 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAGC-Bench: Measuring Artificial General Creativity
Jul 01, 2026Creativity research has debated whether creativity is domain-specific (e.g., visual, writing, science), and if it is psychometrically separable from general intelligence. Both questions now apply to LLMs, but a unified benchmark of AI creativity remains elusive. We introduce AGC-Bench, an artificial general creativity benchmark built from a systematic review of the AI creativity literature (3,101 papers screened, 497 benchmarks identified), paired with an agentic harness that converts idiosyncratic codebases into HELM-standardized benchmarks. The first release covers 78 datasets spanning brainstorming, problem solving, STEM, narrative, figurative language, and humor. To address bias in LLM-as-judge, we apply Judge Response Theory -- a psychometric calibration of judge leniency/severity; we then fine-tune Qwen3-30B on the bias-corrected ratings of three frontier LLMs to produce AGC-Judge, an open-weight model that robustly scores new creativity benchmarks it was not trained on. Results reveal frontier models at the top of the AGC-Bench leaderboard, with open models close behind. LLMs show different creative strengths, ranking higher on some domains (e.g., writing) than others (e.g., scientific ideation). Extensive experiments yield three main findings. First, applying factor analysis across 83 LLMs, we recover a single creativity factor 'c', analogous to the 'g' factor of general intelligence, that explains 81.5% of variance, related to but separable from general knowledge/reasoning. Second, we show that prompting models to "be creative" boosts their performance far more than enabling reasoning, evidence that the benchmark tracks creativity over general ability. Third, on a human-matched subset, we find the top human still leads the top LLM on creativity. We release AGC-Bench with a public leaderboard, AGC-Judge, and human data as open infrastructure for measuring AI creativity at scale.
Transformer See, Transformer Do: Copying as an Intermediate Step in Learning Analogical Reasoning
Apr 07, 2026Analogical reasoning is a hallmark of human intelligence, enabling us to solve new problems by transferring knowledge from one situation to another. Yet, developing artificial intelligence systems capable of robust human-like analogical reasoning has proven difficult. In this work, we train transformers using Meta-Learning for Compositionality (MLC) on an analogical reasoning task (letter-string analogies) and assess their generalization capabilities. We find that letter-string analogies become learnable when guiding the models to attend to the most informative problem elements induced by including copying tasks in the training data. Furthermore, generalization to new alphabets becomes better when models are trained with more heterogeneous datasets, where our 3-layer encoder-decoder model outperforms most frontier models. The MLC approach also enables some generalization to compositions of trained transformations, but not to completely novel transformations. To understand how the model operates, we identify an algorithm that approximates the model's computations. We verify this using interpretability analyses and show that the model can be steered precisely according to expectations derived from the algorithm. Finally, we discuss implications of our findings for generalization capabilities of larger models and parallels to human analogical reasoning.
Causality $ eq$ Invariance: Function and Concept Vectors in LLMs
Feb 25, 2026Do large language models (LLMs) represent concepts abstractly, i.e., independent of input format? We revisit Function Vectors (FVs), compact representations of in-context learning (ICL) tasks that causally drive task performance. Across multiple LLMs, we show that FVs are not fully invariant: FVs are nearly orthogonal when extracted from different input formats (e.g., open-ended vs. multiple-choice), even if both target the same concept. We identify Concept Vectors (CVs), which carry more stable concept representations. Like FVs, CVs are composed of attention head outputs; however, unlike FVs, the constituent heads are selected using Representational Similarity Analysis (RSA) based on whether they encode concepts consistently across input formats. While these heads emerge in similar layers to FV-related heads, the two sets are largely distinct, suggesting different underlying mechanisms. Steering experiments reveal that FVs excel in-distribution, when extraction and application formats match (e.g., both open-ended in English), while CVs generalize better out-of-distribution across both question types (open-ended vs. multiple-choice) and languages. Our results show that LLMs do contain abstract concept representations, but these differ from those that drive ICL performance.
Analogical Reasoning Inside Large Language Models: Concept Vectors and the Limits of Abstraction
Mar 05, 2025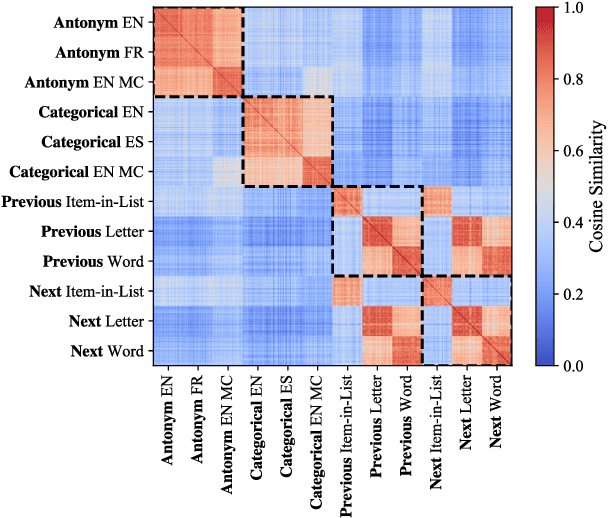
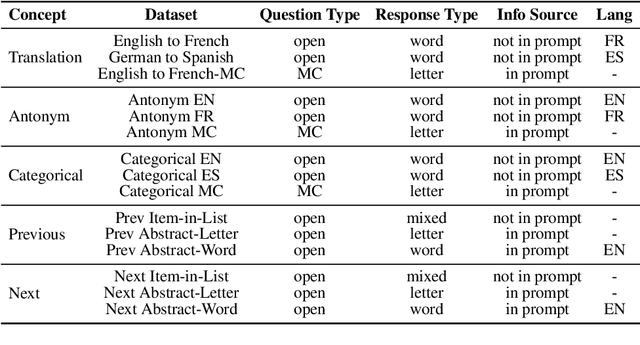
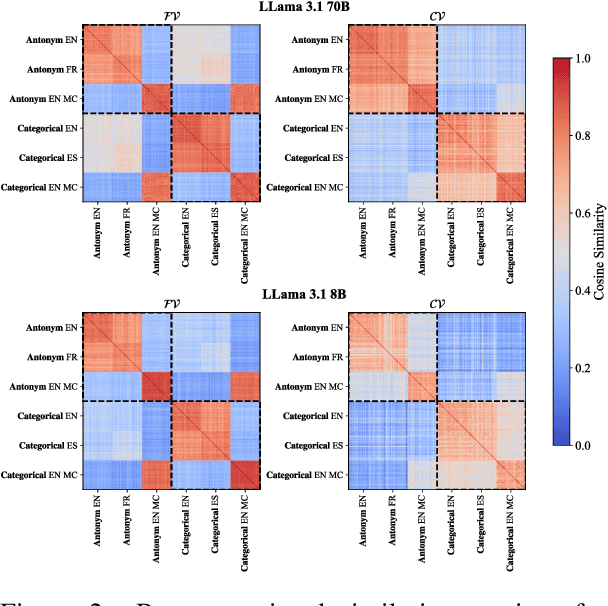

Analogical reasoning relies on conceptual abstractions, but it is unclear whether Large Language Models (LLMs) harbor such internal representations. We explore distilled representations from LLM activations and find that function vectors (FVs; Todd et al., 2024) - compact representations for in-context learning (ICL) tasks - are not invariant to simple input changes (e.g., open-ended vs. multiple-choice), suggesting they capture more than pure concepts. Using representational similarity analysis (RSA), we localize a small set of attention heads that encode invariant concept vectors (CVs) for verbal concepts like "antonym". These CVs function as feature detectors that operate independently of the final output - meaning that a model may form a correct internal representation yet still produce an incorrect output. Furthermore, CVs can be used to causally guide model behaviour. However, for more abstract concepts like "previous" and "next", we do not observe invariant linear representations, a finding we link to generalizability issues LLMs display within these domains.
Pencils to Pixels: A Systematic Study of Creative Drawings across Children, Adults and AI
Feb 09, 2025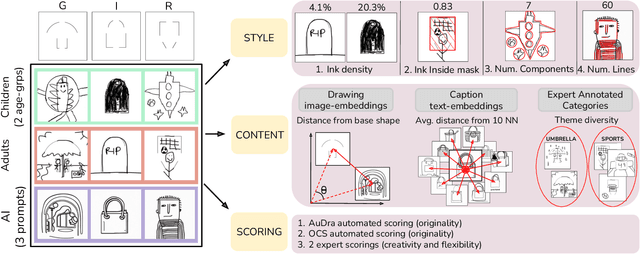
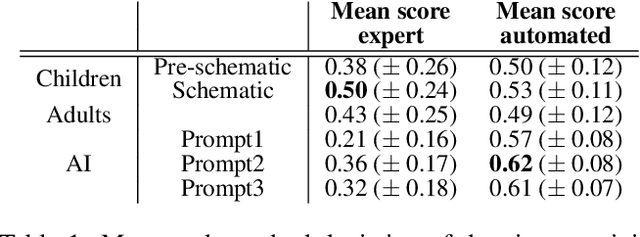
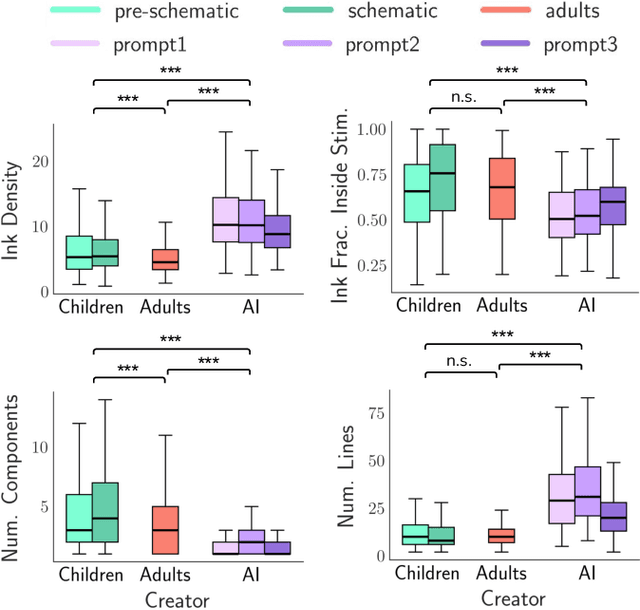

Can we derive computational metrics to quantify visual creativity in drawings across intelligent agents, while accounting for inherent differences in technical skill and style? To answer this, we curate a novel dataset consisting of 1338 drawings by children, adults and AI on a creative drawing task. We characterize two aspects of the drawings -- (1) style and (2) content. For style, we define measures of ink density, ink distribution and number of elements. For content, we use expert-annotated categories to study conceptual diversity, and image and text embeddings to compute distance measures. We compare the style, content and creativity of children, adults and AI drawings and build simple models to predict expert and automated creativity scores. We find significant differences in style and content in the groups -- children's drawings had more components, AI drawings had greater ink density, and adult drawings revealed maximum conceptual diversity. Notably, we highlight a misalignment between creativity judgments obtained through expert and automated ratings and discuss its implications. Through these efforts, our work provides, to the best of our knowledge, the first framework for studying human and artificial creativity beyond the textual modality, and attempts to arrive at the domain-agnostic principles underlying creativity. Our data and scripts are available on GitHub.
Can Large Language Models generalize analogy solving like people can?
Nov 04, 2024



When we solve an analogy we transfer information from a known context to a new one through abstract rules and relational similarity. In people, the ability to solve analogies such as "body : feet :: table : ?" emerges in childhood, and appears to transfer easily to other domains, such as the visual domain "( : ) :: < : ?". Recent research shows that large language models (LLMs) can solve various forms of analogies. However, can LLMs generalize analogy solving to new domains like people can? To investigate this, we had children, adults, and LLMs solve a series of letter-string analogies (e.g., a b : a c :: j k : ?) in the Latin alphabet, in a near transfer domain (Greek alphabet), and a far transfer domain (list of symbols). As expected, children and adults easily generalized their knowledge to unfamiliar domains, whereas LLMs did not. This key difference between human and AI performance is evidence that these LLMs still struggle with robust human-like analogical transfer.
Do Large Language Models Solve ARC Visual Analogies Like People Do?
Mar 13, 2024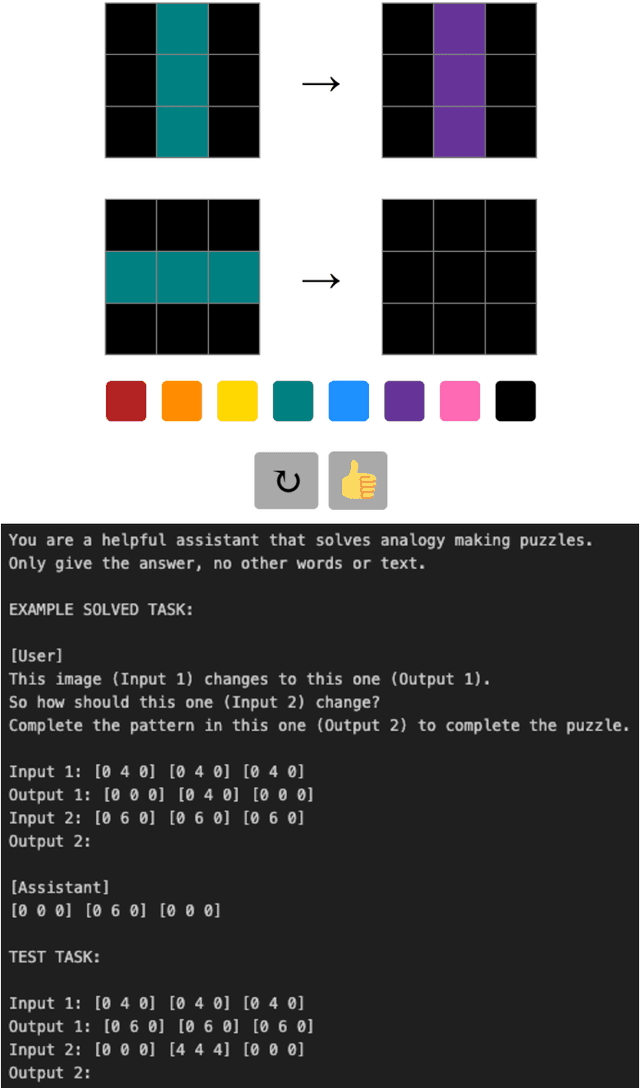

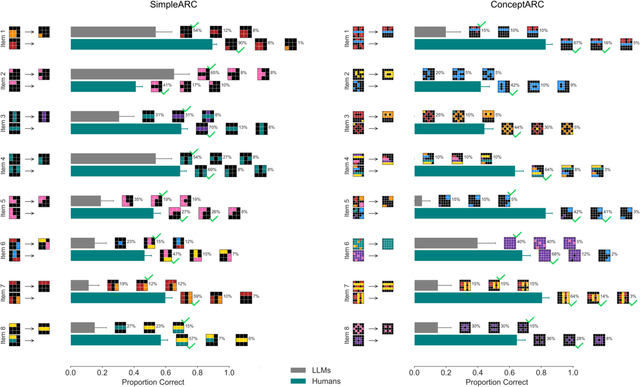
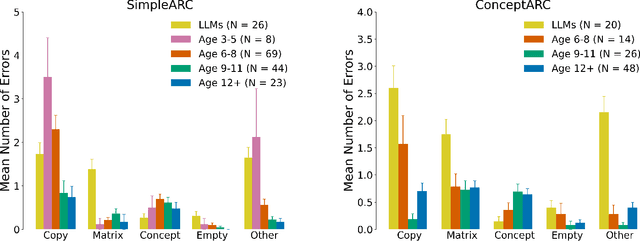
The Abstraction Reasoning Corpus (ARC) is a visual analogical reasoning test designed for humans and machines (Chollet, 2019). We compared human and large language model (LLM) performance on a new child-friendly set of ARC items. Results show that both children and adults outperform most LLMs on these tasks. Error analysis revealed a similar "fallback" solution strategy in LLMs and young children, where part of the analogy is simply copied. In addition, we found two other error types, one based on seemingly grasping key concepts (e.g., Inside-Outside) and the other based on simple combinations of analogy input matrices. On the whole, "concept" errors were more common in humans, and "matrix" errors were more common in LLMs. This study sheds new light on LLM reasoning ability and the extent to which we can use error analyses and comparisons with human development to understand how LLMs solve visual analogies.
Solving ARC visual analogies with neural embeddings and vector arithmetic: A generalized method
Nov 14, 2023



Analogical reasoning derives information from known relations and generalizes this information to similar yet unfamiliar situations. One of the first generalized ways in which deep learning models were able to solve verbal analogies was through vector arithmetic of word embeddings, essentially relating words that were mapped to a vector space (e.g., king - man + woman = __?). In comparison, most attempts to solve visual analogies are still predominantly task-specific and less generalizable. This project focuses on visual analogical reasoning and applies the initial generalized mechanism used to solve verbal analogies to the visual realm. Taking the Abstraction and Reasoning Corpus (ARC) as an example to investigate visual analogy solving, we use a variational autoencoder (VAE) to transform ARC items into low-dimensional latent vectors, analogous to the word embeddings used in the verbal approaches. Through simple vector arithmetic, underlying rules of ARC items are discovered and used to solve them. Results indicate that the approach works well on simple items with fewer dimensions (i.e., few colors used, uniform shapes), similar input-to-output examples, and high reconstruction accuracy on the VAE. Predictions on more complex items showed stronger deviations from expected outputs, although, predictions still often approximated parts of the item's rule set. Error patterns indicated that the model works as intended. On the official ARC paradigm, the model achieved a score of 2% (cf. current world record is 21%) and on ConceptARC it scored 8.8%. Although the methodology proposed involves basic dimensionality reduction techniques and standard vector arithmetic, this approach demonstrates promising outcomes on ARC and can easily be generalized to other abstract visual reasoning tasks.
Do large language models solve verbal analogies like children do?
Oct 31, 2023
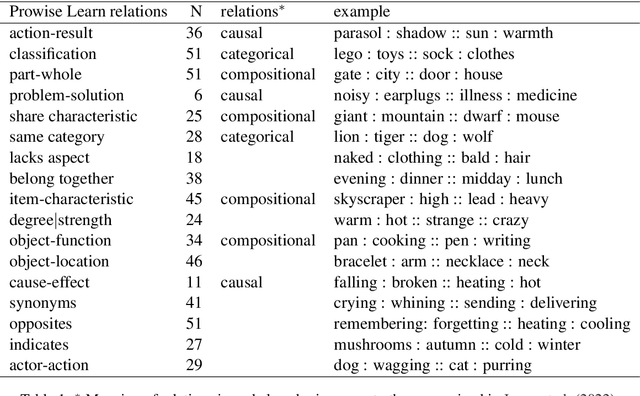
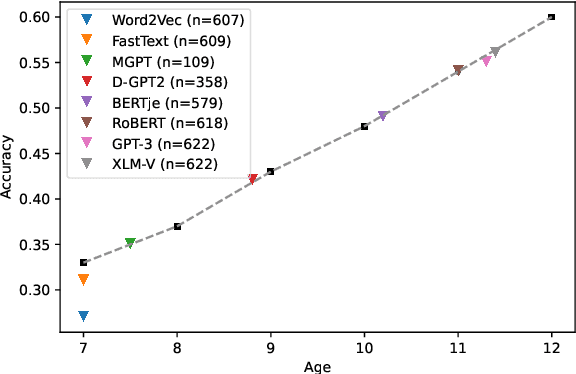
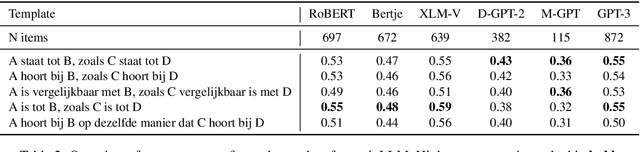
Analogy-making lies at the heart of human cognition. Adults solve analogies such as \textit{Horse belongs to stable like chicken belongs to ...?} by mapping relations (\textit{kept in}) and answering \textit{chicken coop}. In contrast, children often use association, e.g., answering \textit{egg}. This paper investigates whether large language models (LLMs) solve verbal analogies in A:B::C:? form using associations, similar to what children do. We use verbal analogies extracted from an online adaptive learning environment, where 14,002 7-12 year-olds from the Netherlands solved 622 analogies in Dutch. The six tested Dutch monolingual and multilingual LLMs performed around the same level as children, with MGPT performing worst, around the 7-year-old level, and XLM-V and GPT-3 the best, slightly above the 11-year-old level. However, when we control for associative processes this picture changes and each model's performance level drops 1-2 years. Further experiments demonstrate that associative processes often underlie correctly solved analogies. We conclude that the LLMs we tested indeed tend to solve verbal analogies by association with C like children do.