 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Visual and Textual Features for Semantic Segmentation of Historical Newspapers
Feb 14, 2020
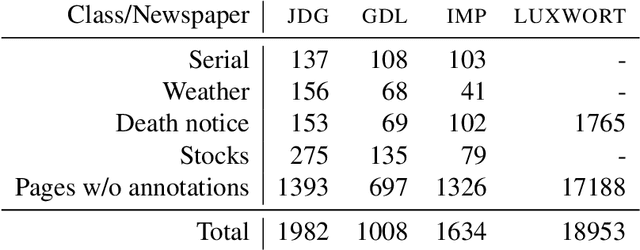
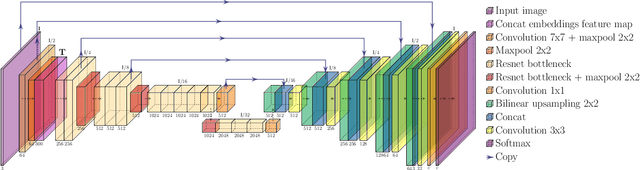
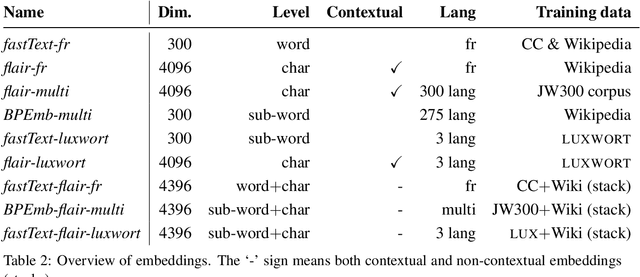
The massive amounts of digitized historical documents acquired over the last decades naturally lend themselves to automatic processing and exploration. Research work seeking to automatically process facsimiles and extract information thereby are multiplying with, as a first essential step, document layout analysis. If the identification and categorization of segments of interest in document images have seen significant progress over the last years thanks to deep learning techniques, many challenges remain with, among others, the use of finer-grained segmentation typologies and the consideration of complex, heterogeneous documents such as historical newspapers. Besides, most approaches consider visual features only, ignoring textual signal. In this context, we introduce a multimodal approach for the semantic segmentation of historical newspapers that combines visual and textual features. Based on a series of experiments on diachronic Swiss and Luxembourgish newspapers, we investigate, among others, the predictive power of visual and textual features and their capacity to generalize across time and sources. Results show consistent improvement of multimodal models in comparison to a strong visual baseline, as well as better robustness to high material variance.
dhSegment: A generic deep-learning approach for document segmentation
Apr 27, 2018



In recent years there have been multiple successful attempts tackling document processing problems separately by designing task specific hand-tuned strategies. We argue that the diversity of historical document processing tasks prohibits to solve them one at a time and shows a need for designing generic approaches in order to handle the variability of historical series. In this paper, we address multiple tasks simultaneously such as page extraction, baseline extraction, layout analysis or multiple typologies of illustrations and photograph extraction. We propose an open-source implementation of a CNN-based pixel-wise predictor coupled with task dependent post-processing blocks. We show that a single CNN-architecture can be used across tasks with competitive results. Moreover most of the task-specific post-precessing steps can be decomposed in a small number of simple and standard reusable operations, adding to the flexibility of our approach.