 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Shmoop Corpus: A Dataset of Stories with Loosely Aligned Summaries
Jan 01, 2020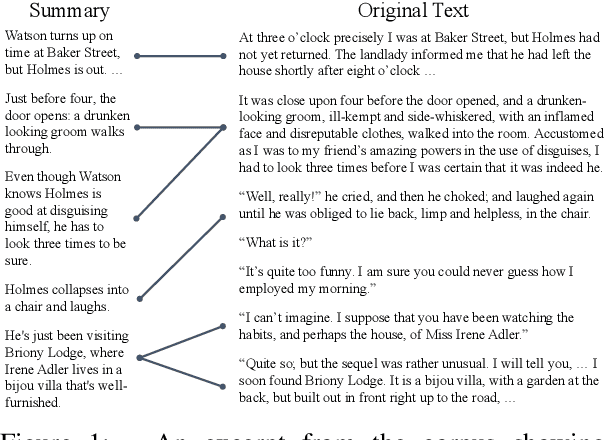
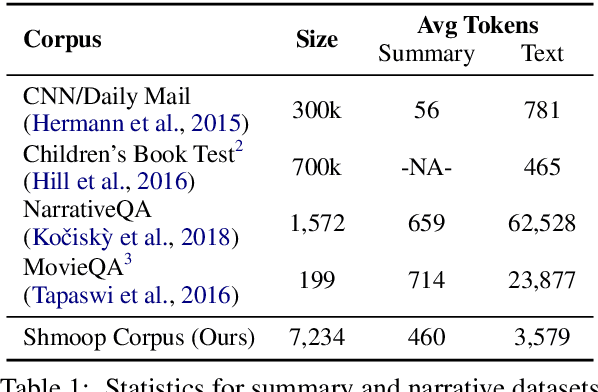
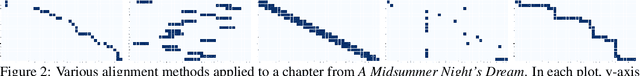
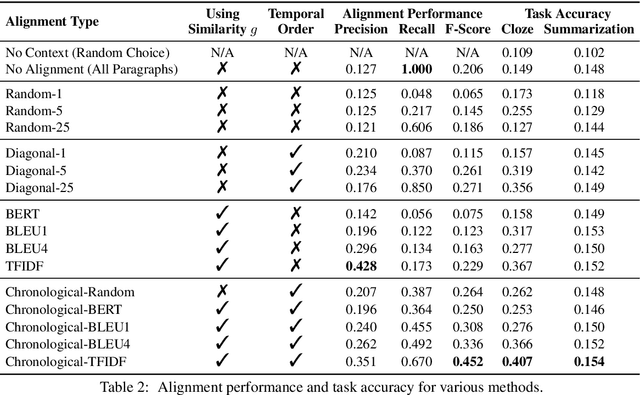
Understanding stories is a challenging reading comprehension problem for machines as it requires reading a large volume of text and following long-range dependencies. In this paper, we introduce the Shmoop Corpus: a dataset of 231 stories that are paired with detailed multi-paragraph summaries for each individual chapter (7,234 chapters), where the summary is chronologically aligned with respect to the story chapter. From the corpus, we construct a set of common NLP tasks, including Cloze-form question answering and a simplified form of abstractive summarization, as benchmarks for reading comprehension on stories. We then show that the chronological alignment provides a strong supervisory signal that learning-based methods can exploit leading to significant improvements on these tasks. We believe that the unique structure of this corpus provides an important foothold towards making machine story comprehension more approachable.
Are You Sure You Want To Do That? Classification with Verification
Sep 13, 2018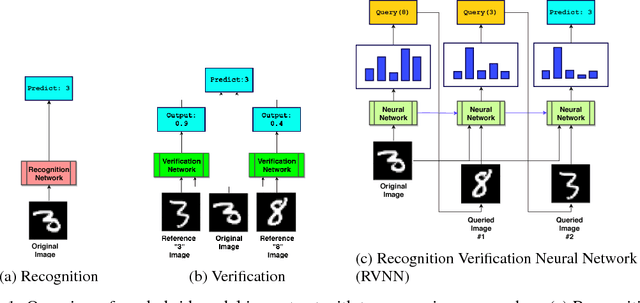


Classification systems typically act in isolation, meaning they are required to implicitly memorize the characteristics of all candidate classes in order to classify. The cost of this is increased memory usage and poor sample efficiency. We propose a model which instead verifies using reference images during the classification process, reducing the burden of memorization. The model uses iterative nondifferentiable queries in order to classify an image. We demonstrate that such a model is feasible to train and can match baseline accuracy while being more parameter efficient. However, we show that finding the correct balance between image recognition and verification is essential to pushing the model towards desired behavior, suggesting that a pipeline of recognition followed by verification is a more promising approach.