 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline Reinforcement Learning of High-Quality Behaviors Under Robust Style Alignment
Jan 30, 2026We study offline reinforcement learning of style-conditioned policies using explicit style supervision via subtrajectory labeling functions. In this setting, aligning style with high task performance is particularly challenging due to distribution shift and inherent conflicts between style and reward. Existing methods, despite introducing numerous definitions of style, often fail to reconcile these objectives effectively. To address these challenges, we propose a unified definition of behavior style and instantiate it into a practical framework. Building on this, we introduce Style-Conditioned Implicit Q-Learning (SCIQL), which leverages offline goal-conditioned RL techniques, such as hindsight relabeling and value learning, and combine it with a new Gated Advantage Weighted Regression mechanism to efficiently optimize task performance while preserving style alignment. Experiments demonstrate that SCIQL achieves superior performance on both objectives compared to prior offline methods. Code, datasets and visuals are available in: https://sciql-iclr-2026.github.io/.
Offline Learning of Controllable Diverse Behaviors
Apr 25, 2025Imitation Learning (IL) techniques aim to replicate human behaviors in specific tasks. While IL has gained prominence due to its effectiveness and efficiency, traditional methods often focus on datasets collected from experts to produce a single efficient policy. Recently, extensions have been proposed to handle datasets of diverse behaviors by mainly focusing on learning transition-level diverse policies or on performing entropy maximization at the trajectory level. While these methods may lead to diverse behaviors, they may not be sufficient to reproduce the actual diversity of demonstrations or to allow controlled trajectory generation. To overcome these drawbacks, we propose a different method based on two key features: a) Temporal Consistency that ensures consistent behaviors across entire episodes and not just at the transition level as well as b) Controllability obtained by constructing a latent space of behaviors that allows users to selectively activate specific behaviors based on their requirements. We compare our approach to state-of-the-art methods over a diverse set of tasks and environments. Project page: https://mathieu-petitbois.github.io/projects/swr/
Recursive Training Loops in LLMs: How training data properties modulate distribution shift in generated data?
Apr 08, 2025Large language models (LLMs) are increasingly contributing to the creation of content on the Internet. This creates a feedback loop as subsequent generations of models will be trained on this generated, synthetic data. This phenomenon is receiving increasing interest, in particular because previous studies have shown that it may lead to distribution shift - models misrepresent and forget the true underlying distributions of human data they are expected to approximate (e.g. resulting in a drastic loss of quality). In this study, we study the impact of human data properties on distribution shift dynamics in iterated training loops. We first confirm that the distribution shift dynamics greatly vary depending on the human data by comparing four datasets (two based on Twitter and two on Reddit). We then test whether data quality may influence the rate of this shift. We find that it does on the twitter, but not on the Reddit datasets. We then focus on a Reddit dataset and conduct a more exhaustive evaluation of a large set of dataset properties. This experiment associated lexical diversity with larger, and semantic diversity with smaller detrimental shifts, suggesting that incorporating text with high lexical (but limited semantic) diversity could exacerbate the degradation of generated text. We then focus on the evolution of political bias, and find that the type of shift observed (bias reduction, amplification or inversion) depends on the political lean of the human (true) distribution. Overall, our work extends the existing literature on the consequences of recursive fine-tuning by showing that this phenomenon is highly dependent on features of the human data on which training occurs. This suggests that different parts of internet (e.g. GitHub, Reddit) may undergo different types of shift depending on their properties.
Hierarchical Subspaces of Policies for Continual Offline Reinforcement Learning
Dec 19, 2024



In dynamic domains such as autonomous robotics and video game simulations, agents must continuously adapt to new tasks while retaining previously acquired skills. This ongoing process, known as Continual Reinforcement Learning, presents significant challenges, including the risk of forgetting past knowledge and the need for scalable solutions as the number of tasks increases. To address these issues, we introduce HIerarchical LOW-rank Subspaces of Policies (HILOW), a novel framework designed for continual learning in offline navigation settings. HILOW leverages hierarchical policy subspaces to enable flexible and efficient adaptation to new tasks while preserving existing knowledge. We demonstrate, through a careful experimental study, the effectiveness of our method in both classical MuJoCo maze environments and complex video game-like simulations, showcasing competitive performance and satisfying adaptability according to classical continual learning metrics, in particular regarding memory usage. Our work provides a promising framework for real-world applications where continuous learning from pre-collected data is essential.
Navigation with QPHIL: Quantizing Planner for Hierarchical Implicit Q-Learning
Nov 12, 2024



Offline Reinforcement Learning (RL) has emerged as a powerful alternative to imitation learning for behavior modeling in various domains, particularly in complex navigation tasks. An existing challenge with Offline RL is the signal-to-noise ratio, i.e. how to mitigate incorrect policy updates due to errors in value estimates. Towards this, multiple works have demonstrated the advantage of hierarchical offline RL methods, which decouples high-level path planning from low-level path following. In this work, we present a novel hierarchical transformer-based approach leveraging a learned quantizer of the space. This quantization enables the training of a simpler zone-conditioned low-level policy and simplifies planning, which is reduced to discrete autoregressive prediction. Among other benefits, zone-level reasoning in planning enables explicit trajectory stitching rather than implicit stitching based on noisy value function estimates. By combining this transformer-based planner with recent advancements in offline RL, our proposed approach achieves state-of-the-art results in complex long-distance navigation environments.
Efficient Active Imitation Learning with Random Network Distillation
Nov 04, 2024



Developing agents for complex and underspecified tasks, where no clear objective exists, remains challenging but offers many opportunities. This is especially true in video games, where simulated players (bots) need to play realistically, and there is no clear reward to evaluate them. While imitation learning has shown promise in such domains, these methods often fail when agents encounter out-of-distribution scenarios during deployment. Expanding the training dataset is a common solution, but it becomes impractical or costly when relying on human demonstrations. This article addresses active imitation learning, aiming to trigger expert intervention only when necessary, reducing the need for constant expert input along training. We introduce Random Network Distillation DAgger (RND-DAgger), a new active imitation learning method that limits expert querying by using a learned state-based out-of-distribution measure to trigger interventions. This approach avoids frequent expert-agent action comparisons, thus making the expert intervene only when it is useful. We evaluate RND-DAgger against traditional imitation learning and other active approaches in 3D video games (racing and third-person navigation) and in a robotic locomotion task and show that RND-DAgger surpasses previous methods by reducing expert queries. https://sites.google.com/view/rnd-dagger
Stick to your Role! Stability of Personal Values Expressed in Large Language Models
Feb 19, 2024The standard way to study Large Language Models (LLMs) through benchmarks or psychology questionnaires is to provide many different queries from similar minimal contexts (e.g. multiple choice questions). However, due to LLM's highly context-dependent nature, conclusions from such minimal-context evaluations may be little informative about the model's behavior in deployment (where it will be exposed to many new contexts). We argue that context-dependence should be studied as another dimension of LLM comparison alongside others such as cognitive abilities, knowledge, or model size. In this paper, we present a case-study about the stability of value expression over different contexts (simulated conversations on different topics), and as measured using a standard psychology questionnaire (PVQ) and a behavioral downstream task. We consider 19 open-sourced LLMs from five families. Reusing methods from psychology, we study Rank-order stability on the population (interpersonal) level, and Ipsative stability on the individual (intrapersonal) level. We explore two settings: with and without instructing LLMs to simulate particular personalities. We observe similar trends in the stability of models and model families - Mixtral, Mistral and Qwen families being more stable than LLaMa-2 and Phi - over those two settings, two different simulated populations, and even in the downstream behavioral task. When instructed to simulate particular personas, LLMs exhibit low Rank-Order stability, and this stability further diminishes with conversation length. This highlights the need for future research directions on LLMs that can coherently simulate a diversity of personas, as well as how context-dependence can be studied in more thorough and efficient ways. This paper provides a foundational step in that direction, and, to our knowledge, it is the first study of value stability in LLMs.
The SocialAI School: Insights from Developmental Psychology Towards Artificial Socio-Cultural Agents
Jul 15, 2023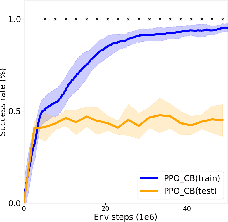

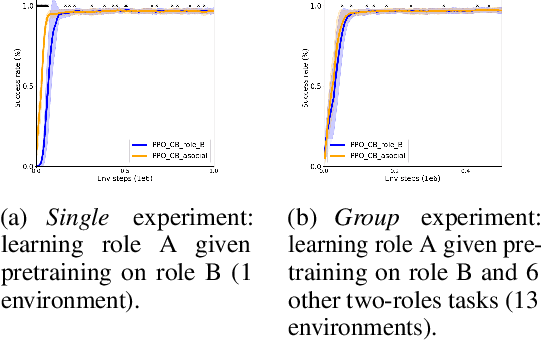

Developmental psychologists have long-established the importance of socio-cognitive abilities in human intelligence. These abilities enable us to enter, participate and benefit from human culture. AI research on social interactive agents mostly concerns the emergence of culture in a multi-agent setting (often without a strong grounding in developmental psychology). We argue that AI research should be informed by psychology and study socio-cognitive abilities enabling to enter a culture too. We discuss the theories of Michael Tomasello and Jerome Bruner to introduce some of their concepts to AI and outline key concepts and socio-cognitive abilities. We present The SocialAI school - a tool including a customizable parameterized uite of procedurally generated environments, which simplifies conducting experiments regarding those concepts. We show examples of such experiments with RL agents and Large Language Models. The main motivation of this work is to engage the AI community around the problem of social intelligence informed by developmental psychology, and to provide a tool to simplify first steps in this direction. Refer to the project website for code and additional information: https://sites.google.com/view/socialai-school.
Large Language Models as Superpositions of Cultural Perspectives
Jul 15, 2023



Large Language Models (LLMs) are often misleadingly recognized as having a personality or a set of values. We argue that an LLM can be seen as a superposition of perspectives with different values and personality traits. LLMs exhibit context-dependent values and personality traits that change based on the induced perspective (as opposed to humans, who tend to have more coherent values and personality traits across contexts). We introduce the concept of perspective controllability, which refers to a model's affordance to adopt various perspectives with differing values and personality traits. In our experiments, we use questionnaires from psychology (PVQ, VSM, IPIP) to study how exhibited values and personality traits change based on different perspectives. Through qualitative experiments, we show that LLMs express different values when those are (implicitly or explicitly) implied in the prompt, and that LLMs express different values even when those are not obviously implied (demonstrating their context-dependent nature). We then conduct quantitative experiments to study the controllability of different models (GPT-4, GPT-3.5, OpenAssistant, StableVicuna, StableLM), the effectiveness of various methods for inducing perspectives, and the smoothness of the models' drivability. We conclude by examining the broader implications of our work and outline a variety of associated scientific questions. The project website is available at https://sites.google.com/view/llm-superpositions .
SocialAI: Benchmarking Socio-Cognitive Abilities in Deep Reinforcement Learning Agents
Jul 06, 2021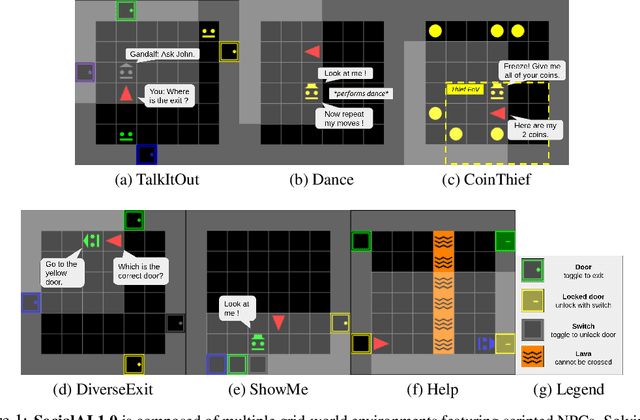

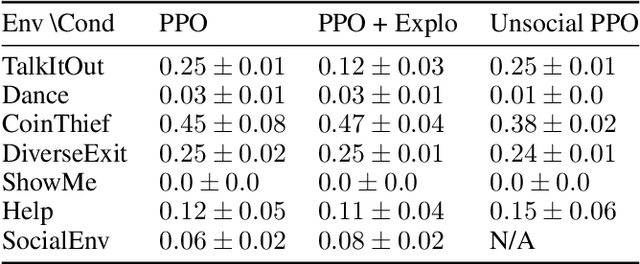
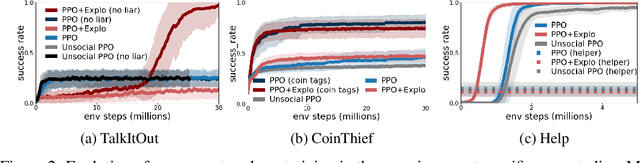
Building embodied autonomous agents capable of participating in social interactions with humans is one of the main challenges in AI. Within the Deep Reinforcement Learning (DRL) field, this objective motivated multiple works on embodied language use. However, current approaches focus on language as a communication tool in very simplified and non-diverse social situations: the "naturalness" of language is reduced to the concept of high vocabulary size and variability. In this paper, we argue that aiming towards human-level AI requires a broader set of key social skills: 1) language use in complex and variable social contexts; 2) beyond language, complex embodied communication in multimodal settings within constantly evolving social worlds. We explain how concepts from cognitive sciences could help AI to draw a roadmap towards human-like intelligence, with a focus on its social dimensions. As a first step, we propose to expand current research to a broader set of core social skills. To do this, we present SocialAI, a benchmark to assess the acquisition of social skills of DRL agents using multiple grid-world environments featuring other (scripted) social agents. We then study the limits of a recent SOTA DRL approach when tested on SocialAI and discuss important next steps towards proficient social agents. Videos and code are available at https://sites.google.com/view/socialai.