 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReflections from the 2024 Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry
Nov 20, 2024



Here, we present the outcomes from the second Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry, which engaged participants across global hybrid locations, resulting in 34 team submissions. The submissions spanned seven key application areas and demonstrated the diverse utility of LLMs for applications in (1) molecular and material property prediction; (2) molecular and material design; (3) automation and novel interfaces; (4) scientific communication and education; (5) research data management and automation; (6) hypothesis generation and evaluation; and (7) knowledge extraction and reasoning from scientific literature. Each team submission is presented in a summary table with links to the code and as brief papers in the appendix. Beyond team results, we discuss the hackathon event and its hybrid format, which included physical hubs in Toronto, Montreal, San Francisco, Berlin, Lausanne, and Tokyo, alongside a global online hub to enable local and virtual collaboration. Overall, the event highlighted significant improvements in LLM capabilities since the previous year's hackathon, suggesting continued expansion of LLMs for applications in materials science and chemistry research. These outcomes demonstrate the dual utility of LLMs as both multipurpose models for diverse machine learning tasks and platforms for rapid prototyping custom applications in scientific research.
Simplicity in Complexity
Mar 05, 2024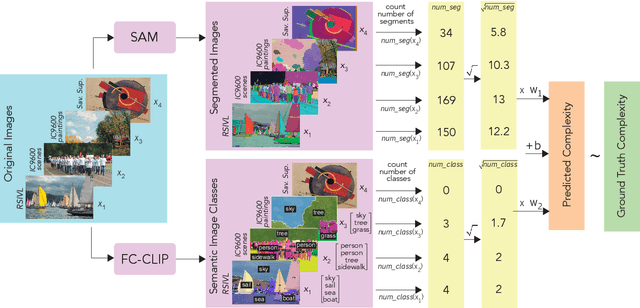
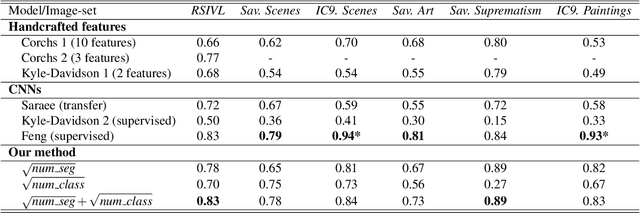
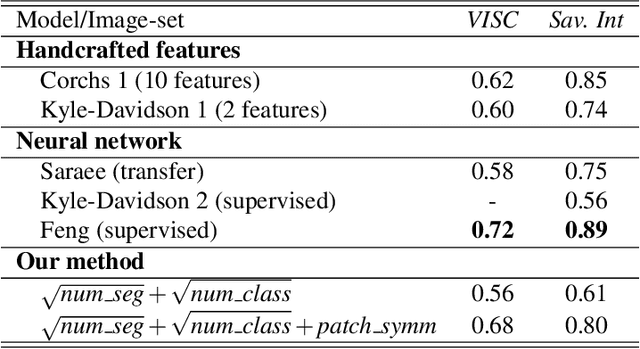

The complexity of visual stimuli plays an important role in many cognitive phenomena, including attention, engagement, memorability, time perception and aesthetic evaluation. Despite its importance, complexity is poorly understood and ironically, previous models of image complexity have been quite \textit{complex}. There have been many attempts to find handcrafted features that explain complexity, but these features are usually dataset specific, and hence fail to generalise. On the other hand, more recent work has employed deep neural networks to predict complexity, but these models remain difficult to interpret, and do not guide a theoretical understanding of the problem. Here we propose to model complexity using segment-based representations of images. We use state-of-the-art segmentation models, SAM and FC-CLIP, to quantify the number of segments at multiple granularities, and the number of classes in an image respectively. We find that complexity is well-explained by a simple linear model with these two features across six diverse image-sets of naturalistic scene and art images. This suggests that the complexity of images can be surprisingly simple.
Classification of the Fashion-MNIST Dataset on a Quantum Computer
Mar 04, 2024The potential impact of quantum machine learning algorithms on industrial applications remains an exciting open question. Conventional methods for encoding classical data into quantum computers are not only too costly for a potential quantum advantage in the algorithms but also severely limit the scale of feasible experiments on current hardware. Therefore, recent works, despite claiming the near-term suitability of their algorithms, do not provide experimental benchmarking on standard machine learning datasets. We attempt to solve the data encoding problem by improving a recently proposed variational algorithm [1] that approximately prepares the encoded data, using asymptotically shallow circuits that fit the native gate set and topology of currently available quantum computers. We apply the improved algorithm to encode the Fashion-MNIST dataset [2], which can be directly used in future empirical studies of quantum machine learning algorithms. We deploy simple quantum variational classifiers trained on the encoded dataset on a current quantum computer ibmq-kolkata [3] and achieve moderate accuracies, providing a proof of concept for the near-term usability of our data encoding method.
Lifelong Learning for Image Captioning by Asking Natural Language Questions
Dec 01, 2018



In order to bring artificial agents into our lives, we will need to go beyond supervised learning on closed datasets to having the ability to continuously expand knowledge. Inspired by a student learning in a classroom, we present an agent that can continuously learn by posing natural language questions to humans. Our agent is composed of three interacting modules, one that performs captioning, another that generates questions and a decision maker that learns when to ask questions by implicitly reasoning about the uncertainty of the agent and expertise of the teacher. As compared to current active learning methods which query images for full captions, our agent is able to ask pointed questions to improve the generated captions. The agent trains on the improved captions, expanding its knowledge. We show that our approach achieves better performance using less human supervision than the baselines on the challenging MSCOCO dataset.
Generalized Latent Variable Recovery for Generative Adversarial Networks
Oct 09, 2018



The Generator of a Generative Adversarial Network (GAN) is trained to transform latent vectors drawn from a prior distribution into realistic looking photos. These latent vectors have been shown to encode information about the content of their corresponding images. Projecting input images onto the latent space of a GAN is non-trivial, but previous work has successfully performed this task for latent spaces with a uniform prior. We extend these techniques to latent spaces with a Gaussian prior, and demonstrate our technique's effectiveness.
Are You Sure You Want To Do That? Classification with Verification
Sep 13, 2018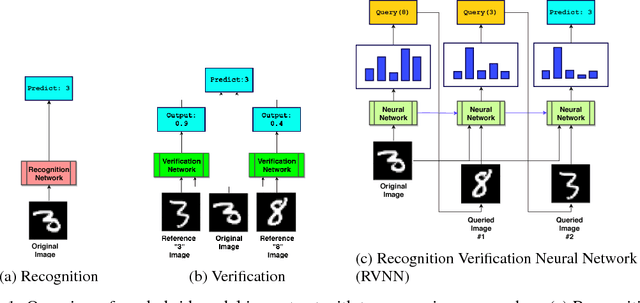

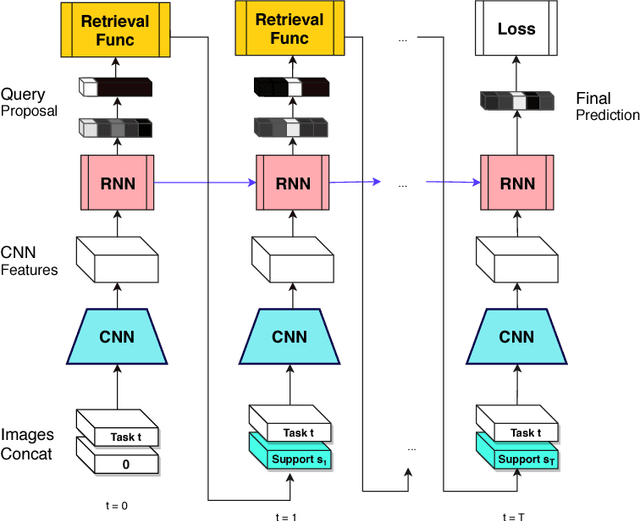

Classification systems typically act in isolation, meaning they are required to implicitly memorize the characteristics of all candidate classes in order to classify. The cost of this is increased memory usage and poor sample efficiency. We propose a model which instead verifies using reference images during the classification process, reducing the burden of memorization. The model uses iterative nondifferentiable queries in order to classify an image. We demonstrate that such a model is feasible to train and can match baseline accuracy while being more parameter efficient. However, we show that finding the correct balance between image recognition and verification is essential to pushing the model towards desired behavior, suggesting that a pipeline of recognition followed by verification is a more promising approach.