 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausality $ eq$ Invariance: Function and Concept Vectors in LLMs
Feb 25, 2026Do large language models (LLMs) represent concepts abstractly, i.e., independent of input format? We revisit Function Vectors (FVs), compact representations of in-context learning (ICL) tasks that causally drive task performance. Across multiple LLMs, we show that FVs are not fully invariant: FVs are nearly orthogonal when extracted from different input formats (e.g., open-ended vs. multiple-choice), even if both target the same concept. We identify Concept Vectors (CVs), which carry more stable concept representations. Like FVs, CVs are composed of attention head outputs; however, unlike FVs, the constituent heads are selected using Representational Similarity Analysis (RSA) based on whether they encode concepts consistently across input formats. While these heads emerge in similar layers to FV-related heads, the two sets are largely distinct, suggesting different underlying mechanisms. Steering experiments reveal that FVs excel in-distribution, when extraction and application formats match (e.g., both open-ended in English), while CVs generalize better out-of-distribution across both question types (open-ended vs. multiple-choice) and languages. Our results show that LLMs do contain abstract concept representations, but these differ from those that drive ICL performance.
Analogical Reasoning Inside Large Language Models: Concept Vectors and the Limits of Abstraction
Mar 05, 2025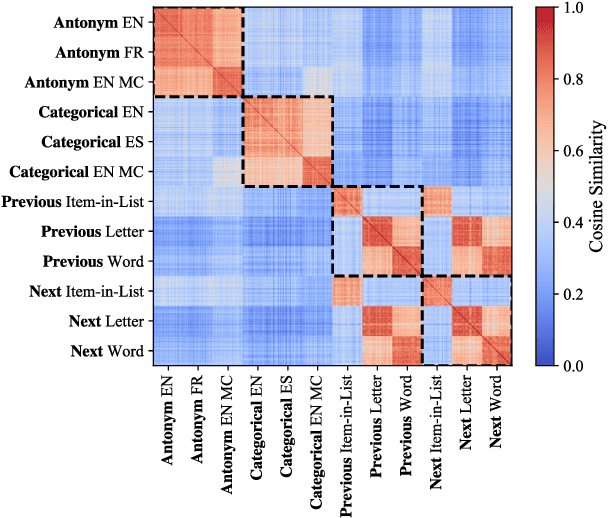
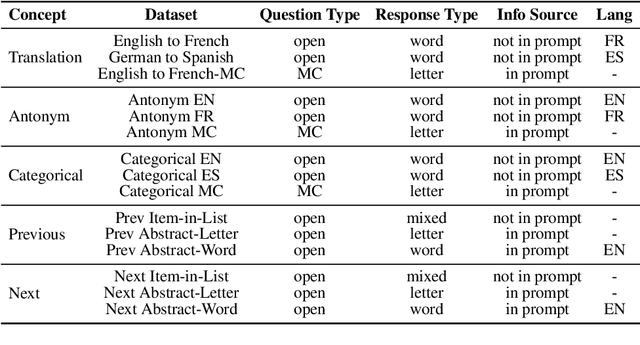
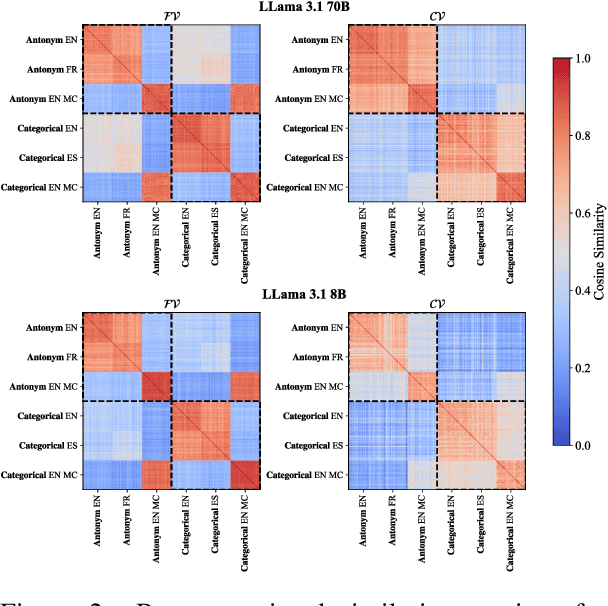

Analogical reasoning relies on conceptual abstractions, but it is unclear whether Large Language Models (LLMs) harbor such internal representations. We explore distilled representations from LLM activations and find that function vectors (FVs; Todd et al., 2024) - compact representations for in-context learning (ICL) tasks - are not invariant to simple input changes (e.g., open-ended vs. multiple-choice), suggesting they capture more than pure concepts. Using representational similarity analysis (RSA), we localize a small set of attention heads that encode invariant concept vectors (CVs) for verbal concepts like "antonym". These CVs function as feature detectors that operate independently of the final output - meaning that a model may form a correct internal representation yet still produce an incorrect output. Furthermore, CVs can be used to causally guide model behaviour. However, for more abstract concepts like "previous" and "next", we do not observe invariant linear representations, a finding we link to generalizability issues LLMs display within these domains.
Saliency Suppressed, Semantics Surfaced: Visual Transformations in Neural Networks and the Brain
Apr 29, 2024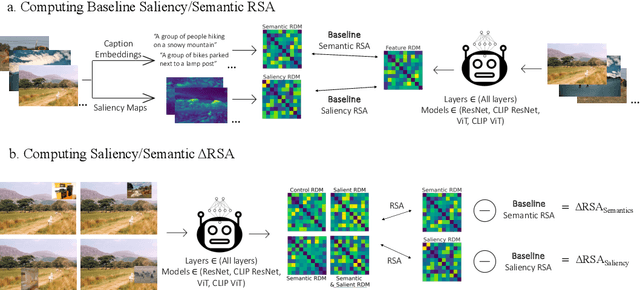
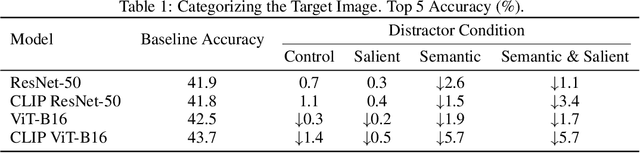
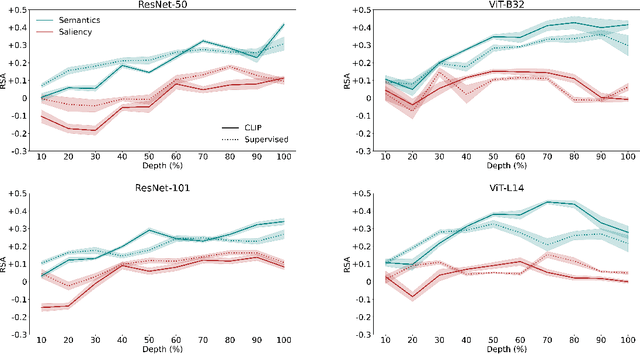
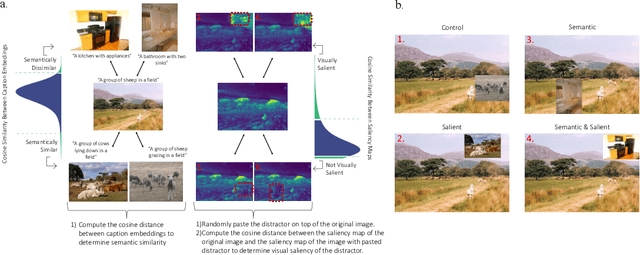
Deep learning algorithms lack human-interpretable accounts of how they transform raw visual input into a robust semantic understanding, which impedes comparisons between different architectures, training objectives, and the human brain. In this work, we take inspiration from neuroscience and employ representational approaches to shed light on how neural networks encode information at low (visual saliency) and high (semantic similarity) levels of abstraction. Moreover, we introduce a custom image dataset where we systematically manipulate salient and semantic information. We find that ResNets are more sensitive to saliency information than ViTs, when trained with object classification objectives. We uncover that networks suppress saliency in early layers, a process enhanced by natural language supervision (CLIP) in ResNets. CLIP also enhances semantic encoding in both architectures. Finally, we show that semantic encoding is a key factor in aligning AI with human visual perception, while saliency suppression is a non-brain-like strategy.
Do Large Language Models Solve ARC Visual Analogies Like People Do?
Mar 13, 2024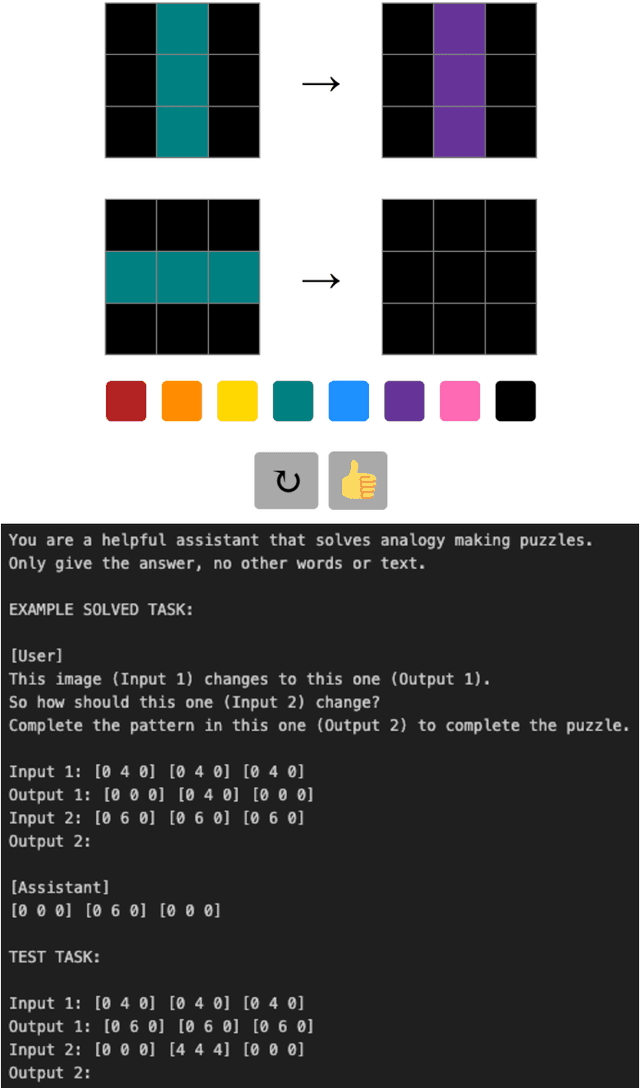

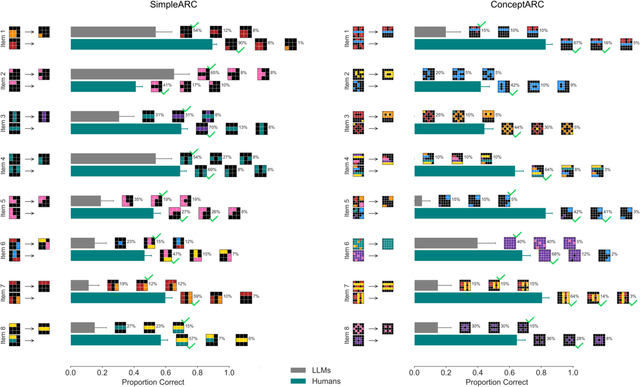
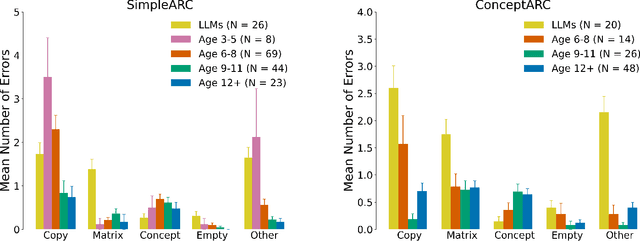
The Abstraction Reasoning Corpus (ARC) is a visual analogical reasoning test designed for humans and machines (Chollet, 2019). We compared human and large language model (LLM) performance on a new child-friendly set of ARC items. Results show that both children and adults outperform most LLMs on these tasks. Error analysis revealed a similar "fallback" solution strategy in LLMs and young children, where part of the analogy is simply copied. In addition, we found two other error types, one based on seemingly grasping key concepts (e.g., Inside-Outside) and the other based on simple combinations of analogy input matrices. On the whole, "concept" errors were more common in humans, and "matrix" errors were more common in LLMs. This study sheds new light on LLM reasoning ability and the extent to which we can use error analyses and comparisons with human development to understand how LLMs solve visual analogies.