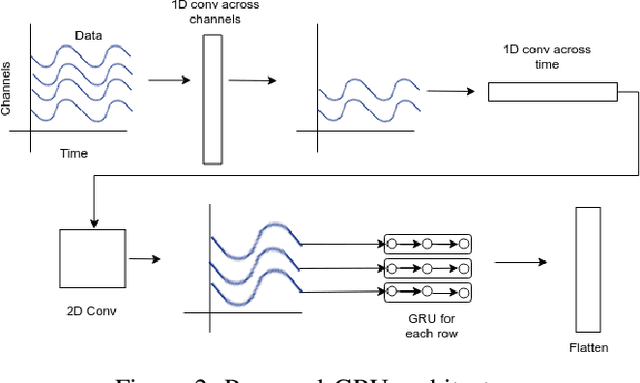
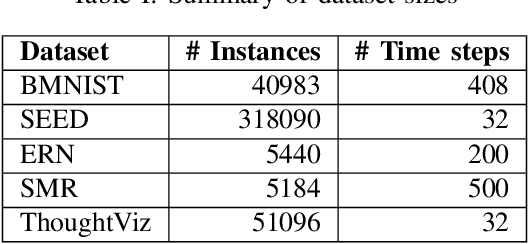

Brain Computer Interfaces (BCI) have become very popular with Electroencephalography (EEG) being one of the most commonly used signal acquisition techniques. A major challenge in BCI studies is the individualistic analysis required for each task. Thus, task-specific feature extraction and classification are performed, which fails to generalize to other tasks with similar time-series EEG input data. To this end, we design a GRU-based universal deep encoding architecture to extract meaningful features from publicly available datasets for five diverse EEG-based classification tasks. Our network can generate task and format-independent data representation and outperform the state of the art EEGNet architecture on most experiments. We also compare our results with CNN-based, and Autoencoder networks, in turn performing local, spatial, temporal and unsupervised analysis on the data.