 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre You Sure You Want To Do That? Classification with Verification
Paper and Code
Sep 13, 2018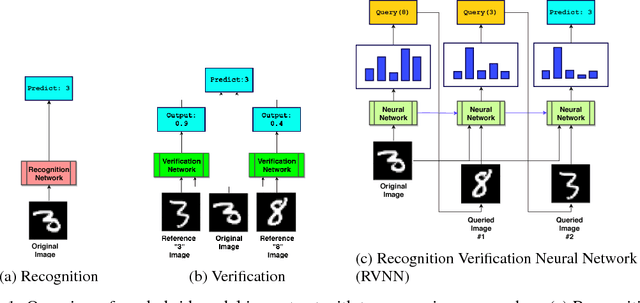

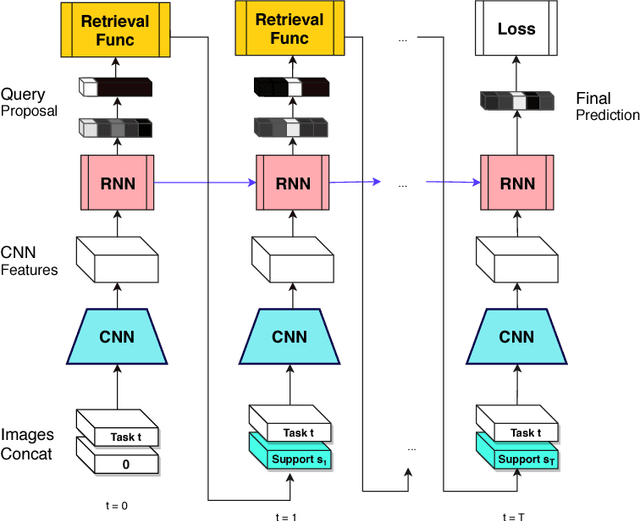

Classification systems typically act in isolation, meaning they are required to implicitly memorize the characteristics of all candidate classes in order to classify. The cost of this is increased memory usage and poor sample efficiency. We propose a model which instead verifies using reference images during the classification process, reducing the burden of memorization. The model uses iterative nondifferentiable queries in order to classify an image. We demonstrate that such a model is feasible to train and can match baseline accuracy while being more parameter efficient. However, we show that finding the correct balance between image recognition and verification is essential to pushing the model towards desired behavior, suggesting that a pipeline of recognition followed by verification is a more promising approach.