 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Music Cover Retrieval Using Lyrics-Aligned Audio Embeddings
Jan 16, 2026Music Cover Retrieval, also known as Version Identification, aims to recognize distinct renditions of the same underlying musical work, a task central to catalog management, copyright enforcement, and music retrieval. State-of-the-art approaches have largely focused on harmonic and melodic features, employing increasingly complex audio pipelines designed to be invariant to musical attributes that often vary widely across covers. While effective, these methods demand substantial training time and computational resources. By contrast, lyrics constitute a strong invariant across covers, though their use has been limited by the difficulty of extracting them accurately and efficiently from polyphonic audio. Early methods relied on simple frameworks that limited downstream performance, while more recent systems deliver stronger results but require large models integrated within complex multimodal architectures. We introduce LIVI (Lyrics-Informed Version Identification), an approach that seeks to balance retrieval accuracy with computational efficiency. First, LIVI leverages supervision from state-of-the-art transcription and text embedding models during training to achieve retrieval accuracy on par with--or superior to--harmonic-based systems. Second, LIVI remains lightweight and efficient by removing the transcription step at inference, challenging the dominance of complexity-heavy pipelines.
LLM-Powered Agents for Navigating Venice's Historical Cadastre
May 22, 2025Cadastral data reveal key information about the historical organization of cities but are often non-standardized due to diverse formats and human annotations, complicating large-scale analysis. We explore as a case study Venice's urban history during the critical period from 1740 to 1808, capturing the transition following the fall of the ancient Republic and the Ancien R\'egime. This era's complex cadastral data, marked by its volume and lack of uniform structure, presents unique challenges that our approach adeptly navigates, enabling us to generate spatial queries that bridge past and present urban landscapes. We present a text-to-programs framework that leverages Large Language Models (LLMs) to translate natural language queries into executable code for processing historical cadastral records. Our methodology implements two complementary techniques: a text-to-SQL approach for handling structured queries about specific cadastral information, and a text-to-Python approach for complex analytical operations requiring custom data manipulation. We propose a taxonomy that classifies historical research questions based on their complexity and analytical requirements, mapping them to the most appropriate technical approach. This framework is supported by an investigation into the execution consistency of the system, alongside a qualitative analysis of the answers it produces. By ensuring interpretability and minimizing hallucination through verifiable program outputs, we demonstrate the system's effectiveness in reconstructing past population information, property features, and spatiotemporal comparisons in Venice.
HAECcity: Open-Vocabulary Scene Understanding of City-Scale Point Clouds with Superpoint Graph Clustering
Apr 18, 2025Traditional 3D scene understanding techniques are generally predicated on hand-annotated label sets, but in recent years a new class of open-vocabulary 3D scene understanding techniques has emerged. Despite the success of this paradigm on small scenes, existing approaches cannot scale efficiently to city-scale 3D datasets. In this paper, we present Hierarchical vocab-Agnostic Expert Clustering (HAEC), after the latin word for 'these', a superpoint graph clustering based approach which utilizes a novel mixture of experts graph transformer for its backbone. We administer this highly scalable approach to the first application of open-vocabulary scene understanding on the SensatUrban city-scale dataset. We also demonstrate a synthetic labeling pipeline which is derived entirely from the raw point clouds with no hand-annotation. Our technique can help unlock complex operations on dense urban 3D scenes and open a new path forward in the processing of digital twins.
Is This Collection Worth My LLM's Time? Automatically Measuring Information Potential in Text Corpora
Feb 19, 2025As large language models (LLMs) converge towards similar capabilities, the key to advancing their performance lies in identifying and incorporating valuable new information sources. However, evaluating which text collections are worth the substantial investment required for digitization, preprocessing, and integration into LLM systems remains a significant challenge. We present a novel approach to this challenge: an automated pipeline that evaluates the potential information gain from text collections without requiring model training or fine-tuning. Our method generates multiple choice questions (MCQs) from texts and measures an LLM's performance both with and without access to the source material. The performance gap between these conditions serves as a proxy for the collection's information potential. We validate our approach using three strategically selected datasets: EPFL PhD manuscripts (likely containing novel specialized knowledge), Wikipedia articles (presumably part of training data), and a synthetic baseline dataset. Our results demonstrate that this method effectively identifies collections containing valuable novel information, providing a practical tool for prioritizing data acquisition and integration efforts.
Combining Visual and Textual Features for Semantic Segmentation of Historical Newspapers
Feb 14, 2020
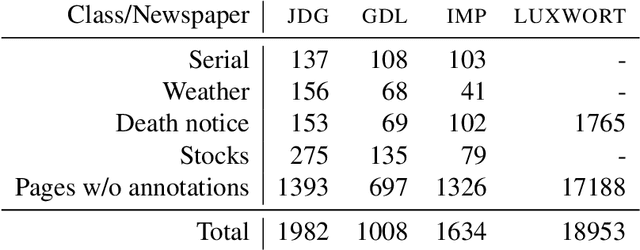
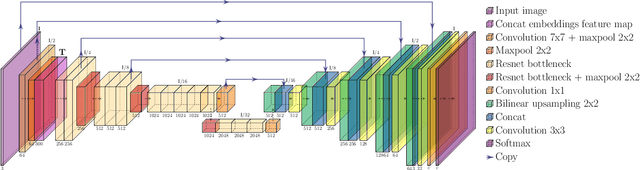
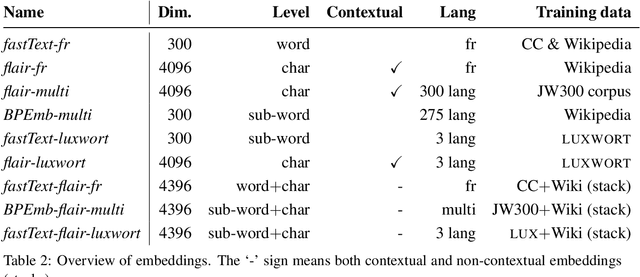
The massive amounts of digitized historical documents acquired over the last decades naturally lend themselves to automatic processing and exploration. Research work seeking to automatically process facsimiles and extract information thereby are multiplying with, as a first essential step, document layout analysis. If the identification and categorization of segments of interest in document images have seen significant progress over the last years thanks to deep learning techniques, many challenges remain with, among others, the use of finer-grained segmentation typologies and the consideration of complex, heterogeneous documents such as historical newspapers. Besides, most approaches consider visual features only, ignoring textual signal. In this context, we introduce a multimodal approach for the semantic segmentation of historical newspapers that combines visual and textual features. Based on a series of experiments on diachronic Swiss and Luxembourgish newspapers, we investigate, among others, the predictive power of visual and textual features and their capacity to generalize across time and sources. Results show consistent improvement of multimodal models in comparison to a strong visual baseline, as well as better robustness to high material variance.