 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Learning Methods based on Statistical Leverage Scores
Dec 06, 2018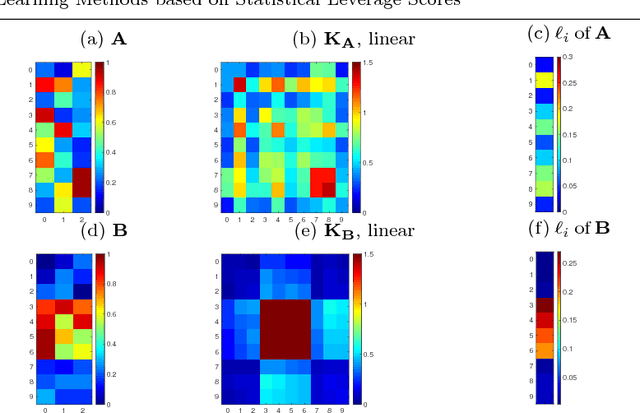
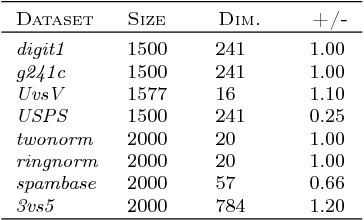
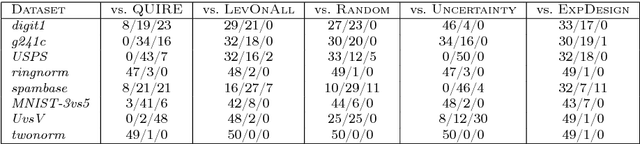
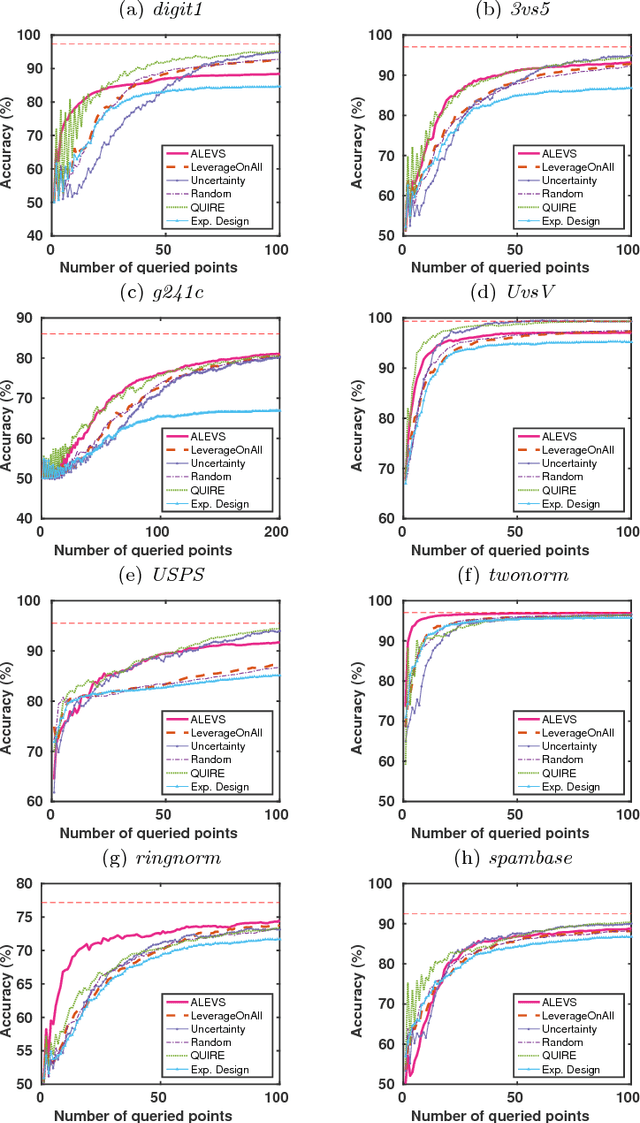
In many real-world machine learning applications, unlabeled data are abundant whereas class labels are expensive and scarce. An active learner aims to obtain a model of high accuracy with as few labeled instances as possible by effectively selecting useful examples for labeling. We propose a new selection criterion that is based on statistical leverage scores and present two novel active learning methods based on this criterion: ALEVS for querying single example at each iteration and DBALEVS for querying a batch of examples. To assess the representativeness of the examples in the pool, ALEVS and DBALEVS use the statistical leverage scores of the kernel matrices computed on the examples of each class. Additionally, DBALEVS selects a diverse a set of examples that are highly representative but are dissimilar to already labeled examples through maximizing a submodular set function defined with the statistical leverage scores and the kernel matrix computed on the pool of the examples. The submodularity property of the set scoring function let us identify batches with a constant factor approximate to the optimal batch in an efficient manner. Our experiments on diverse datasets show that querying based on leverage scores is a powerful strategy for active learning.
ALEVS: Active Learning by Statistical Leverage Sampling
Jul 15, 2015

Active learning aims to obtain a classifier of high accuracy by using fewer label requests in comparison to passive learning by selecting effective queries. Many active learning methods have been developed in the past two decades, which sample queries based on informativeness or representativeness of unlabeled data points. In this work, we explore a novel querying criterion based on statistical leverage scores. The statistical leverage scores of a row in a matrix are the squared row-norms of the matrix containing its (top) left singular vectors and is a measure of influence of the row on the matrix. Leverage scores have been used for detecting high influential points in regression diagnostics and have been recently shown to be useful for data analysis and randomized low-rank matrix approximation algorithms. We explore how sampling data instances with high statistical leverage scores perform in active learning. Our empirical comparison on several binary classification datasets indicate that querying high leverage points is an effective strategy.