 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocusing on Possible Named Entities in Active Named Entity Label Acquisition
Paper and Code
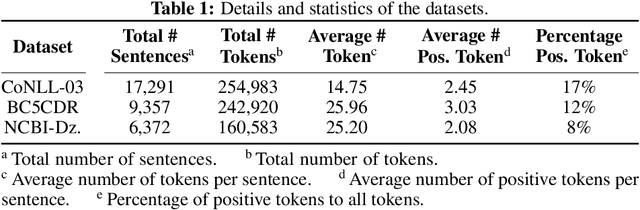
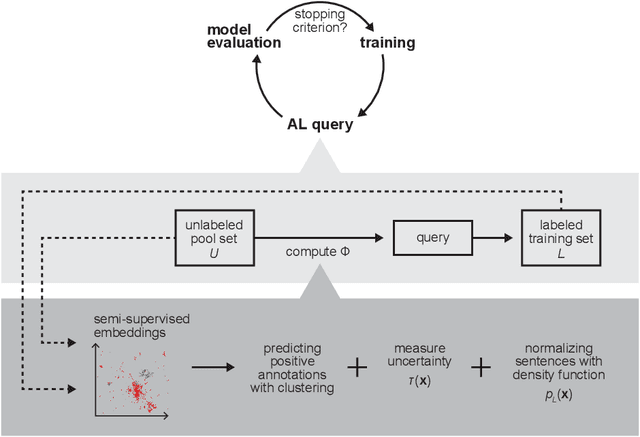
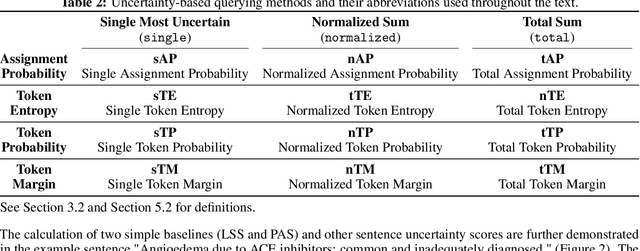
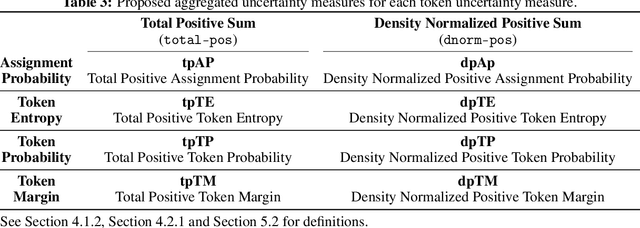
Named entity recognition (NER) aims to identify mentions of named entities in an unstructured text and classify them into the predefined named entity classes. Even though deep learning-based pre-trained language models achieve good predictive performances, many domain-specific NERtasks still require a sufficient amount of labeled data. Active learning (AL), a general framework for the label acquisition problem, has been used for the NER tasks to minimize the annotation cost without sacrificing model performance. However, heavily imbalanced class distribution of tokens introduces challenges in designing effective AL querying methods for NER. We propose AL sentence query evaluation functions which pay more attention to possible positive tokens, and evaluate these proposed functions with both sentence-based and token-based cost evaluation strategies. We also propose a better data-driven normalization approach to penalize too long or too short sentences. Our experiments on three datasets from different domains reveal that the proposed approaches reduce the number of annotated tokens while achieving better or comparable prediction performance with conventional methods.