 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausality $ eq$ Invariance: Function and Concept Vectors in LLMs
Feb 25, 2026Do large language models (LLMs) represent concepts abstractly, i.e., independent of input format? We revisit Function Vectors (FVs), compact representations of in-context learning (ICL) tasks that causally drive task performance. Across multiple LLMs, we show that FVs are not fully invariant: FVs are nearly orthogonal when extracted from different input formats (e.g., open-ended vs. multiple-choice), even if both target the same concept. We identify Concept Vectors (CVs), which carry more stable concept representations. Like FVs, CVs are composed of attention head outputs; however, unlike FVs, the constituent heads are selected using Representational Similarity Analysis (RSA) based on whether they encode concepts consistently across input formats. While these heads emerge in similar layers to FV-related heads, the two sets are largely distinct, suggesting different underlying mechanisms. Steering experiments reveal that FVs excel in-distribution, when extraction and application formats match (e.g., both open-ended in English), while CVs generalize better out-of-distribution across both question types (open-ended vs. multiple-choice) and languages. Our results show that LLMs do contain abstract concept representations, but these differ from those that drive ICL performance.
What makes for an enjoyable protagonist? An analysis of character warmth and competence
Jan 10, 2026Drawing on psychological and literary theory, we investigated whether the warmth and competence of movie protagonists predict IMDb ratings, and whether these effects vary across genres. Using 2,858 films and series from the Movie Scripts Corpus, we identified protagonists via AI-assisted annotation and quantified their warmth and competence with the LLM_annotate package ([1]; human-LLM agreement: r = .83). Preregistered Bayesian regression analyses revealed theory-consistent but small associations between both warmth and competence and audience ratings, while genre-specific interactions did not meaningfully improve predictions. Male protagonists were slightly less warm than female protagonists, and movies with male leads received higher ratings on average (an association that was multiple times stronger than the relationships between movie ratings and warmth/competence). These findings suggest that, although audiences tend to favor warm, competent characters, the effects on movie evaluations are modest, indicating that character personality is only one of many factors shaping movie ratings. AI-assisted annotation with LLM_annotate and gpt-4.1-mini proved effective for large-scale analyses but occasionally fell short of manually generated annotations.
LLM_annotate: A Python package for annotating and analyzing fiction characters
Dec 24, 2025LLM_annotate is a Python package for analyzing the personality of fiction characters with large language models. It standardizes workflows for annotating character behaviors in full texts (e.g., books and movie scripts), inferring character traits, and validating annotation/inference quality via a human-in-the-loop GUI. The package includes functions for text chunking, LLM-based annotation, character name disambiguation, quality scoring, and computation of character-level statistics and embeddings. Researchers can use any LLM, commercial, open-source, or custom, within LLM_annotate. Through tutorial examples using The Simpsons Movie and the novel Pride and Prejudice, I demonstrate the usage of the package for efficient and reproducible character analyses.
Which books do I like?
Mar 05, 2025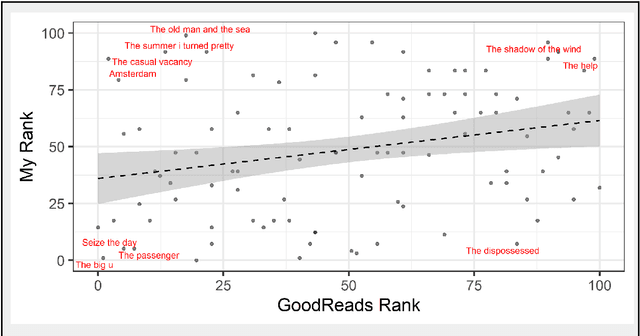
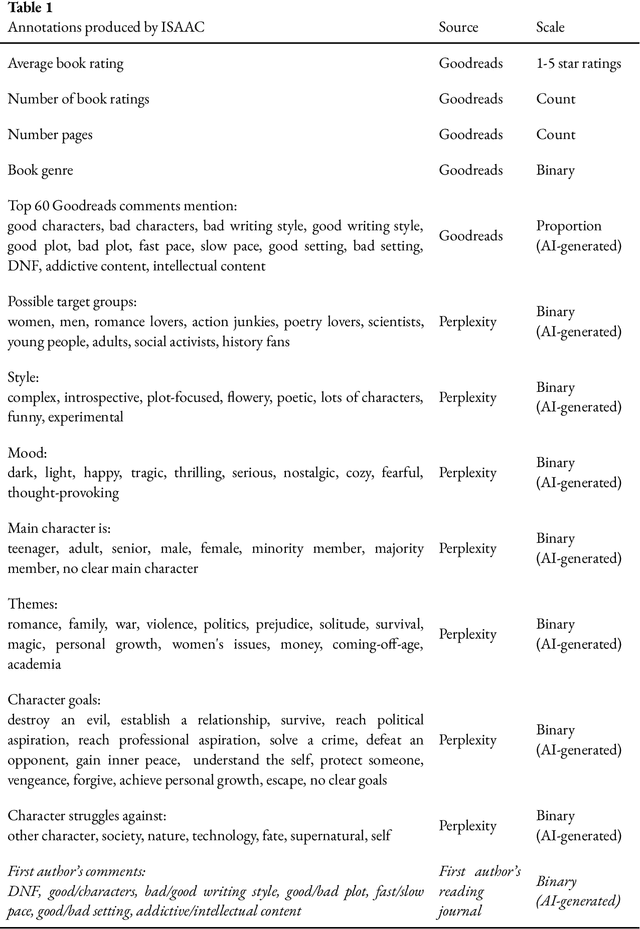
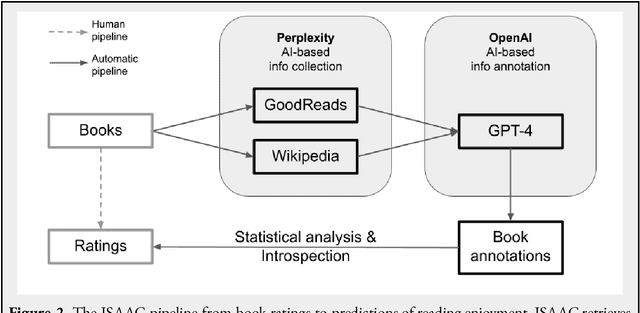
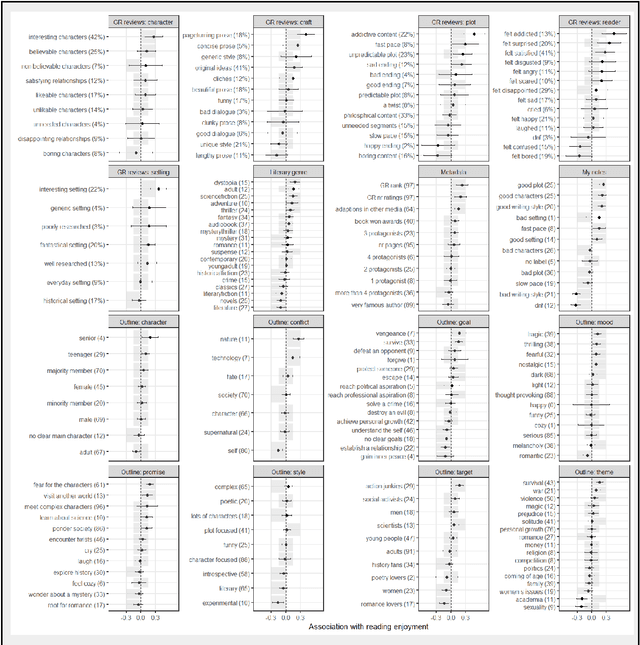
Finding enjoyable fiction books can be challenging, partly because stories are multi-faceted and one's own literary taste might be difficult to ascertain. Here, we introduce the ISAAC method (Introspection-Support, AI-Annotation, and Curation), a pipeline which supports fiction readers in gaining awareness of their literary preferences and finding enjoyable books. ISAAC consists of four steps: a user supplies book ratings, an AI agent researches and annotates the provided books, patterns in book enjoyment are reviewed by the user, and the AI agent recommends new books. In this proof-of-concept self-study, the authors test whether ISAAC can highlight idiosyncratic patterns in their book enjoyment, spark a deeper reflection about their literary tastes, and make accurate, personalized recommendations of enjoyable books and underexplored literary niches. Results highlight substantial advantages of ISAAC over existing methods such as an integration of automation and intuition, accurate and customizable annotations, and explainable book recommendations. Observed disadvantages are that ISAAC's outputs can elicit false self-narratives (if statistical patterns are taken at face value), that books cannot be annotated if their online documentation is lacking, and that people who are new to reading have to rely on assumed book ratings or movie ratings to power the ISAAC pipeline. We discuss additional opportunities of ISAAC-style book annotations for the study of literary trends, and the scientific classification of books and readers.
Analogical Reasoning Inside Large Language Models: Concept Vectors and the Limits of Abstraction
Mar 05, 2025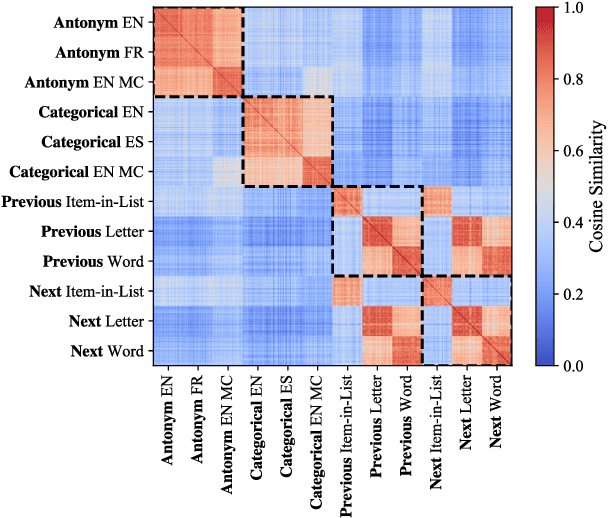
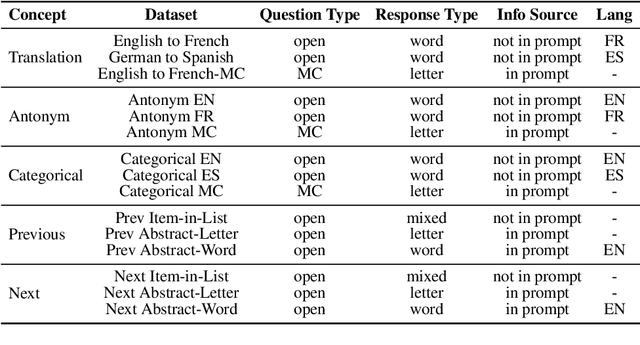
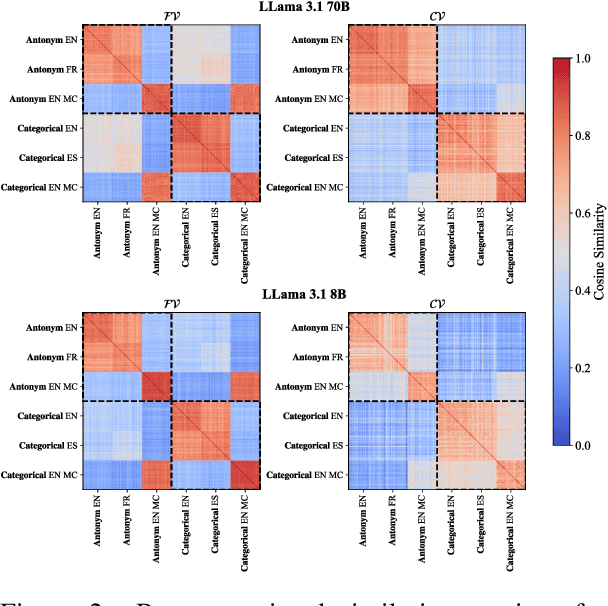

Analogical reasoning relies on conceptual abstractions, but it is unclear whether Large Language Models (LLMs) harbor such internal representations. We explore distilled representations from LLM activations and find that function vectors (FVs; Todd et al., 2024) - compact representations for in-context learning (ICL) tasks - are not invariant to simple input changes (e.g., open-ended vs. multiple-choice), suggesting they capture more than pure concepts. Using representational similarity analysis (RSA), we localize a small set of attention heads that encode invariant concept vectors (CVs) for verbal concepts like "antonym". These CVs function as feature detectors that operate independently of the final output - meaning that a model may form a correct internal representation yet still produce an incorrect output. Furthermore, CVs can be used to causally guide model behaviour. However, for more abstract concepts like "previous" and "next", we do not observe invariant linear representations, a finding we link to generalizability issues LLMs display within these domains.
Are some books better than others?
Mar 04, 2025Scholars, awards committees, and laypeople frequently discuss the merit of written works. Literary professionals and journalists differ in how much perspectivism they concede in their book reviews. Here, we quantify how strongly book reviews are determined by the actual book contents vs. idiosyncratic reader tendencies. In our analysis of 624,320 numerical and textual book reviews, we find that the contents of professionally published books are not predictive of a random reader's reading enjoyment. Online reviews of popular fiction and non-fiction books carry up to ten times more information about the reviewer than about the book. For books of a preferred genre, readers might be less likely to give low ratings, but still struggle to converge in their relative assessments. We find that book evaluations generalize more across experienced review writers than casual readers. When discussing specific issues with a book, one review text had poor predictability of issues brought up in another review of the same book. We conclude that extreme perspectivism is a justifiable position when researching literary quality, bestowing literary awards, and designing recommendation systems.
Do Large Language Models Solve ARC Visual Analogies Like People Do?
Mar 13, 2024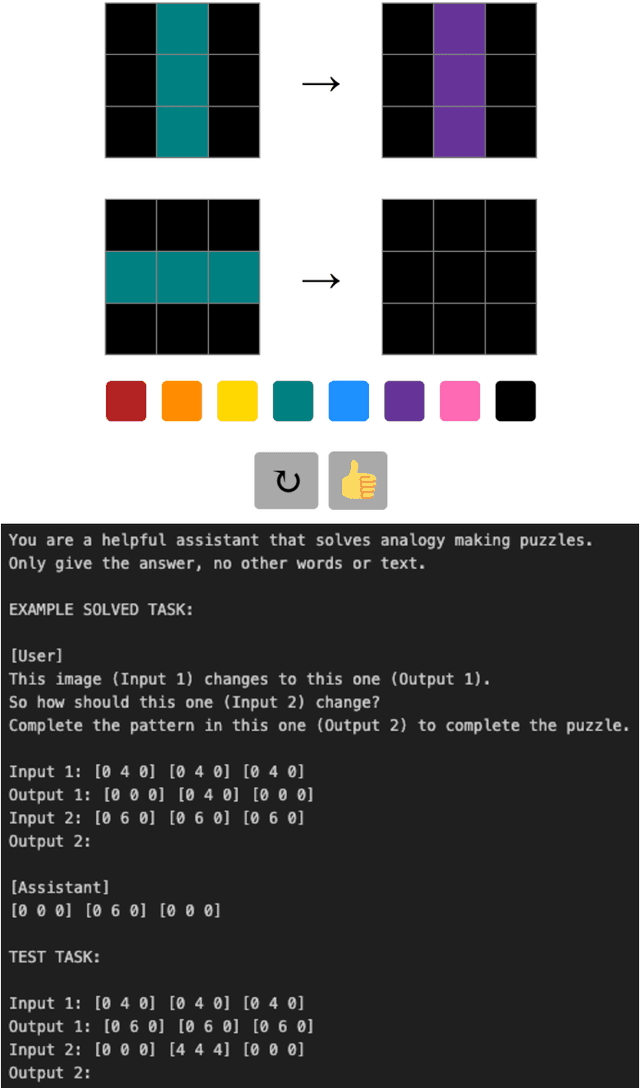

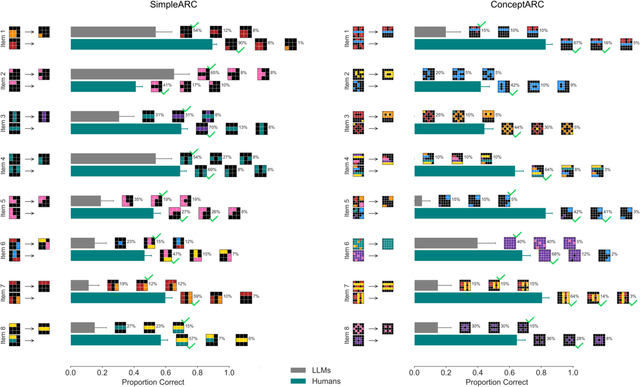
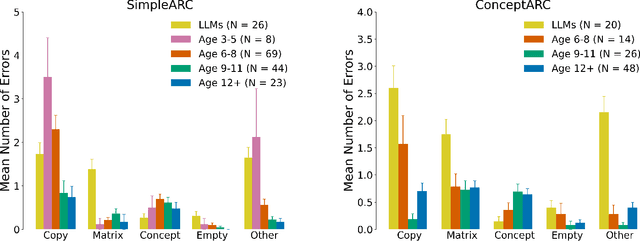
The Abstraction Reasoning Corpus (ARC) is a visual analogical reasoning test designed for humans and machines (Chollet, 2019). We compared human and large language model (LLM) performance on a new child-friendly set of ARC items. Results show that both children and adults outperform most LLMs on these tasks. Error analysis revealed a similar "fallback" solution strategy in LLMs and young children, where part of the analogy is simply copied. In addition, we found two other error types, one based on seemingly grasping key concepts (e.g., Inside-Outside) and the other based on simple combinations of analogy input matrices. On the whole, "concept" errors were more common in humans, and "matrix" errors were more common in LLMs. This study sheds new light on LLM reasoning ability and the extent to which we can use error analyses and comparisons with human development to understand how LLMs solve visual analogies.
Solving ARC visual analogies with neural embeddings and vector arithmetic: A generalized method
Nov 14, 2023



Analogical reasoning derives information from known relations and generalizes this information to similar yet unfamiliar situations. One of the first generalized ways in which deep learning models were able to solve verbal analogies was through vector arithmetic of word embeddings, essentially relating words that were mapped to a vector space (e.g., king - man + woman = __?). In comparison, most attempts to solve visual analogies are still predominantly task-specific and less generalizable. This project focuses on visual analogical reasoning and applies the initial generalized mechanism used to solve verbal analogies to the visual realm. Taking the Abstraction and Reasoning Corpus (ARC) as an example to investigate visual analogy solving, we use a variational autoencoder (VAE) to transform ARC items into low-dimensional latent vectors, analogous to the word embeddings used in the verbal approaches. Through simple vector arithmetic, underlying rules of ARC items are discovered and used to solve them. Results indicate that the approach works well on simple items with fewer dimensions (i.e., few colors used, uniform shapes), similar input-to-output examples, and high reconstruction accuracy on the VAE. Predictions on more complex items showed stronger deviations from expected outputs, although, predictions still often approximated parts of the item's rule set. Error patterns indicated that the model works as intended. On the official ARC paradigm, the model achieved a score of 2% (cf. current world record is 21%) and on ConceptARC it scored 8.8%. Although the methodology proposed involves basic dimensionality reduction techniques and standard vector arithmetic, this approach demonstrates promising outcomes on ARC and can easily be generalized to other abstract visual reasoning tasks.