 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Powered Agents for Navigating Venice's Historical Cadastre
May 22, 2025Cadastral data reveal key information about the historical organization of cities but are often non-standardized due to diverse formats and human annotations, complicating large-scale analysis. We explore as a case study Venice's urban history during the critical period from 1740 to 1808, capturing the transition following the fall of the ancient Republic and the Ancien R\'egime. This era's complex cadastral data, marked by its volume and lack of uniform structure, presents unique challenges that our approach adeptly navigates, enabling us to generate spatial queries that bridge past and present urban landscapes. We present a text-to-programs framework that leverages Large Language Models (LLMs) to translate natural language queries into executable code for processing historical cadastral records. Our methodology implements two complementary techniques: a text-to-SQL approach for handling structured queries about specific cadastral information, and a text-to-Python approach for complex analytical operations requiring custom data manipulation. We propose a taxonomy that classifies historical research questions based on their complexity and analytical requirements, mapping them to the most appropriate technical approach. This framework is supported by an investigation into the execution consistency of the system, alongside a qualitative analysis of the answers it produces. By ensuring interpretability and minimizing hallucination through verifiable program outputs, we demonstrate the system's effectiveness in reconstructing past population information, property features, and spatiotemporal comparisons in Venice.
Is This Collection Worth My LLM's Time? Automatically Measuring Information Potential in Text Corpora
Feb 19, 2025As large language models (LLMs) converge towards similar capabilities, the key to advancing their performance lies in identifying and incorporating valuable new information sources. However, evaluating which text collections are worth the substantial investment required for digitization, preprocessing, and integration into LLM systems remains a significant challenge. We present a novel approach to this challenge: an automated pipeline that evaluates the potential information gain from text collections without requiring model training or fine-tuning. Our method generates multiple choice questions (MCQs) from texts and measures an LLM's performance both with and without access to the source material. The performance gap between these conditions serves as a proxy for the collection's information potential. We validate our approach using three strategically selected datasets: EPFL PhD manuscripts (likely containing novel specialized knowledge), Wikipedia articles (presumably part of training data), and a synthetic baseline dataset. Our results demonstrate that this method effectively identifies collections containing valuable novel information, providing a practical tool for prioritizing data acquisition and integration efforts.
Vygotskian Autotelic Artificial Intelligence: Language and Culture Internalization for Human-Like AI
Jun 02, 2022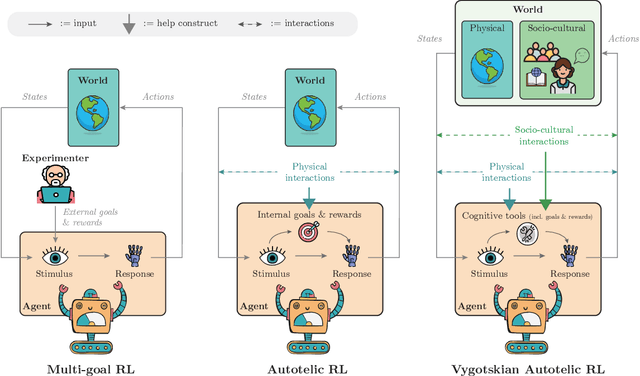
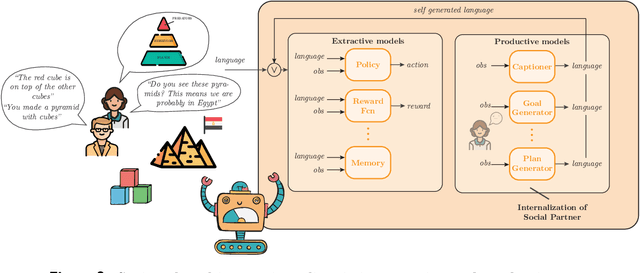
Building autonomous artificial agents able to grow open-ended repertoires of skills is one of the fundamental goals of AI. To that end, a promising developmental approach recommends the design of intrinsically motivated agents that learn new skills by generating and pursuing their own goals - autotelic agents. However, existing algorithms still show serious limitations in terms of goal diversity, exploration, generalization or skill composition. This perspective calls for the immersion of autotelic agents into rich socio-cultural worlds. We focus on language especially, and how its structure and content may support the development of new cognitive functions in artificial agents, just like it does in humans. Indeed, most of our skills could not be learned in isolation. Formal education teaches us to reason systematically, books teach us history, and YouTube might teach us how to cook. Crucially, our values, traditions, norms and most of our goals are cultural in essence. This knowledge, and some argue, some of our cognitive functions such as abstraction, compositional imagination or relational thinking, are formed through linguistic and cultural interactions. Inspired by the work of Vygotsky, we suggest the design of Vygotskian autotelic agents able to interact with others and, more importantly, able to internalize these interactions to transform them into cognitive tools supporting the development of new cognitive functions. This perspective paper proposes a new AI paradigm in the quest for artificial lifelong skill discovery. It justifies the approach by uncovering examples of new artificial cognitive functions emerging from interactions between language and embodiment in recent works at the intersection of deep reinforcement learning and natural language processing. Looking forward, it highlights future opportunities and challenges for Vygotskian Autotelic AI research.
Learning to Guide and to Be Guided in the Architect-Builder Problem
Dec 19, 2021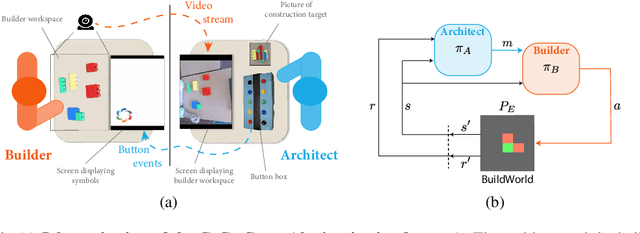
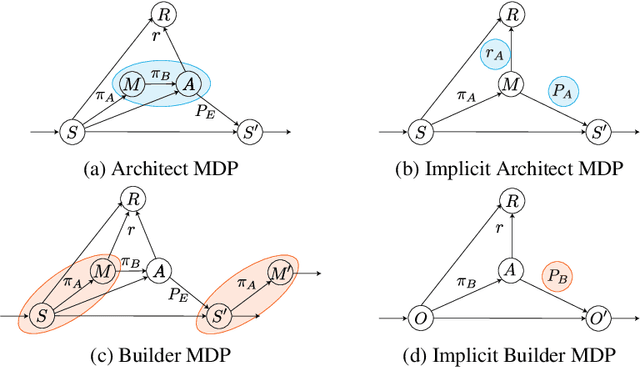
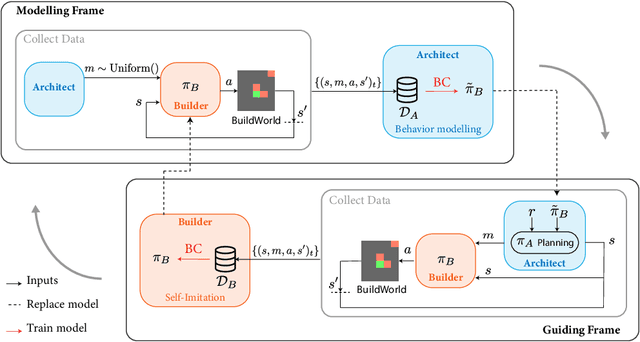
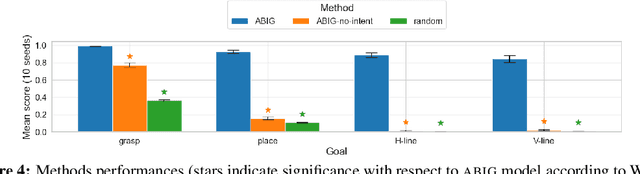
We are interested in interactive agents that learn to coordinate, namely, a $builder$ -- which performs actions but ignores the goal of the task -- and an $architect$ which guides the builder towards the goal of the task. We define and explore a formal setting where artificial agents are equipped with mechanisms that allow them to simultaneously learn a task while at the same time evolving a shared communication protocol. The field of Experimental Semiotics has shown the extent of human proficiency at learning from a priori unknown instructions meanings. Therefore, we take inspiration from it and present the Architect-Builder Problem (ABP): an asymmetrical setting in which an architect must learn to guide a builder towards constructing a specific structure. The architect knows the target structure but cannot act in the environment and can only send arbitrary messages to the builder. The builder on the other hand can act in the environment but has no knowledge about the task at hand and must learn to solve it relying only on the messages sent by the architect. Crucially, the meaning of messages is initially not defined nor shared between the agents but must be negotiated throughout learning. Under these constraints, we propose Architect-Builder Iterated Guiding (ABIG), a solution to the Architect-Builder Problem where the architect leverages a learned model of the builder to guide it while the builder uses self-imitation learning to reinforce its guided behavior. We analyze the key learning mechanisms of ABIG and test it in a 2-dimensional instantiation of the ABP where tasks involve grasping cubes, placing them at a given location, or building various shapes. In this environment, ABIG results in a low-level, high-frequency, guiding communication protocol that not only enables an architect-builder pair to solve the task at hand, but that can also generalize to unseen tasks.
Grounding Spatio-Temporal Language with Transformers
Jun 16, 2021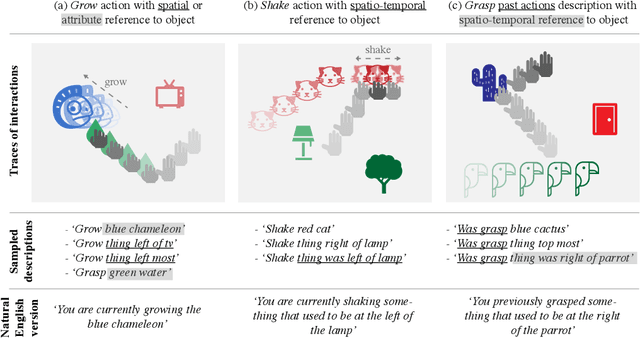
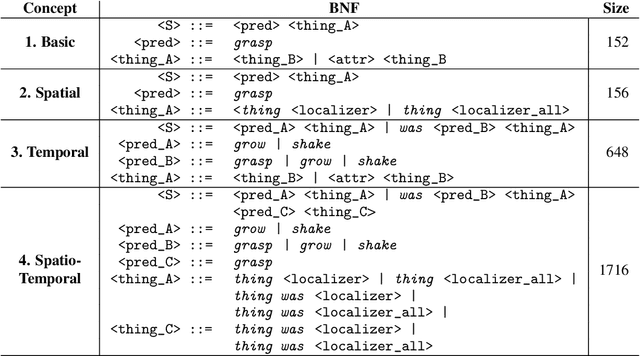
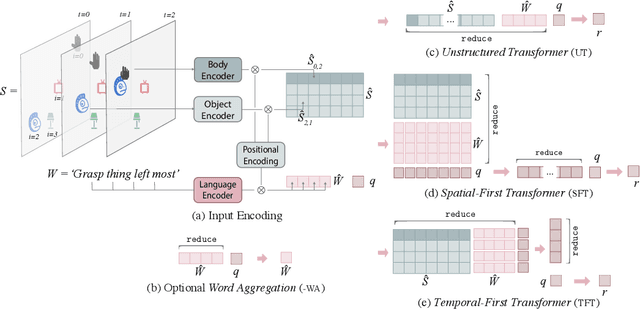
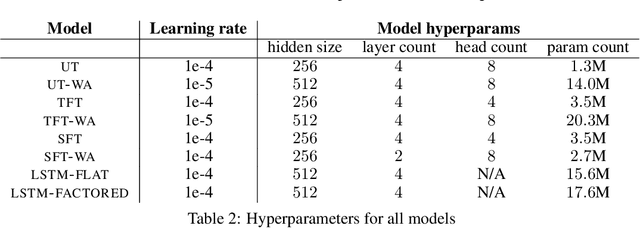
Language is an interface to the outside world. In order for embodied agents to use it, language must be grounded in other, sensorimotor modalities. While there is an extended literature studying how machines can learn grounded language, the topic of how to learn spatio-temporal linguistic concepts is still largely uncharted. To make progress in this direction, we here introduce a novel spatio-temporal language grounding task where the goal is to learn the meaning of spatio-temporal descriptions of behavioral traces of an embodied agent. This is achieved by training a truth function that predicts if a description matches a given history of observations. The descriptions involve time-extended predicates in past and present tense as well as spatio-temporal references to objects in the scene. To study the role of architectural biases in this task, we train several models including multimodal Transformer architectures; the latter implement different attention computations between words and objects across space and time. We test models on two classes of generalization: 1) generalization to randomly held-out sentences; 2) generalization to grammar primitives. We observe that maintaining object identity in the attention computation of our Transformers is instrumental to achieving good performance on generalization overall, and that summarizing object traces in a single token has little influence on performance. We then discuss how this opens new perspectives for language-guided autonomous embodied agents. We also release our code under open-source license as well as pretrained models and datasets to encourage the wider community to build upon and extend our work in the future.
Intrinsically Motivated Goal-Conditioned Reinforcement Learning: a Short Survey
Dec 17, 2020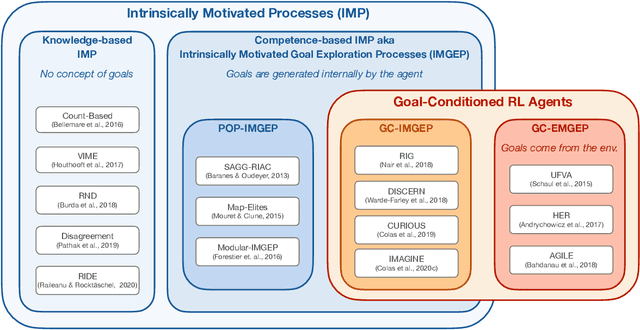
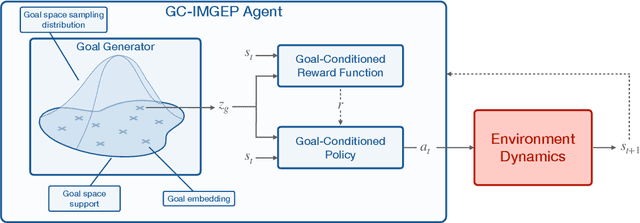
Building autonomous machines that can explore open-ended environments, discover possible interactions and autonomously build repertoires of skills is a general objective of artificial intelligence. Developmental approaches argue that this can only be achieved by autonomous and intrinsically motivated learning agents that can generate, select and learn to solve their own problems. In recent years, we have seen a convergence of developmental approaches, and developmental robotics in particular, with deep reinforcement learning (RL) methods, forming the new domain of developmental machine learning. Within this new domain, we review here a set of methods where deep RL algorithms are trained to tackle the developmental robotics problem of the autonomous acquisition of open-ended repertoires of skills. Intrinsically motivated goal-conditioned RL algorithms train agents to learn to represent, generate and pursue their own goals. The self-generation of goals requires the learning of compact goal encodings as well as their associated goal-achievement functions, which results in new challenges compared to traditional RL algorithms designed to tackle pre-defined sets of goals using external reward signals. This paper proposes a typology of these methods at the intersection of deep RL and developmental approaches, surveys recent approaches and discusses future avenues.
Deep Sets for Generalization in RL
Mar 20, 2020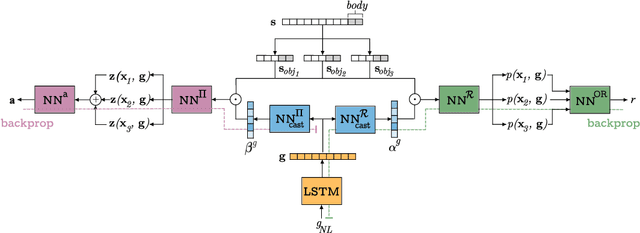
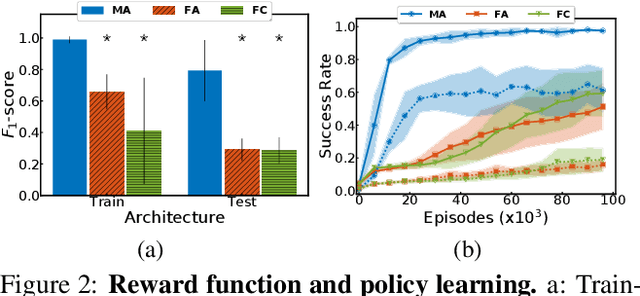
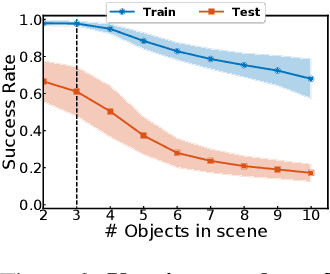
This paper investigates the idea of encoding object-centered representations in the design of the reward function and policy architectures of a language-guided reinforcement learning agent. This is done using a combination of object-wise permutation invariant networks inspired from Deep Sets and gated-attention mechanisms. In a 2D procedurally-generated world where agents targeting goals in natural language navigate and interact with objects, we show that these architectures demonstrate strong generalization capacities to out-of-distribution goals. We study the generalization to varying numbers of objects at test time and further extend the object-centered architectures to goals involving relational reasoning.
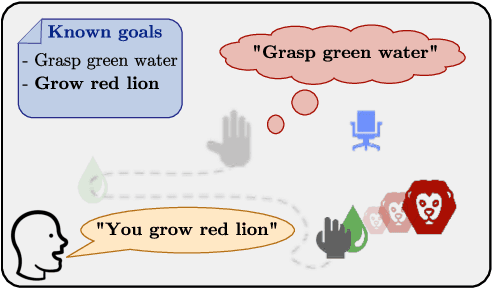
Language as a Cognitive Tool to Imagine Goals in Curiosity-Driven Exploration
Feb 21, 2020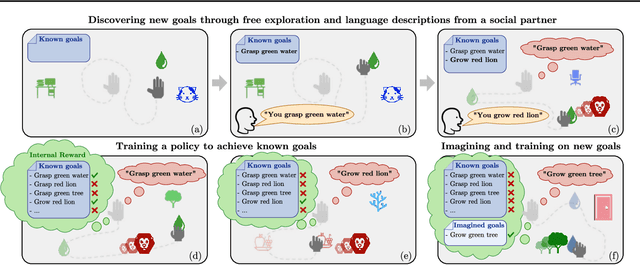
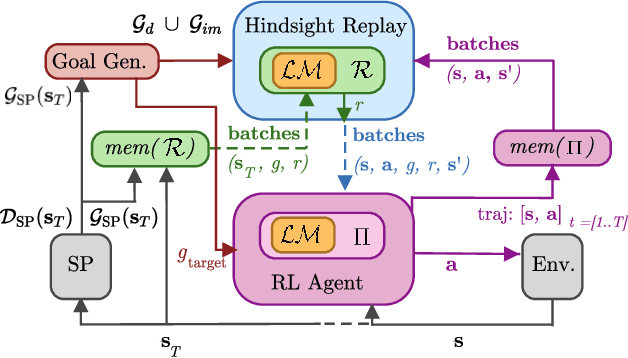
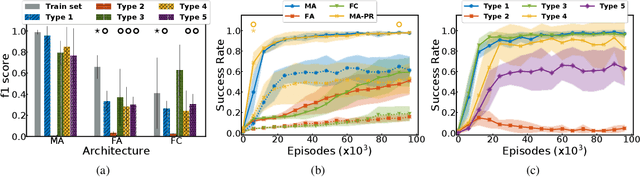
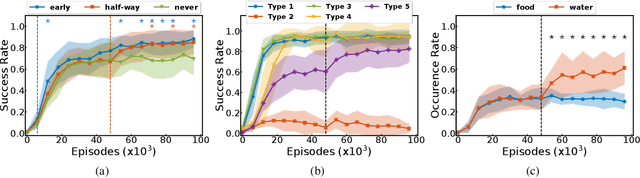
Autonomous reinforcement learning agents must be intrinsically motivated to explore their environment, discover potential goals, represent them and learn how to achieve them. As children do the same, they benefit from exposure to language, using it to formulate goals and imagine new ones as they learn their meaning. In our proposed learning architecture (IMAGINE), the agent freely explores its environment and turns natural language descriptions of interesting interactions from a social partner into potential goals. IMAGINE learns to represent goals by jointly learning a language model and a goal-conditioned reward function. Just like humans, our agent uses language compositionality to generate new goals by composing known ones. Leveraging modular model architectures based on Deep Sets and gated-attention mechanisms, IMAGINE autonomously builds a repertoire of behaviors and shows good zero-shot generalization properties for various types of generalization. When imagining its own goals, the agent leverages zero-shot generalization of the reward function to further train on imagined goals and refine its behavior. We present experiments in a simulated domain where the agent interacts with procedurally generated scenes containing objects of various types and colors, discovers goals, imagines others and learns to achieve them.