 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage as a Cognitive Tool to Imagine Goals in Curiosity-Driven Exploration
Feb 21, 2020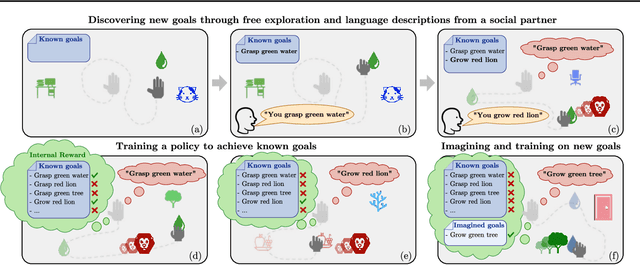
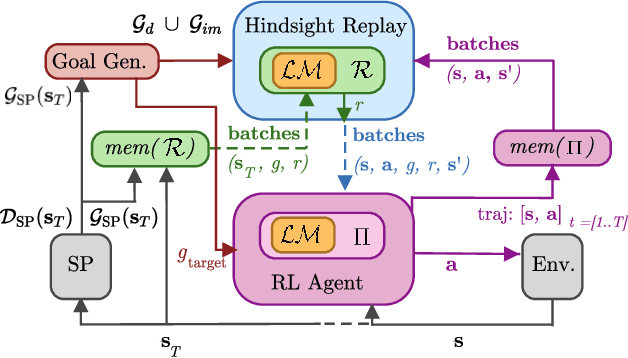
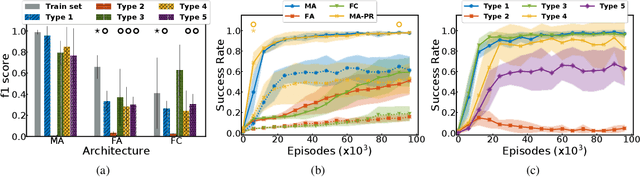
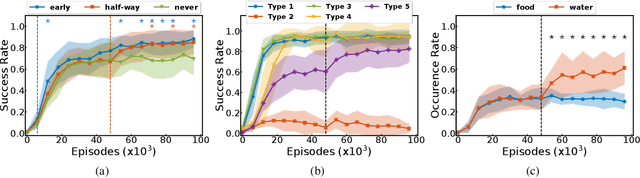
Autonomous reinforcement learning agents must be intrinsically motivated to explore their environment, discover potential goals, represent them and learn how to achieve them. As children do the same, they benefit from exposure to language, using it to formulate goals and imagine new ones as they learn their meaning. In our proposed learning architecture (IMAGINE), the agent freely explores its environment and turns natural language descriptions of interesting interactions from a social partner into potential goals. IMAGINE learns to represent goals by jointly learning a language model and a goal-conditioned reward function. Just like humans, our agent uses language compositionality to generate new goals by composing known ones. Leveraging modular model architectures based on Deep Sets and gated-attention mechanisms, IMAGINE autonomously builds a repertoire of behaviors and shows good zero-shot generalization properties for various types of generalization. When imagining its own goals, the agent leverages zero-shot generalization of the reward function to further train on imagined goals and refine its behavior. We present experiments in a simulated domain where the agent interacts with procedurally generated scenes containing objects of various types and colors, discovers goals, imagines others and learns to achieve them.
User-in-the-loop Adaptive Intent Detection for Instructable Digital Assistant
Jan 16, 2020

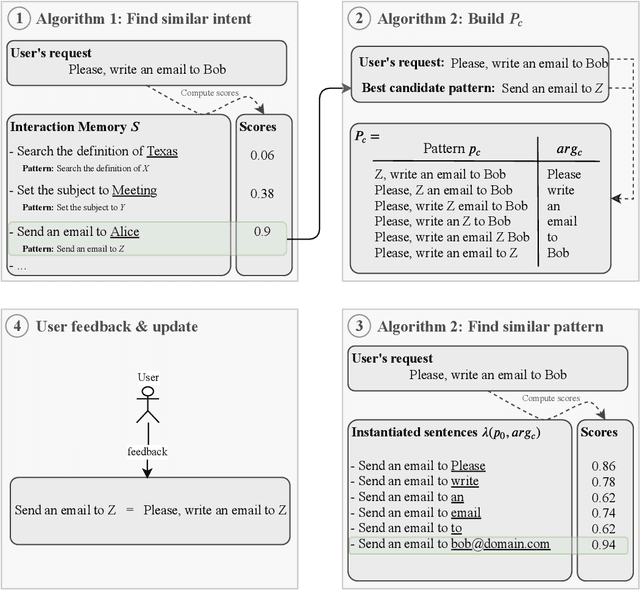

People are becoming increasingly comfortable using Digital Assistants (DAs) to interact with services or connected objects. However, for non-programming users, the available possibilities for customizing their DA are limited and do not include the possibility of teaching the assistant new tasks. To make the most of the potential of DAs, users should be able to customize assistants by instructing them through Natural Language (NL). To provide such functionalities, NL interpretation in traditional assistants should be improved: (1) The intent identification system should be able to recognize new forms of known intents, and to acquire new intents as they are expressed by the user. (2) In order to be adaptive to novel intents, the Natural Language Understanding module should be sample efficient, and should not rely on a pretrained model. Rather, the system should continuously collect the training data as it learns new intents from the user. In this work, we propose AidMe (Adaptive Intent Detection in Multi-Domain Environments), a user-in-the-loop adaptive intent detection framework that allows the assistant to adapt to its user by learning his intents as their interaction progresses. AidMe builds its repertoire of intents and collects data to train a model of semantic similarity evaluation that can discriminate between the learned intents and autonomously discover new forms of known intents. AidMe addresses two major issues - intent learning and user adaptation - for instructable digital assistants. We demonstrate the capabilities of AidMe as a standalone system by comparing it with a one-shot learning system and a pretrained NLU module through simulations of interactions with a user. We also show how AidMe can smoothly integrate to an existing instructable digital assistant.
* To be published as a conference paper in the proceedings of IUI'20
Language Grounding through Social Interactions and Curiosity-Driven Multi-Goal Learning
Nov 08, 2019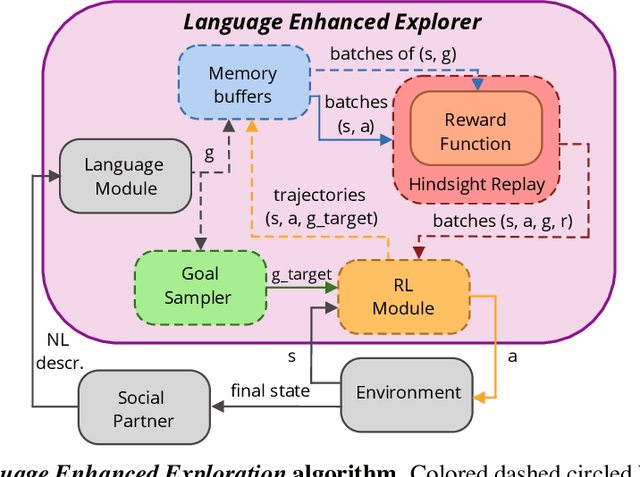
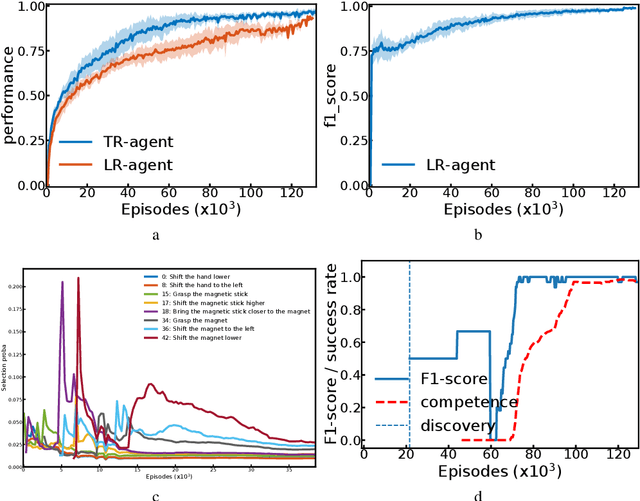
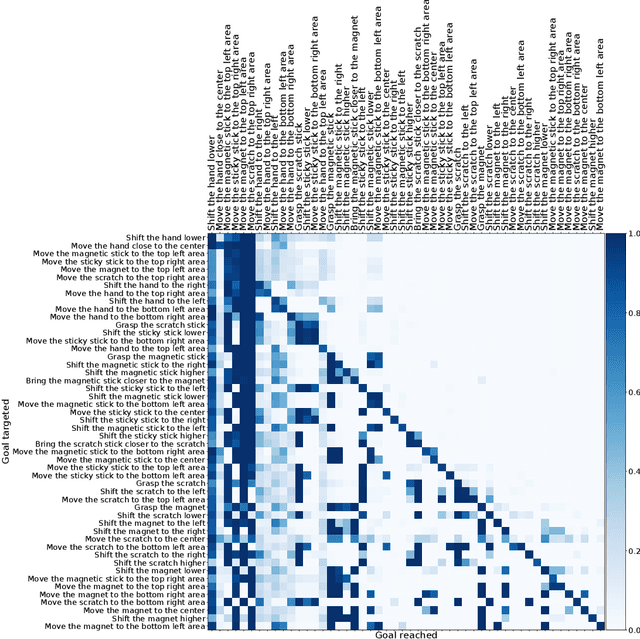
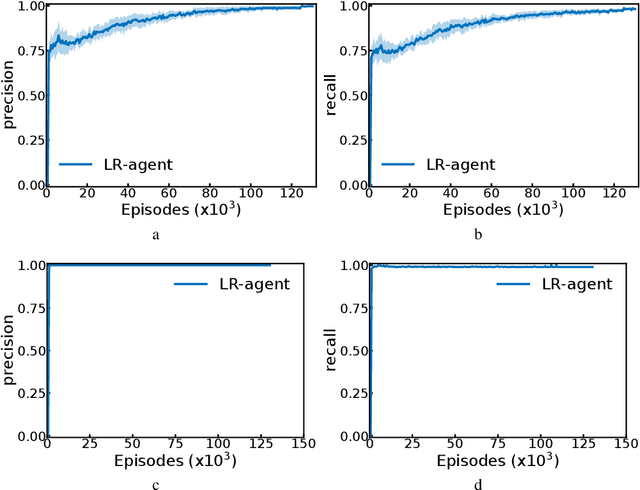
Autonomous reinforcement learning agents, like children, do not have access to predefined goals and reward functions. They must discover potential goals, learn their own reward functions and engage in their own learning trajectory. Children, however, benefit from exposure to language, helping to organize and mediate their thought. We propose LE2 (Language Enhanced Exploration), a learning algorithm leveraging intrinsic motivations and natural language (NL) interactions with a descriptive social partner (SP). Using NL descriptions from the SP, it can learn an NL-conditioned reward function to formulate goals for intrinsically motivated goal exploration and learn a goal-conditioned policy. By exploring, collecting descriptions from the SP and jointly learning the reward function and the policy, the agent grounds NL descriptions into real behavioral goals. From simple goals discovered early to more complex goals discovered by experimenting on simpler ones, our agent autonomously builds its own behavioral repertoire. This naturally occurring curriculum is supplemented by an active learning curriculum resulting from the agent's intrinsic motivations. Experiments are presented with a simulated robotic arm that interacts with several objects including tools.