 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocusing on Possible Named Entities in Active Named Entity Label Acquisition
Nov 06, 2021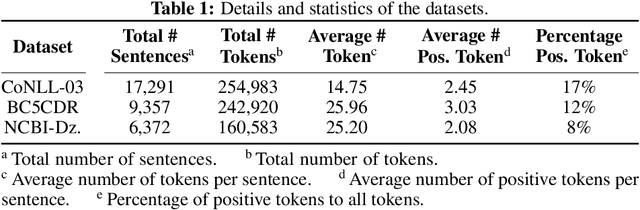
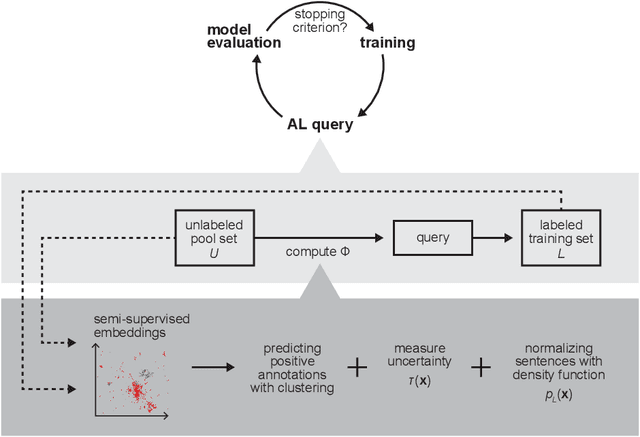
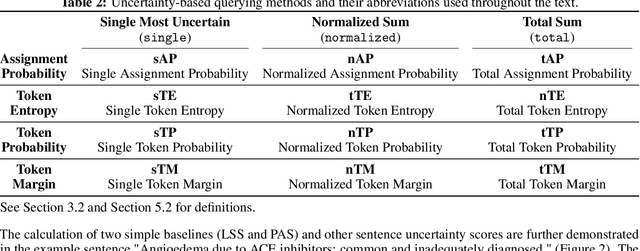
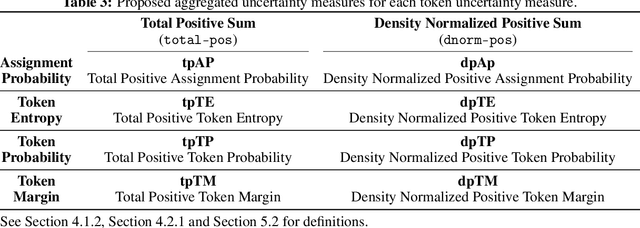
Named entity recognition (NER) aims to identify mentions of named entities in an unstructured text and classify them into the predefined named entity classes. Even though deep learning-based pre-trained language models achieve good predictive performances, many domain-specific NERtasks still require a sufficient amount of labeled data. Active learning (AL), a general framework for the label acquisition problem, has been used for the NER tasks to minimize the annotation cost without sacrificing model performance. However, heavily imbalanced class distribution of tokens introduces challenges in designing effective AL querying methods for NER. We propose AL sentence query evaluation functions which pay more attention to possible positive tokens, and evaluate these proposed functions with both sentence-based and token-based cost evaluation strategies. We also propose a better data-driven normalization approach to penalize too long or too short sentences. Our experiments on three datasets from different domains reveal that the proposed approaches reduce the number of annotated tokens while achieving better or comparable prediction performance with conventional methods.
Active Learning Methods based on Statistical Leverage Scores
Dec 06, 2018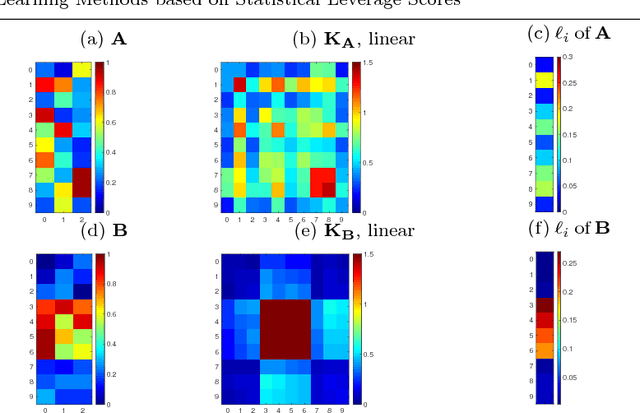
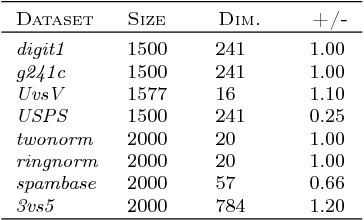
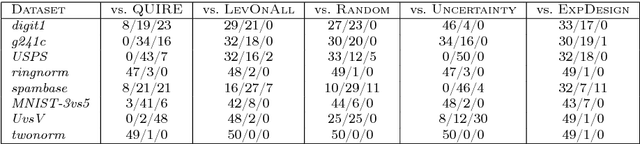
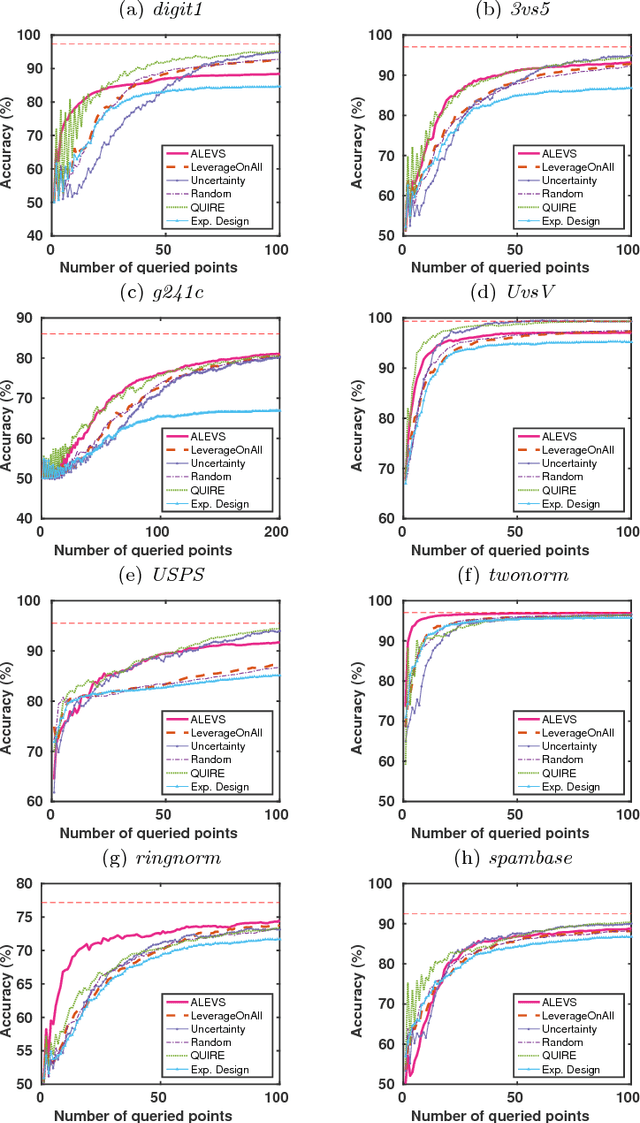
In many real-world machine learning applications, unlabeled data are abundant whereas class labels are expensive and scarce. An active learner aims to obtain a model of high accuracy with as few labeled instances as possible by effectively selecting useful examples for labeling. We propose a new selection criterion that is based on statistical leverage scores and present two novel active learning methods based on this criterion: ALEVS for querying single example at each iteration and DBALEVS for querying a batch of examples. To assess the representativeness of the examples in the pool, ALEVS and DBALEVS use the statistical leverage scores of the kernel matrices computed on the examples of each class. Additionally, DBALEVS selects a diverse a set of examples that are highly representative but are dissimilar to already labeled examples through maximizing a submodular set function defined with the statistical leverage scores and the kernel matrix computed on the pool of the examples. The submodularity property of the set scoring function let us identify batches with a constant factor approximate to the optimal batch in an efficient manner. Our experiments on diverse datasets show that querying based on leverage scores is a powerful strategy for active learning.